# 架构基础
# 集群资源评估
# 某二手电商需要构建一个Kafka集群,该集群的目标就是每天要hold住10亿请
# QPS估算
每天集群需要承载10亿数据请求,一天24小时,对于电商网站,晚上12点到凌晨8点这8个小时几乎没多少数据。 使用二八法则估计,也就是80%的数据(8亿)会在其余1 6个小时涌入,而且8亿的80%的数据(6.4亿) 会在 这1 6个小时的20%时间(3小时)涌入。 QPS计算公式=640000000+(36060)=6万,故高峰期Kafka集群需要要抗住每秒6万的并发。
# 存储估算
每天10亿数据,每个请求50kb,也就是46T的数据。如果保存2副本,462=92T, 保留最近3天的数据。故需要923=276T 注:一条消息50kb是我们公司的情况,这个值是偏大的,很多公司的- -个Kafka的请求里数据达不到50k这么大。
# QPS角度
如果资源充足,让高峰期QPS控制在集群能承载的总QPS的30%左右,故目前kafka集群能承载的总QPS为 20万~30万才是安全的,根据经验- -台物理机能支持4万QPS是没问题的,所以从QPS的角度讲,需要物理 机5-7台。
# 磁盘的数量
需要多少个磁盘?
5台物理机,需要存储276T的数据,每台存储60T的数据,- -般的配置是11块盘,一个盘7T就搞定。
# 磁盘的类型
是需要SSD固态硬盘,还是普通SAS机械硬盘? SSD就是固态硬盘,比机械硬盘要快,SSD的快主要是快在磁盘随机读写 Kafka是顺序写的,机械硬盘顺序写的性能机会跟内存读写的性能是差不多的,所以对于Kafka集群使用机 械硬盘就可以了。
# 内存角度
Kafka自身的jvm是用不了过多堆内存,因为kafka设计就是规避掉用jvm对象来保存数据,避免频繁fullgc导 致的问题,所以- -般kafka自身的jvm堆内存,分配个6G左右就够了,剩下的内存全部留给os cache。
每台服务器需要多少内存
