# 深度揭秘世界级分布式文件系统 HDFS 架构设计
奈学教育
# Hadoop简介
Hadoop到目前为止发展已经有10余年,版本经过了无数次的更新迭代,目前业内大家把Hadoop大的 版本分为Hadoop1, hadoop2,Hadoop3三个版本。
# Hadoop1简介
Hadoop1版本刚出来的时候是为了解决两个问题: -个是海量数据如何存储的问题,-个是海量数据 如何计算的问题。Hadoop1的核心设计就是HDFS和Mapreduce。HDFS解决了海量数据如何存储的问题,Mapreduce解决了海量数据如何计算的问题。 HDFS的全称: Hadoop Distributed File System
# 演进
# HDFS1架构
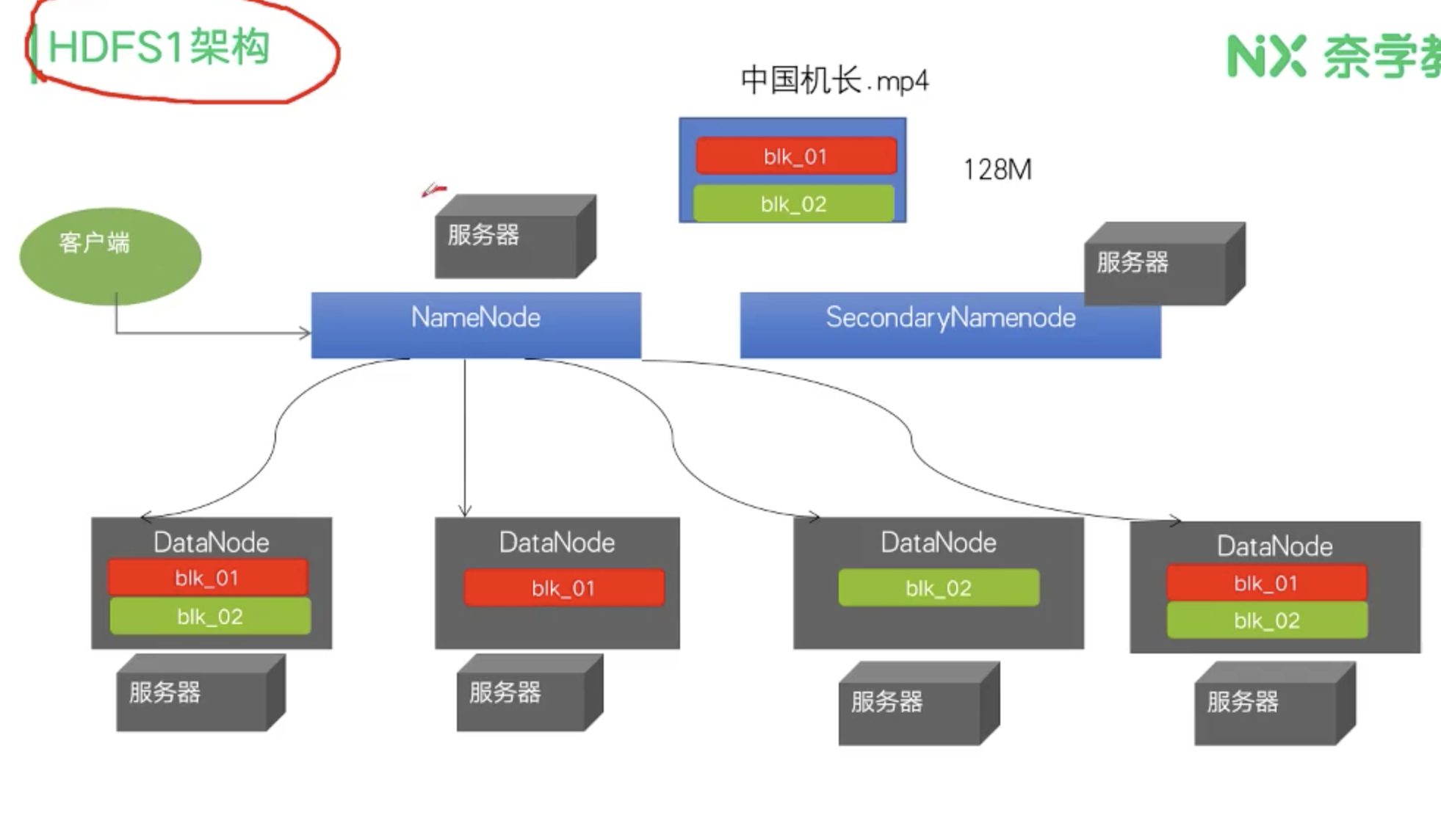
