# 解决方案
# 数据架构方案
# 贝壳基于Druid的OLAP引擎应用实践
贝壳基于Druid的OLAP引擎应用实践 (opens new window)
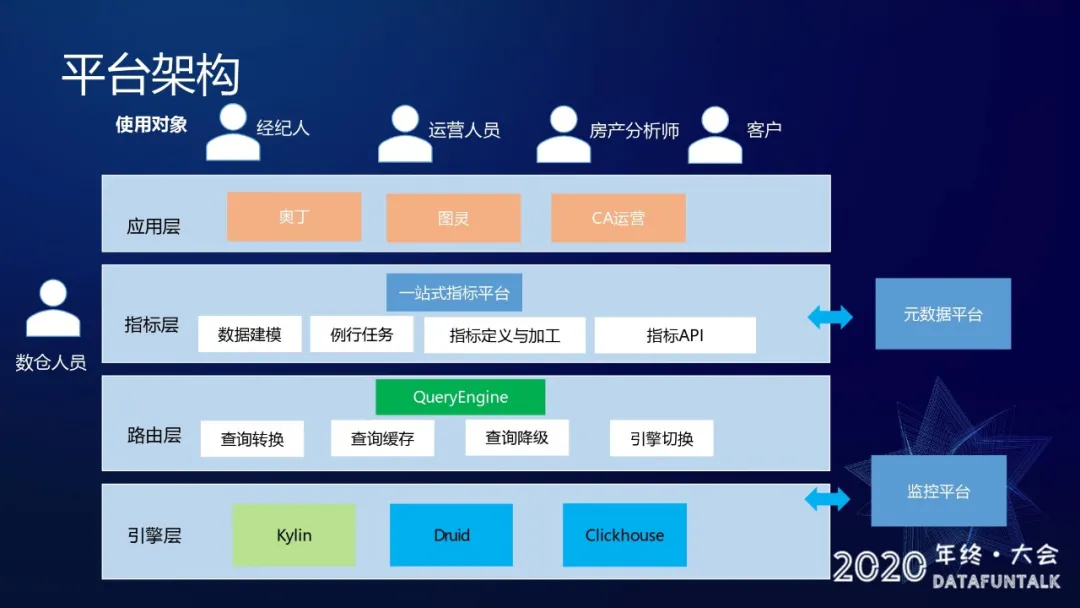
# 架构
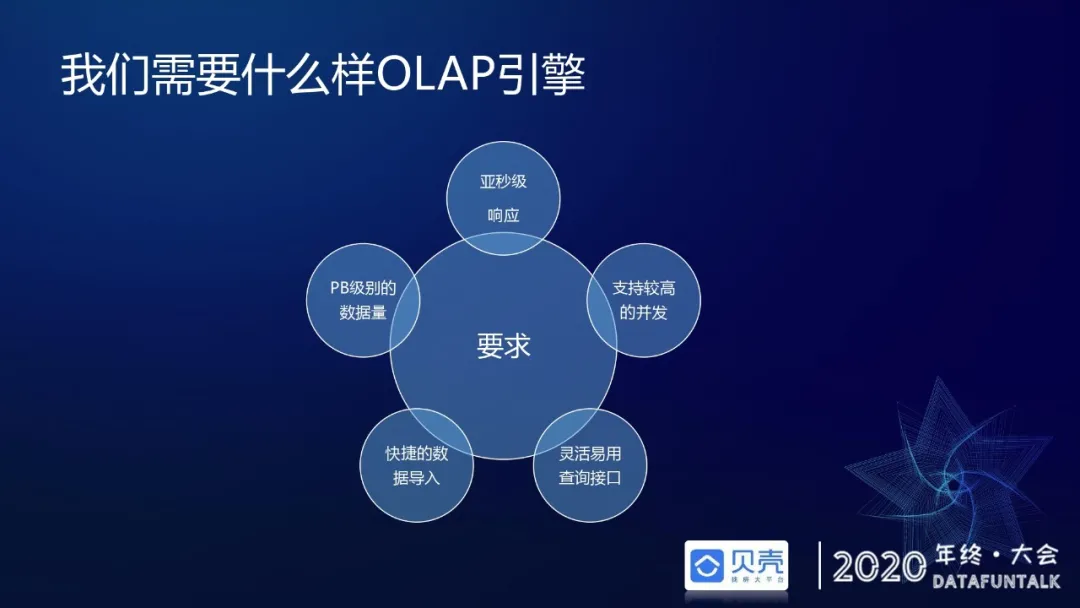
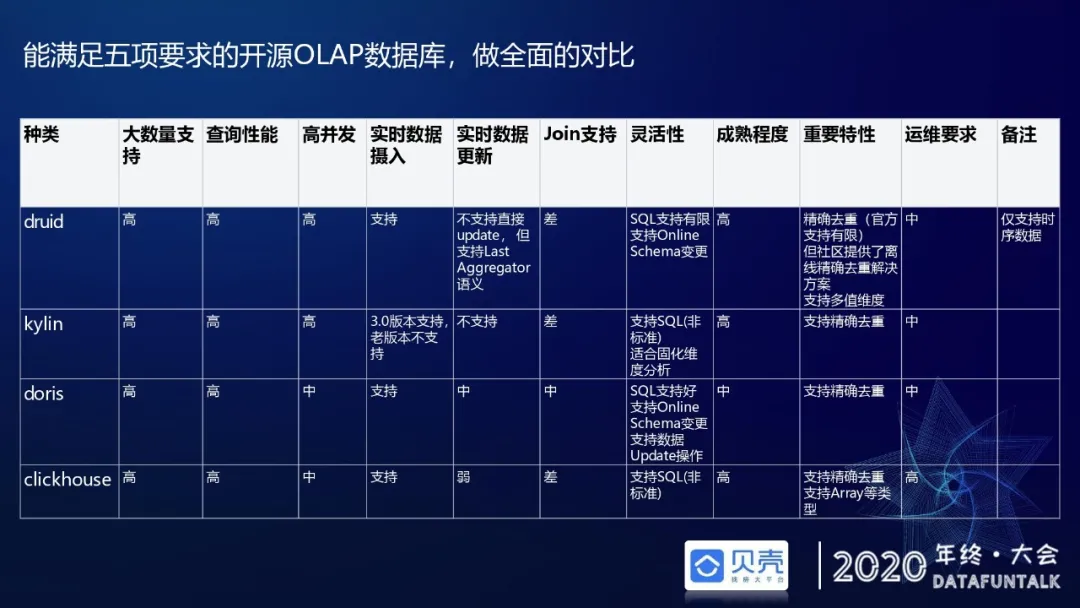
# Druid替换kylin原因

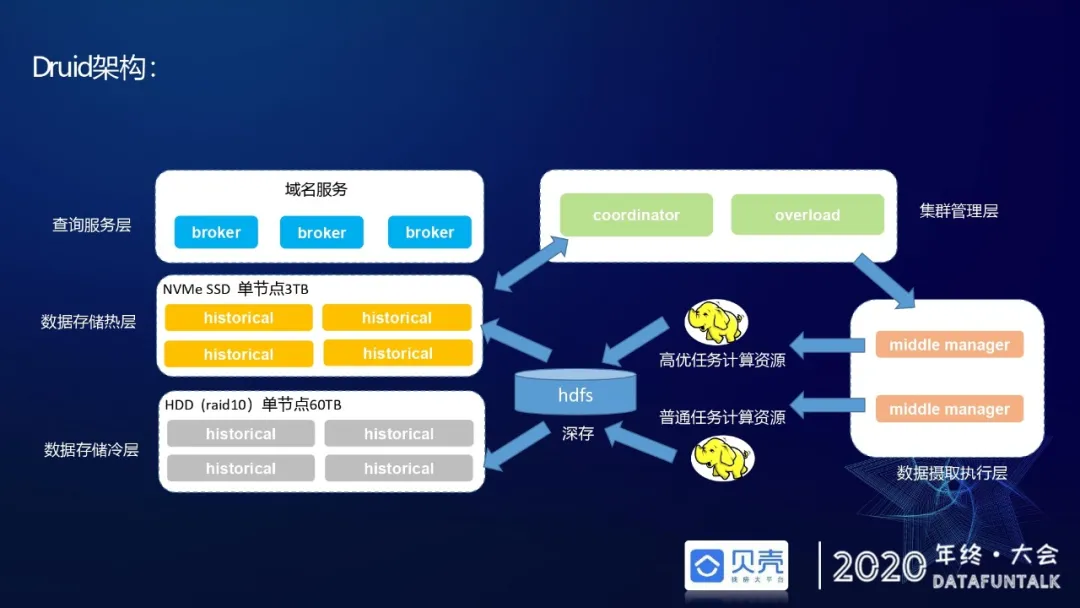
# Druid架构
# 大数据量漏斗查询
每天数百亿用户行为数据,美团点评怎么实现秒级转化分析? - 美团技术团队 (opens new window)
# Impala + Kudu
Kudu+Impala为实时数据仓库存储提供了良好的解决方案。这套架构在支持随机读写的同时还能保持良好的Scan性能,同时其对Spark等流式计算框架有官方的客户端支持。