经过梳理,公司集群大概有100个topic,这100个topic的partition的数据在os chache里效果是最好的。100个topic, 一个topic有5 个partition。那么总共会有500个partition。每个partition的Log文件大小是1G,我们有2个副本,也就是说要把1 00个topic的partition数据都驻留在内存里需要1000G的内存。我们现在有5台服务器,所以平均下来每天服务器需要200G的内存,但是其实partition的数据我们没必要所有的都要驻留在内存里面,只需要25%的数据在内存就行,200G * 0.25 = 50G就可以了。所以- -共需要56G的内存,故我们可以挑选64G内存的服务器也行,当然如果是128G内存那就更好。
# CPU角度
CPU規刻,主要是看Kafka迸程里会有多少个銭程J銭程主要是依托多核CPU来抗行的,如果銭程特別多,但是CPU核很少,就会尋致CPU奐載很高,会尋致整体工作銭程抗行的效率不太高。
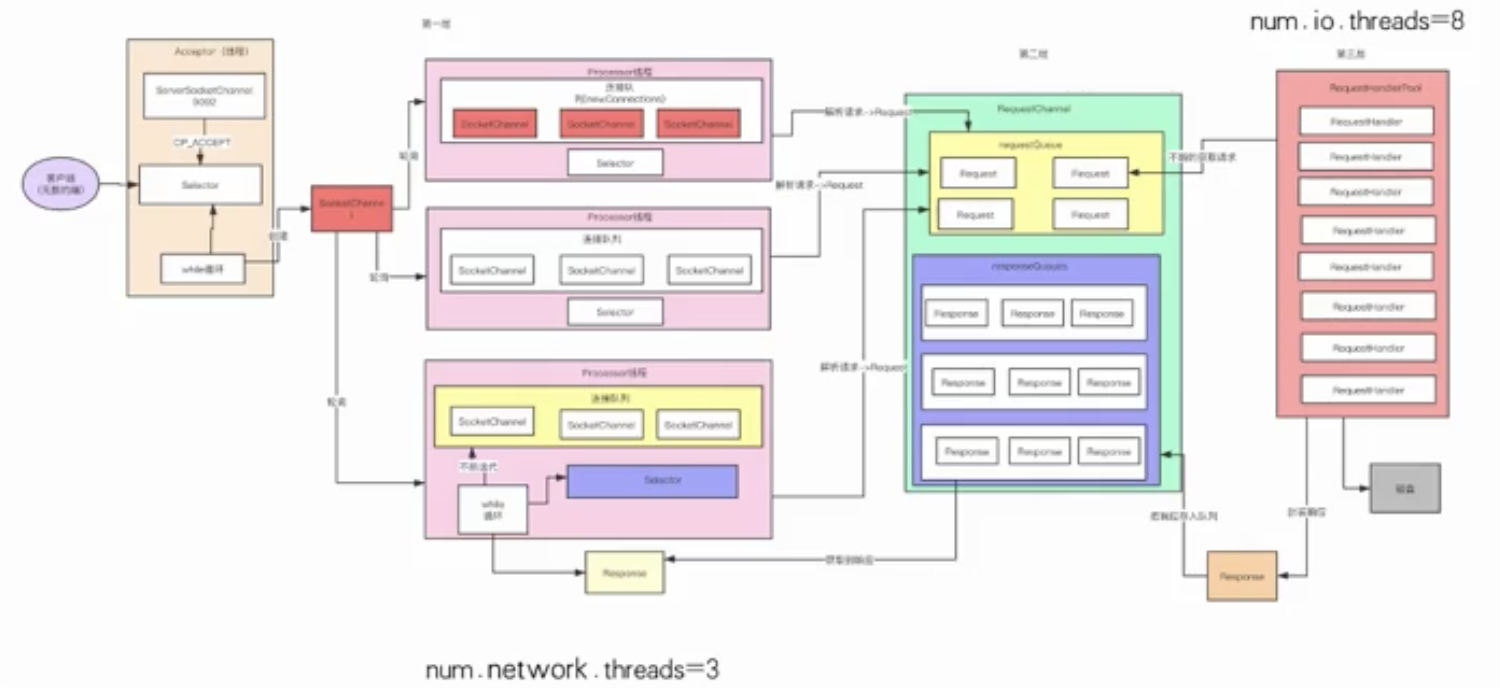
- Accept线程
- 默认的3个Process线程( -般会设置程9个)
- 默认的8RequestHandle线程(可以设置成32个)
- 清理日志的线程
- 感知Controller状态的线程
- 副本同步的线程 估算下来Kafka内部有100多个线程
4个cpu core, -般来说几十个线程,在高峰期CPU几乎都快打满了。8个cpu core,也就能够比较宽裕的支撑几十个线程繁忙的工作。所以Kafka的服务器一般是建议16核, 基本上可以hold住一两百线程的工作。当然如果可以给到32 cpu core那就最好不过了!
# 网卡角度
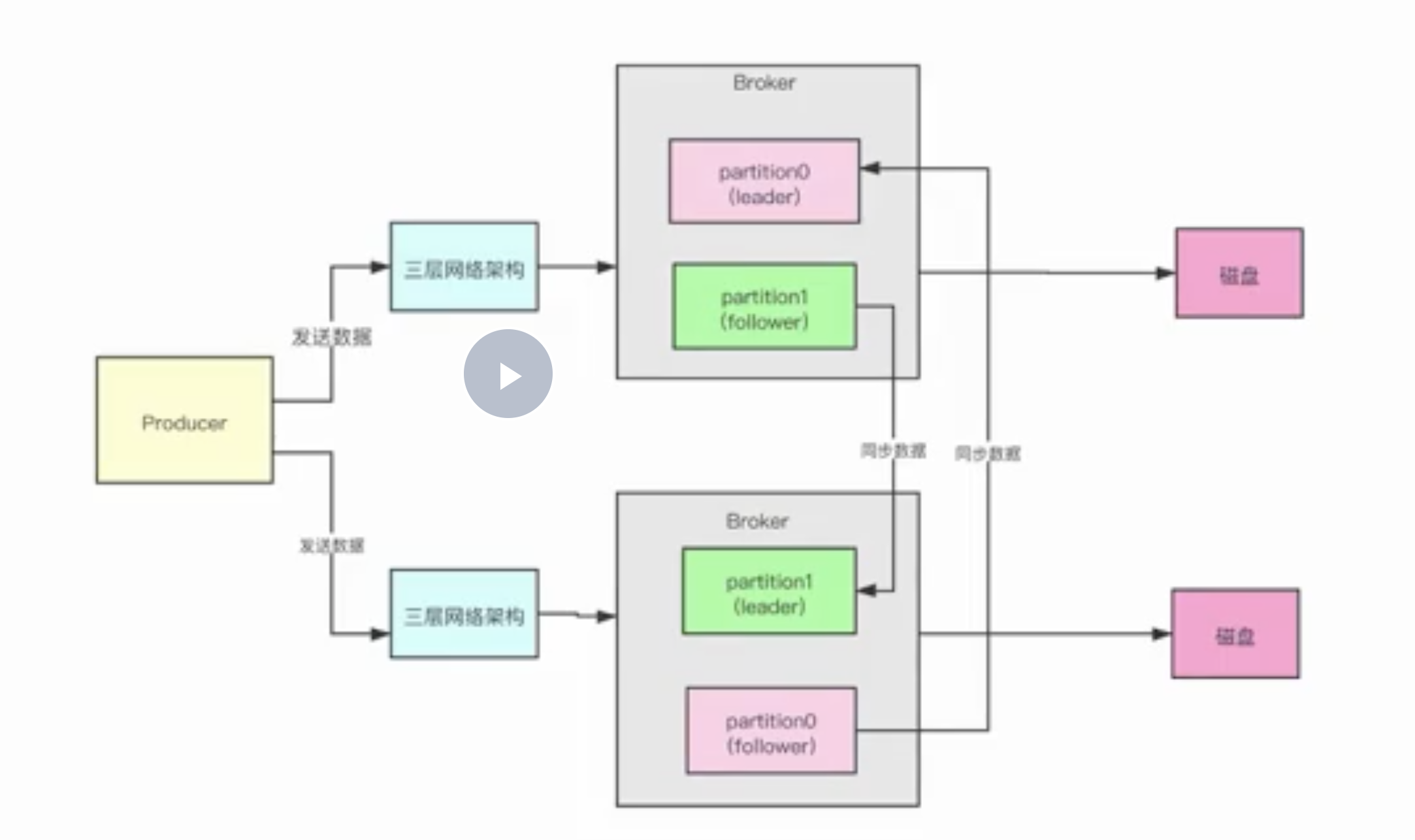
- 接受请求
- 副本同步
每秒两台broker机器之间大概会传输多大的数据量?高峰期每秒大概会涌入6万个请求,约每台处理10000个请求,每个请求50kb,故每秒约进来488M数据,我们还有副本同步数据,故高峰期的时候需要488M * 2 = 976M/s的网络带宽,所以在高峰期的时候,使用千兆带宽,网络还是非常有压力的。