HDFS1架构 HDFS1是-一个主从式的架构,主节点只有一个叫NameNode。 从节点有多个叫DataNode
NameNode 1)管理元数据信息(文件目录树):文件与Block块,Block块与DataNode主机的关系 2) NameNode为了快速响应用户的操作请求,所以把元数据加载到了内存里面
DataNode 1)存储数据,把上传的数据划分成为固定大小的文件块(Hadoop1, 默认是64M) 2)为了保证数据安全,每个文件块默认都有三个副本
# HDFS1缺陷
单点故障问题
内存 受限问题
# HDFS2架构设计
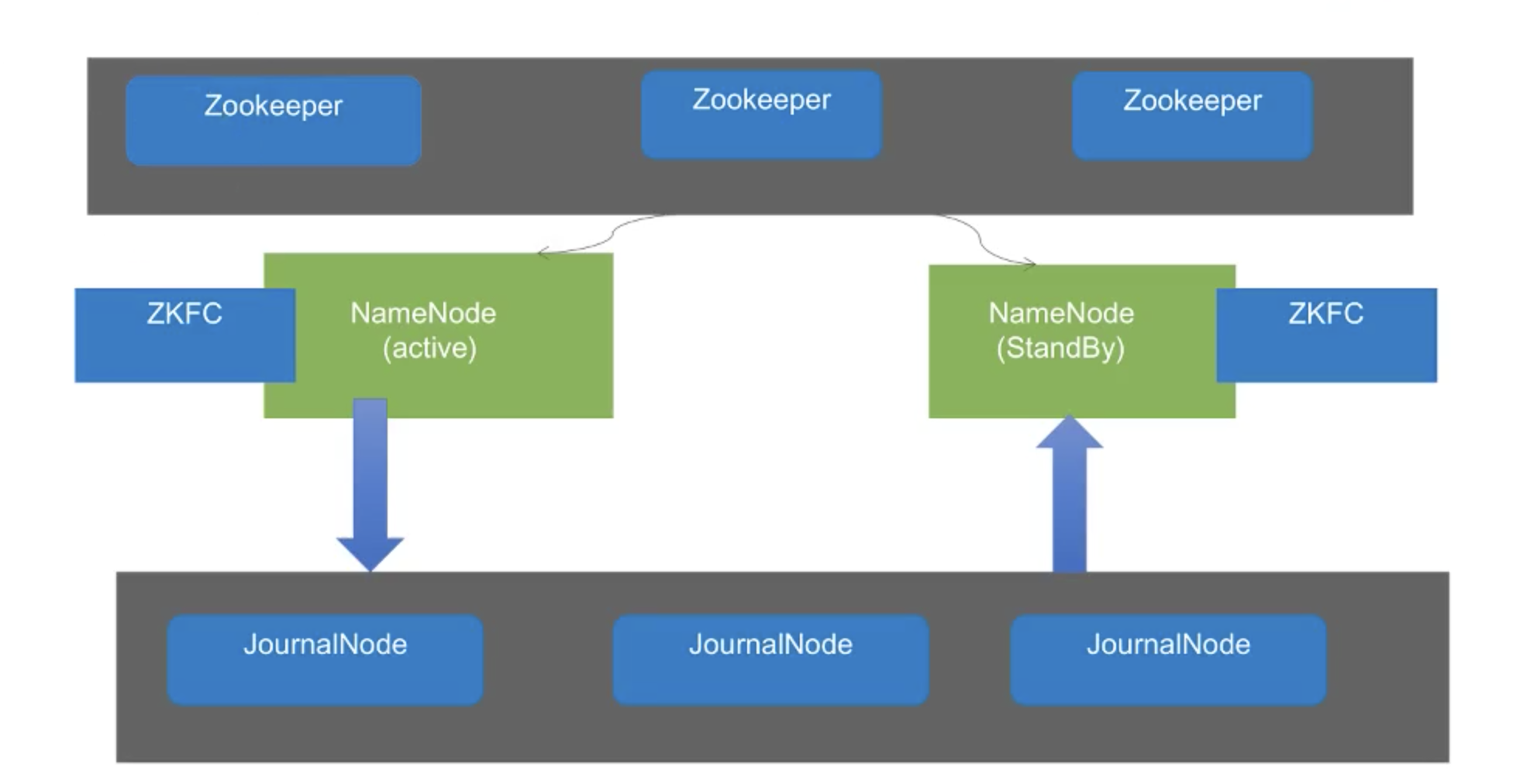
