# 大规模数据处理实战
# 开篇

# 01 | 为什么MapReduce会被硅谷一线公司淘汰?
# 高昂的维护成本
需要协调多个 Map 和多个 Reduce 任务。
# 时间性能“达不到”用户的期待
包括了缓冲大小 (buffer size),分片多少(number of shards),预抓取策略(prefetch),缓存大小(cache size)等等。
# 分片函数
你在处理 Facebook 的所有用户数据,你选择了按照用户的年龄作为分片函数(sharding function)
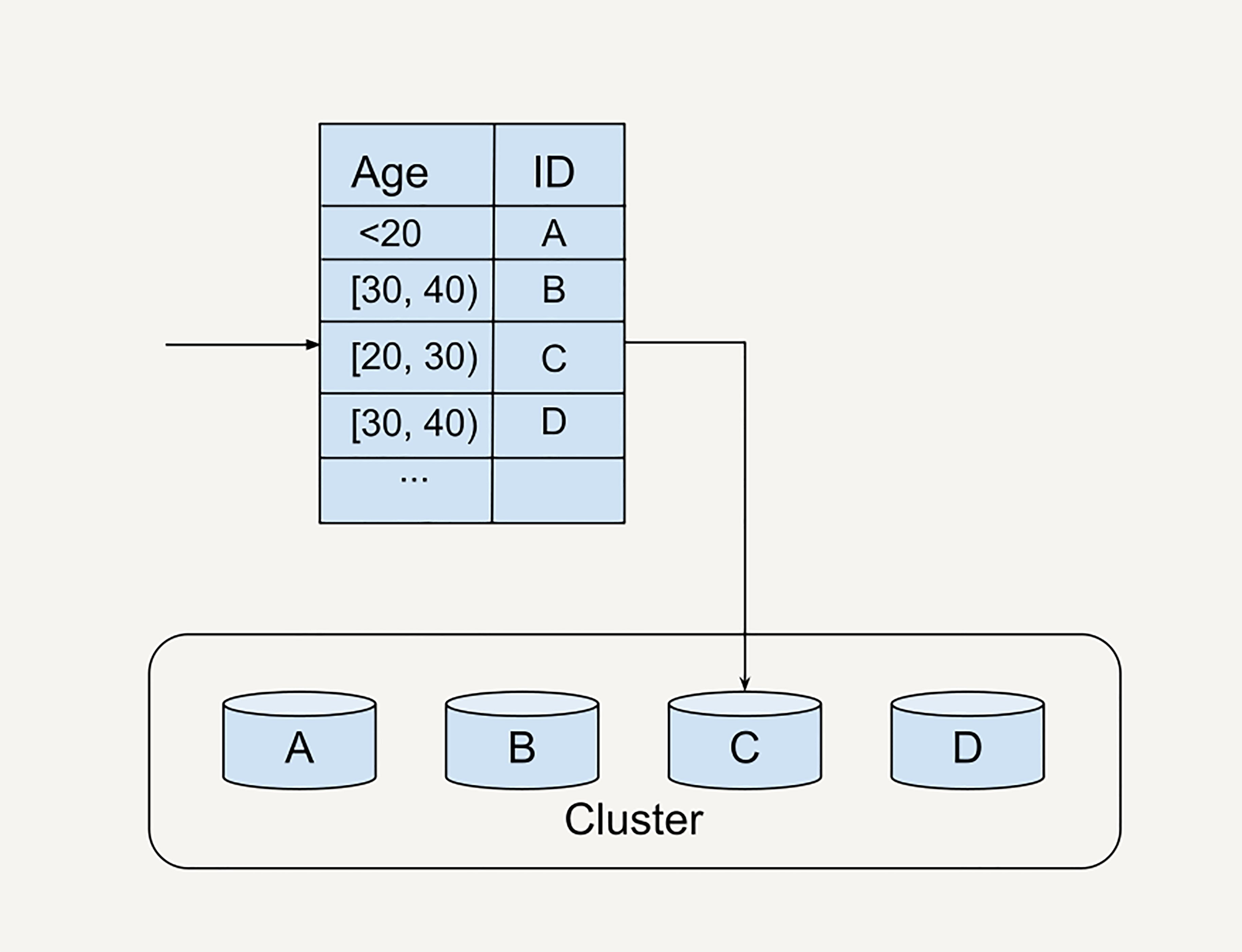
# 思考题: 如果你在 Facebook 负责处理例子中的用户数据,你会选择什么分片函数,来保证均匀分布的数据分片?
# 一致性hash-Consistent hashing
我们最早采用的是哈希算法,后来发现增删节点泰麻烦,改为带虚拟节点的一致性哈希环开处理,稍微复杂点,但是性能还好
使用Consistent hashing是可以很好地解决平均分配和当机器增减后重新hashing的问题。
# 02 | MapReduce后谁主沉浮:怎样设计下一代数据处理技术?
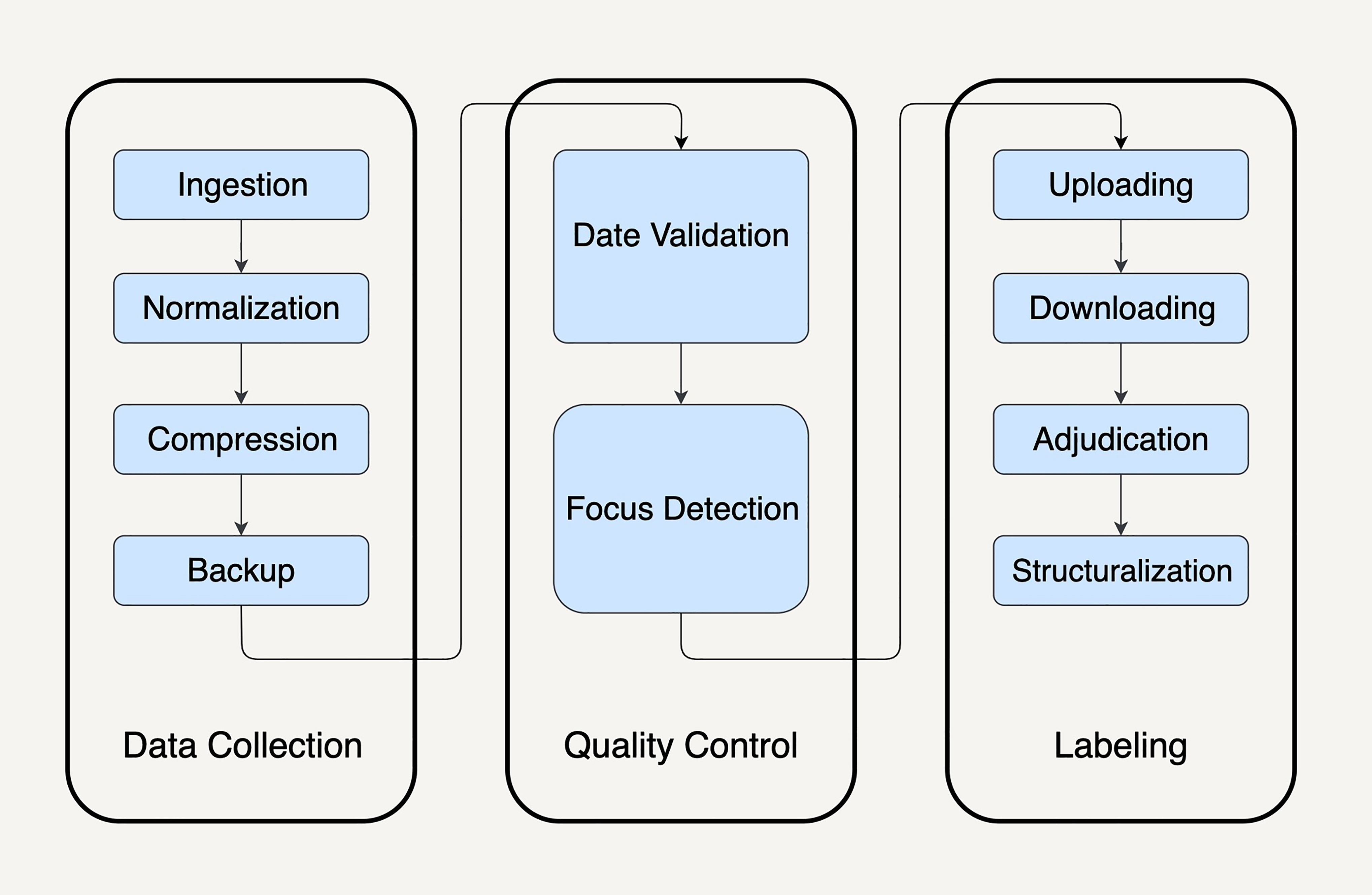