# 集群资源规划
1 0亿请求,6w/s的吞吐量,276T的数据,5台物理机 硬盘: 11 (SAS) * 7T,7200转 内存: 64GB/1 28GB, JVM分配6G,剩余的给os cache CPU: 16核/32核 网络:千兆网卡,万兆更好
# 设计模式
# 谈谈你知道的设计模式?
大致按照模式的应用目标分类,设计模式可以分为创建型模式、结构型模式和行为型模式。
- 创建型模式, 是对对象创建过程的各种问题和解决方案的总结 ,包括各种工厂模式(Factory、Abstract Factory)、单例模式(Singleton)、构建器模式(Builder)、原型模式(ProtoType)。
- 结构型模式, 是针对软件设计结构的总结,关注于类、对象继承、组合方式的实践经验。 常见的结构型模式,包括桥接模式(Bridge)、适配器模式(Adapter)、装饰者模式(Decorator)、代理模式(Proxy)、组合模式(Composite)、外观模式(Facade)、享元模式(Flyweight)等。
- 行为型模式, 是从类或对象之间交互、职责划分等角度总结的模式。 比较常见的行为型模式有策略模式(Strategy)、解释器模式(Interpreter)、命令模式(Command)、观察者模式(Observer)、迭代器模式(Iterator)、模板方法模式(Template Method)、访问者模式(Visitor)
识别装饰器模式,可以通过识别类设计特征来进行判断,也就是其类构造函数以相同的抽象类或者接口为输入参数。因为装饰器模式本质上是包装同类型实例,我们对目标对象的调用,往往会通过包装类覆盖过的方法,迂回调用被包装的实例,这就可以很自然地实现增加额外逻辑的目的,也就是所谓的“装饰”。
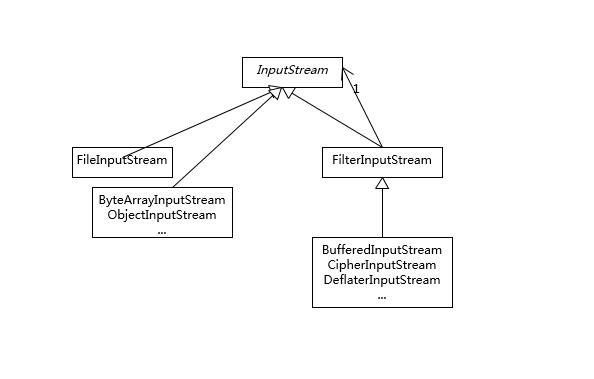
使用构建器模式,可以比较优雅地解决构建复杂对象的麻烦,这里的“复杂”是指类似需要输入的参数组合较多,如果用构造函数,我们往往需要为每一种可能的输入参数组合实现相应的构造函数,一系列复杂的构造函数会让代码阅读性和可维护性变得很差。