HA方案( High Available) 解决HDFS1 Namenode单点故障问题 联邦方案. 解决了HDFS1内存受限问题
# HDFS3架构设计
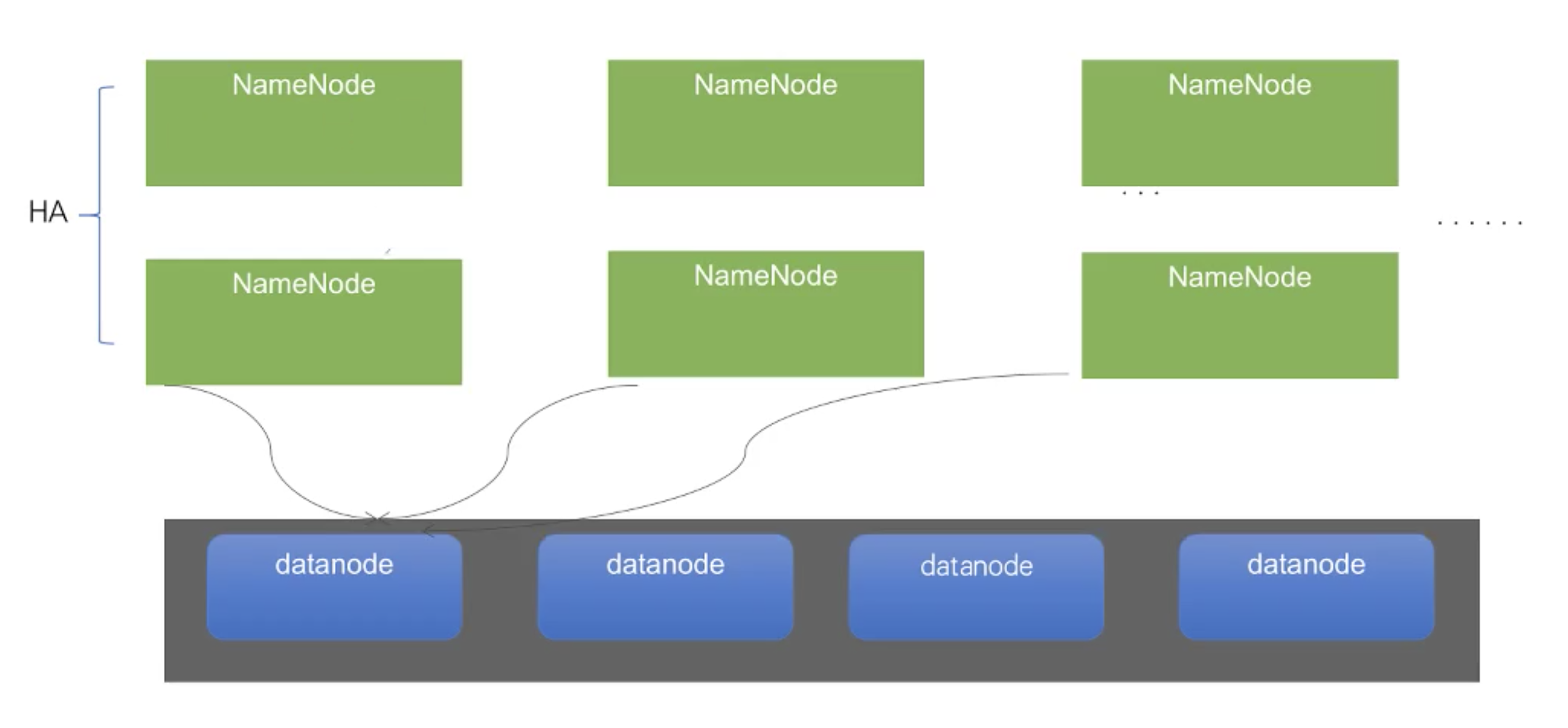
HA方案支持多个Namenode
hdfs2只能支持两个NN
引入纠删码技术
存三个副本,很浪费资源
# HDFS支持亿级流量的秘密
思考:
因为NameNode管理了元数据,用户所有的操作请求都要操作Namenode,大一-点的平台一 天需要运行几十万, 上百万的任务。一个任务就会有很多个请求,这些所有的请求都打到NameNode这儿(更新目录树),对于 Namenode来说这就是亿级的流量,Namenode是 如何支撑亿级流量的呢?