作为架构师的我们或许可以用有向无环图(DAG)来抽象表达。因为有向图能为多个步骤的数据处理依赖关系,建立很好的模型
如果我们用有向图建模,图中的每一个节点都可以被抽象地表达成一种通用的数据集,每一条边都被表达成一种通用的数据变换。如此,你就可以用数据集和数据变换描述极为宏大复杂的数据处理流程,而不会迷失在依赖关系中无法自拔
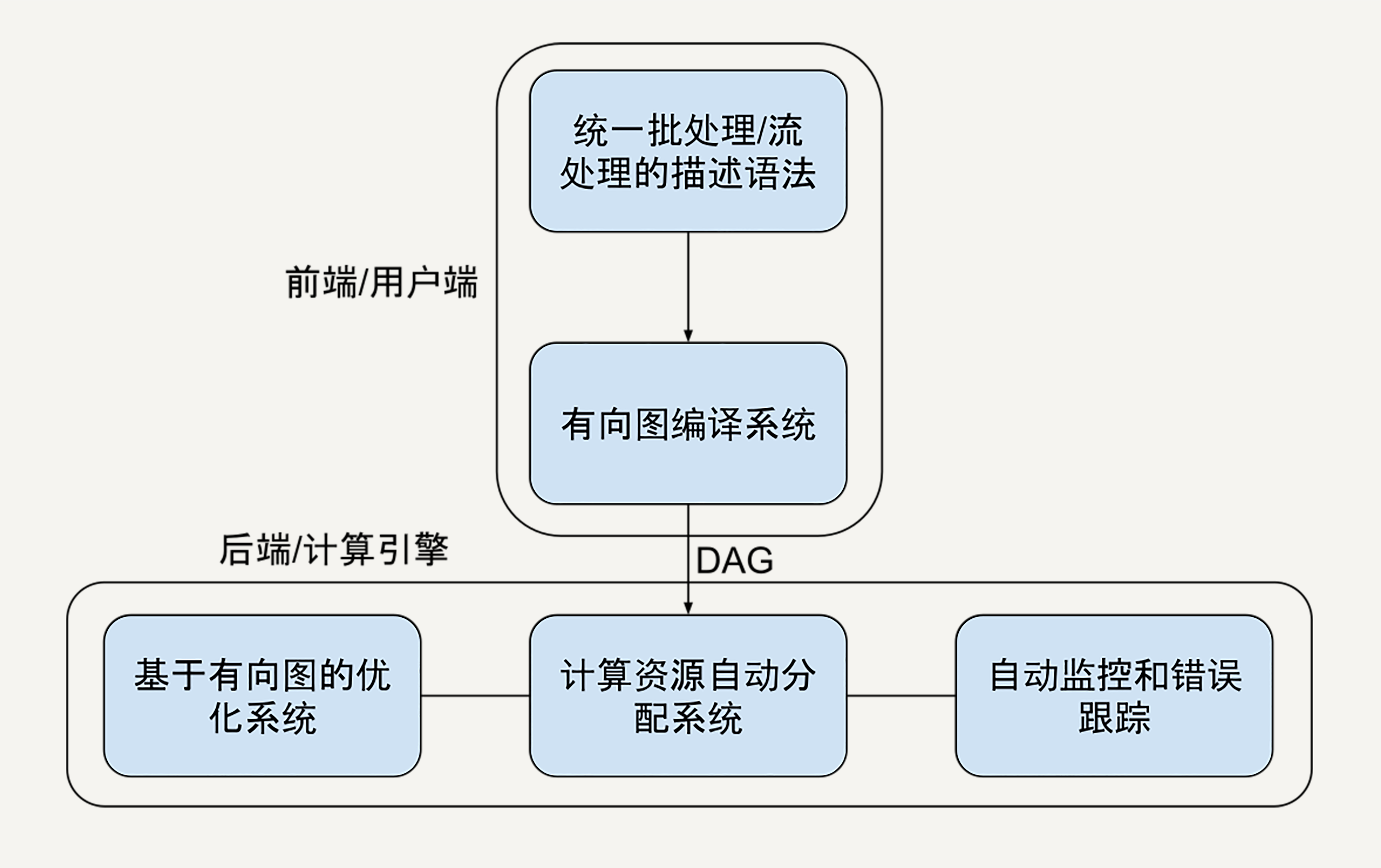
- 我们需要一种技术抽象让多步骤数据处理变得易于维护
- 有向图
- 我们不想要复杂的配置,需要能自动进行性能优化
- 自动分配
- 我们要能把数据处理的描述语言,与背后的运行引擎解耦合开来
- 用有向图进行数据处理描述的话,实际上数据处理描述语言部分完全可以和后面的运算引擎分离了。有向图可以作为数据处理描述语言和运算引擎的前后端分离协议
- 我们要统一批处理和流处理的编程模型
- 我们要在架构层面提供异常处理和数据监控的能力
# 04 | 分布式系统(上):学会用服务等级协议SLA来评估你的系统
SLA(Service-Level Agreement),也就是服务等级协议,指的是系统服务提供者(Provider)对客户(Customer)的一个服务承诺。这是衡量一个大型分布式系统是否“健康”的常见方法。
# 1. 可用性(Availabilty)
可用性指的是系统服务能正常运行所占的时间百分比。
四个 9 的可用性(99.99% Availability,或每年约 50 分钟的系统中断时间)即可以被认为是高可用性(High availability)。
# 2. 准确性(Accuracy)
准确性指的是我们所设计的系统服务中,是否允许某些数据是不准确的或者是丢失了的
很多时候,系统架构会以错误率(Error Rate)来定义这一项 SLA。

我们可以用错误率来定义准确性,但具体该如何评估系统的准确性呢?一般来说,我们可以采用性能测试(Performance Test)或者是查看系统日志(Log)两种方法来评估。
# 3.系统容量(Capacity)
系统容量通常指的是系统能够支持的预期负载量是多少,一般会以每秒的请求数为单位来表示。
方式
第一种,是使用限流(Throttling)的方式。
第二种,是在系统交付前进行性能测试(Performance Test)。
第三种,是分析系统在实际使用时产生的日志(Log)。
不一定是最大的,一般使用性能测试和查看日志相结合的手段
# 4. 延迟(Latency)
延迟指的是系统在收到用户的请求到响应这个请求之间的时间间隔。
P95 P99 p指的是 percentile