这些特性意味着数据可以从Spark实时计算中实时的写入Kudu,上层的Impala提供BI分析SQL查询,对于数据挖掘和算法等需求可以在Spark迭代计算框架上直接操作Kudu底层数据。
使用Apache Kudu和Impala实现存储分层 - 大鹏的个人空间 - OSCHINA - 中文开源技术交流社区 (opens new window)
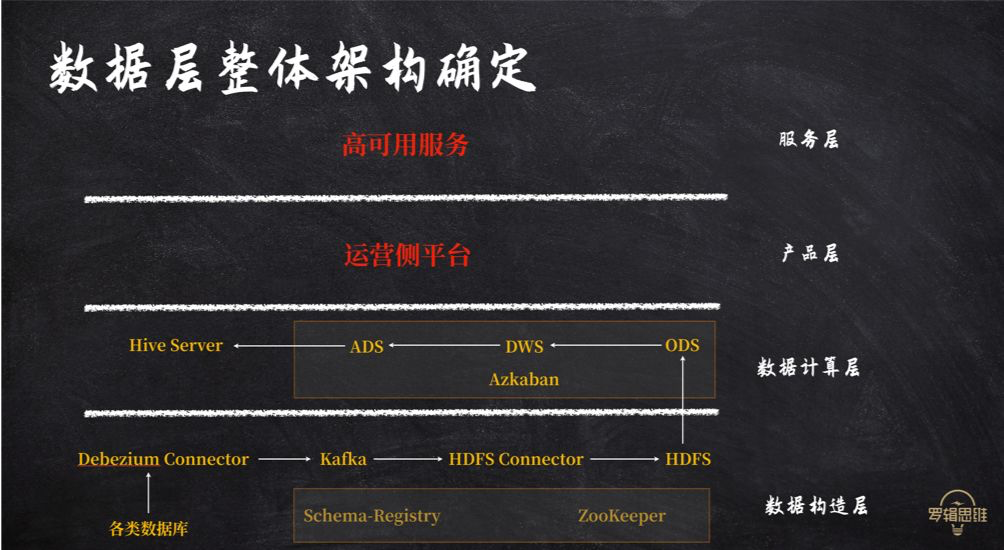
# 得到的实时大数据运营设计
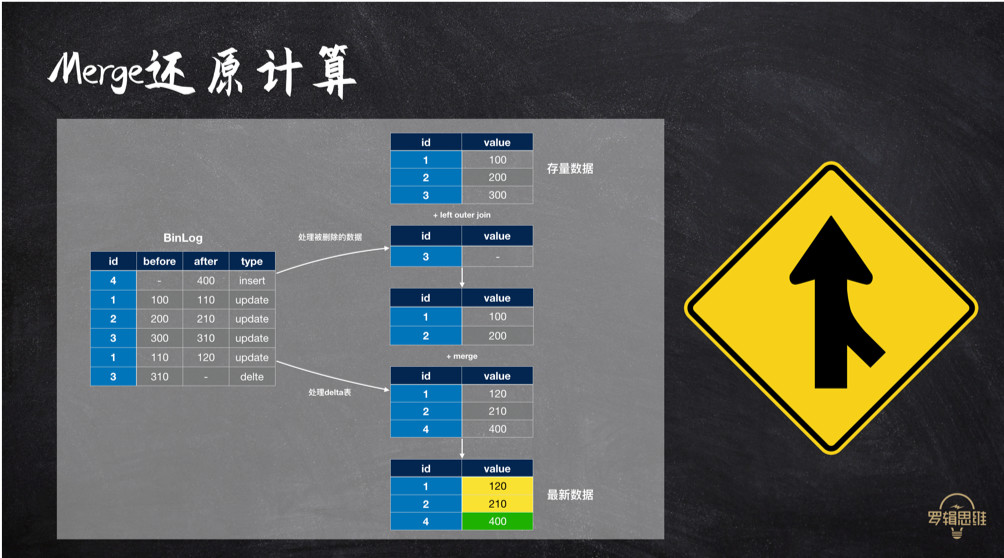
# Merge流程
- 首先对Binlog按 主键+事件类型 group by,取出delete 事件与存量数据进行left outer join,这样就从存量数据中剔除了删除数据;
- 对剩余Binlog数据进行二次筛选,按主键 group by 取最新的Binlog,无论是insert或是update;