# HDFS如何管理元数据
# 数据同步共享问题
大数据笔记 HDFS - 知乎 (opens new window)
HDFS HA Using QJM原理解析 - Hexiaoqiao (opens new window)
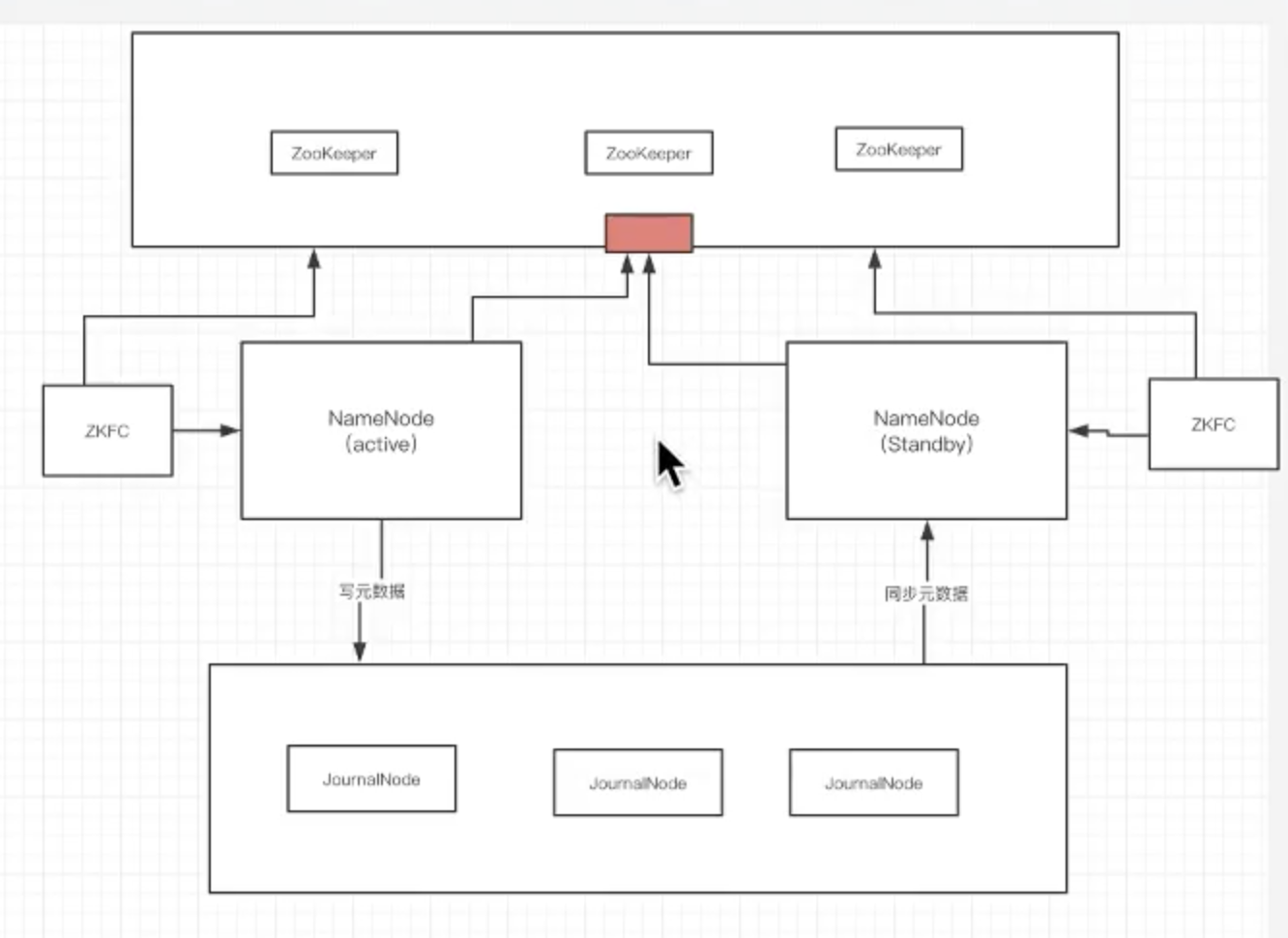
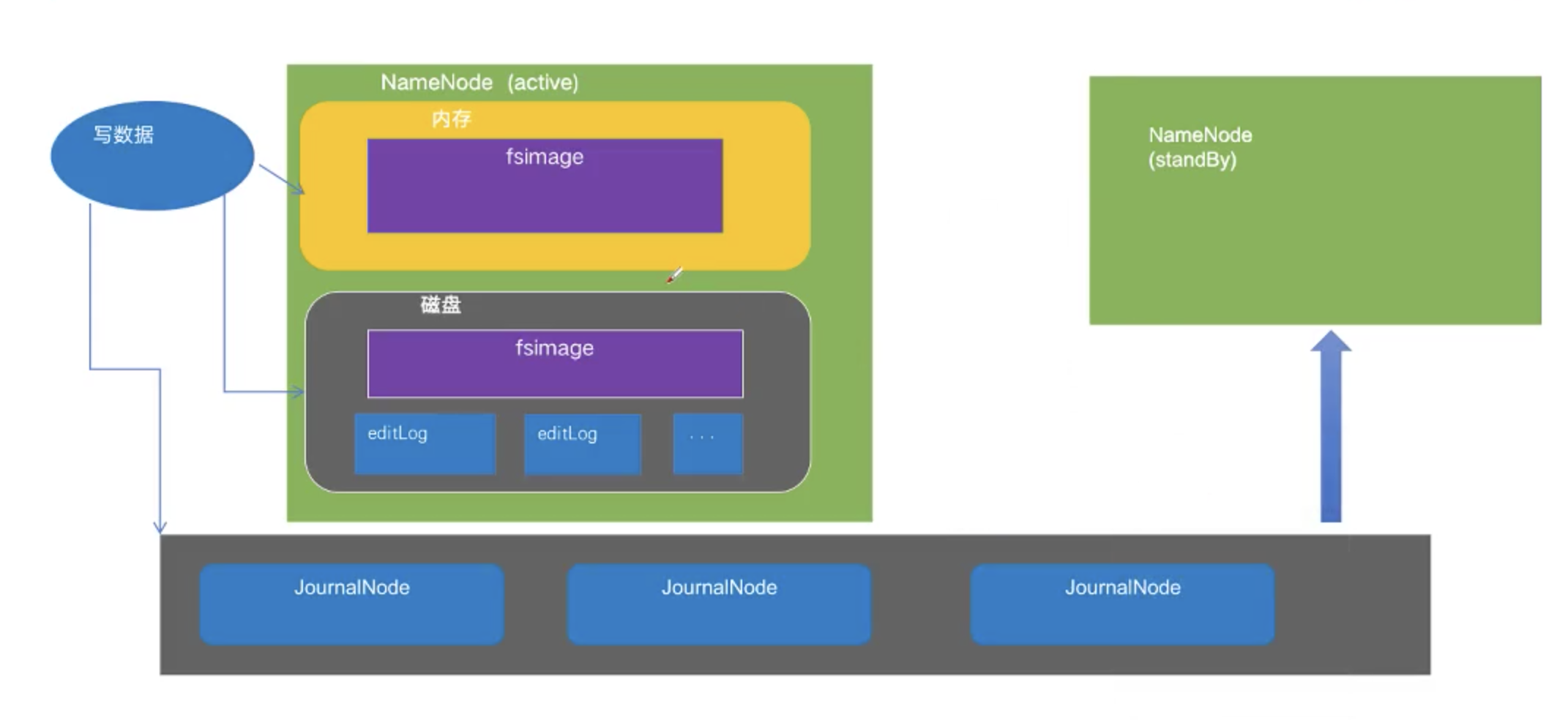
- 共享存储系统是实现 NameNode 的高可用最为关键的部分,共享存储系统保存了 NameNode 在运行过程中所产生的 HDFS 的元数据。