# CAP理论
# CAP 是什么?
学习分布式不得不会的CAP理论 - 后端 - 掘金 (opens new window)
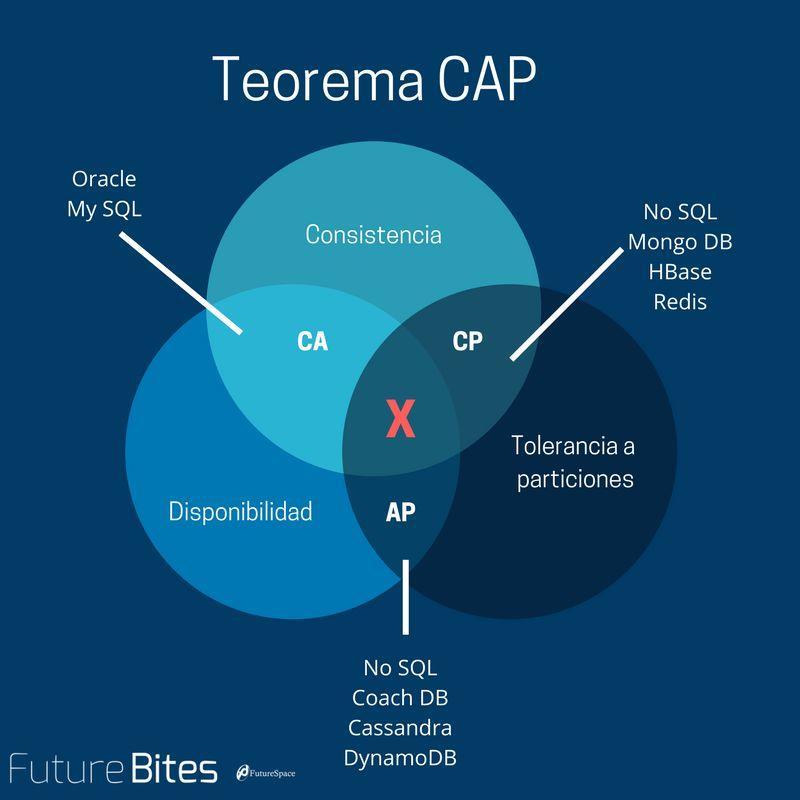

- 三种一致性策略
对于关系型数据库,要求更新过的数据能被后续的访问都能看到,这是强一致性。 如果能容忍后续的部分或者全部访问不到,则是弱一致性。 如果经过一段时间后要求能访问到更新后的数据,则是最终一致性。 CAP中说,不可能同时满足的这个一致性指的是强一致性。
Consistency 一致性 一致性指“all nodes see the same data at the same time”,即更新操作成功并返回客户端完成后,所有节点在同一时间的数据完全一致,所以,一致性,说的就是数据一致性。分布式的一致性
Availability 可用性 可用性指“Reads and writes always succeed”,即服务一直可用,而且是正常响应时间。
Partition Tolerance分区容错性 分区容错性指“the system continues to operate despite arbitrary message loss or failure of part of the system”,即分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。 简单点说,就是在网络中断,消息丢失的情况下,系统如果还能正常工作,就是有比较好的分区容错性。
# CA without P
这种情况在分布式系统中几乎是不存在的
# CP without A
如果一个分布式系统不要求强的可用性,即容许系统停机或者长时间无响应的话,就可以在CAP三者中保障CP而舍弃A。 一个保证了CP而一个舍弃了A的分布式系统,一旦发生网络故障或者消息丢失等情况,就要牺牲用户的体验,等待所有数据全部一致了之后再让用户访问系统。
如Redis、HBase、Zookeeper等
ZooKeeper是个CP(一致性+分区容错性)的,即任何时刻对ZooKeeper的访问请求能得到一致的数据结果,同时系统对网络分割具备容错性。但是它不能保证每次服务请求的可用性,也就是在极端环境下,ZooKeeper可能会丢弃一些请求,消费者程序需要重新请求才能获得结果。ZooKeeper是分布式协调服务,它的职责是保证数据在其管辖下的所有服务之间保持同步、一致。所以就不难理解为什么ZooKeeper被设计成CP而不是AP特性的了。
# AP wihtout C
要高可用并允许分区,则需放弃一致性。一旦网络问题发生,节点之间可能会失去联系。为了保证高可用,需要在用户访问时可以马上得到返回,则每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。
比如淘宝的购物,12306的买票。都是在可用性和一致性之间舍弃了一致性而选择可用性。
你在12306买票的时候肯定遇到过这种场景,当你购买的时候提示你是有票的(但是可能实际已经没票了),你也正常的去输入验证码,下单了。但是过了一会系统提示你下单失败,余票不足。这其实就是先在可用性方面保证系统可以正常的服务, 然后在数据的一致性方面做了些牺牲,会影响一些用户体验,但是也不至于造成用户流程的严重阻塞。 其实舍弃的只是强一致性。 退而求其次保证了最终一致性。也就是说,虽然下单的瞬间,关于车票的库存可能存在数据不一致的情况,但是过了一段时间,还是要保证最终一致性的。
← 架构 DT时代转型中的数据中台建设 →