- 将步骤2中生成的数据与存量数据合并,生成最新数据。如图中的黄色的1、2是受Binlog的update重放影响的,绿色的4是insert新增的。
# 数据同步
# Flink + Canal 增量同步
基于Canal与Flink实现数据实时增量同步(二) | Jmx's Blog (opens new window)
# Mysql数据同步到数据仓库
美团DB数据同步到数据仓库的架构与实践 - 美团技术团队 (opens new window)
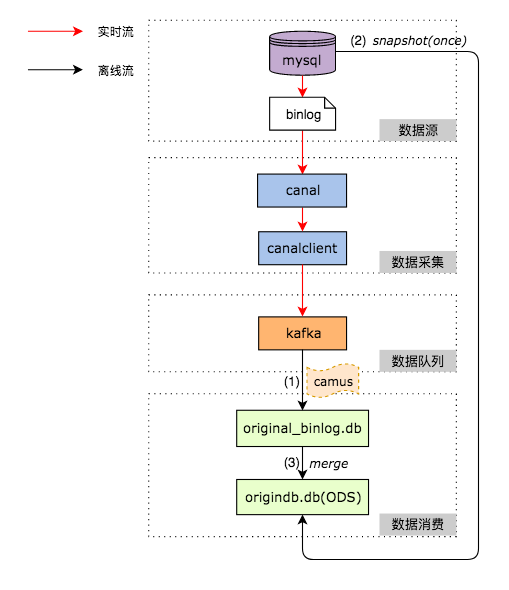
Apache Flink 中文用户邮件列表 - flink mysql cdc + hive streaming疑问 (opens new window)
canal初体验 - 同步binlog到hive | 鱼儿的博客 (opens new window)
1. 增量同步
2. 使用hive进行合并 rownum over