Active NameNode 和 Standby NameNode 通过共享存储系统实现元数据同步。在进行主备切换的时候,新的主 NameNode 在确认元数据完全同步之后才能继续对外提供服务。
- 基于 QJM 的共享存储系统主要用于保存 EditLog,并不保存 FSImage 文件。FSImage 文件还是在 NameNode 的本地磁盘上。QJM 共享存储的基本思想来自于 Paxos 算法,采用多个称为 JournalNode 的节点组成的 JournalNode 集群来存储 EditLog。每个 JournalNode 保存同样的 EditLog 副本。每次 NameNode 写 EditLog 的时候,除了向本地磁盘写入 EditLog 之外,也会并行地向 JournalNode 集群之中的每一个 JournalNode 发送写请求,只要大多数 (majority) 的 JournalNode 节点返回成功就认为向 JournalNode 集群写入 EditLog 成功。如果有 2N+1 台 JournalNode,那么根据大多数的原则,最多可以容忍有 N 台 JournalNode 节点挂掉。
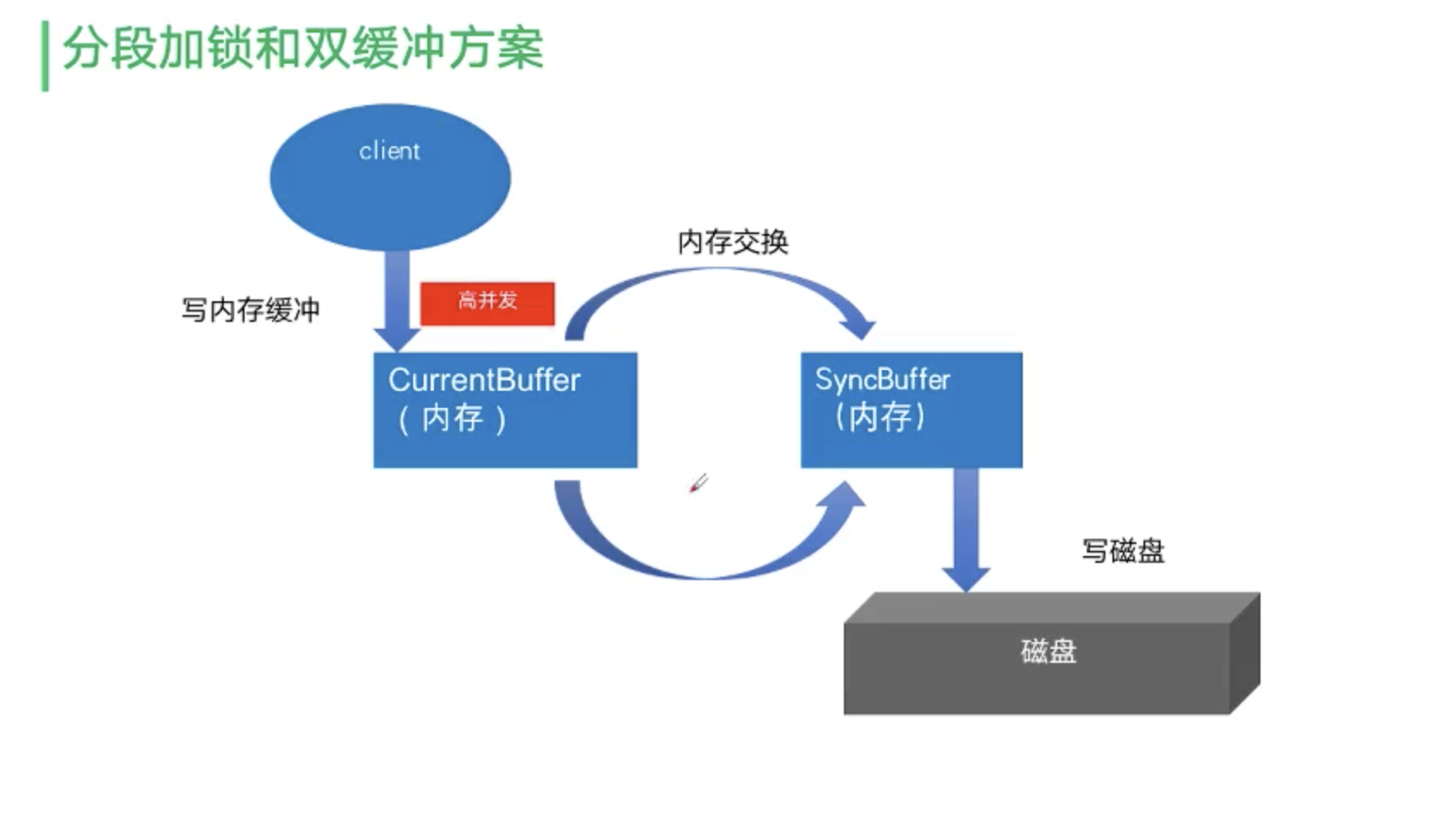
此方案,一边写内存,一边写磁盘,肯定是扛不住亿流量的,磁盘很慢,怎么解决的呢?