# Impala
# impala 特点
Kudu+Impala介绍 | 微店数据科学团队博客 (opens new window)
- Impala作为老牌的SQL解析引擎,其面对即席查询(Ad-Hoc Query)类请求的稳定性和速度在工业界得到过广泛的验证
- 没有存储,负责解析sql
- 定位类似hive,关注即席查询sql快速解析
- 长sql还是hive更合适
- group by sql 使用内存计算,建议内存128G以上 Hhttps://zhuanlan.zhihu.com/p/65593795ive使用MR,效率低,稳定性好
- 不支持高并发,由于单个sql执行代价较高
- 不能代替hive
- 至少需要128G以上内存,并且把80%分配给Impala
- 不会对表数据Cache,仅仅缓存一些表数据等元数据
- 可以使用 hive metastore Hive 是必选组件
# Impala为什么会这么快?
为速度而生,执行效率优化,非MR模型,MR sql转换为MR原语,需要多层迭代,造成极大浪费
- impala尽可能把数据缓存在内存中,数据不落地就能完成sql查询
- 常驻进程,避免MR启动开销
- 专为SQL设计,减少迭代次数,避免不必要shuffle和sort
- 利用现代化高性能服务器
- LLVM 生产动态代码
- 协调控制磁盘io,控制吞吐,吞吐量最大化
- 代码效率曾采用C++,提速
- 程序内存使用上,利用C++天然优势,遵循极少内存使用原则
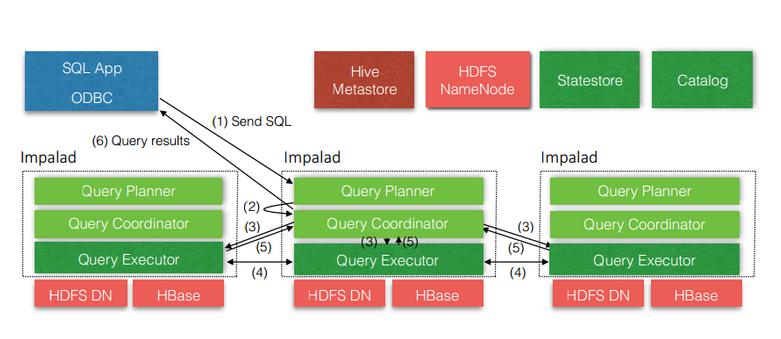
# Impala 查询流程
大数据时代快速SQL引擎-Impala (opens new window)
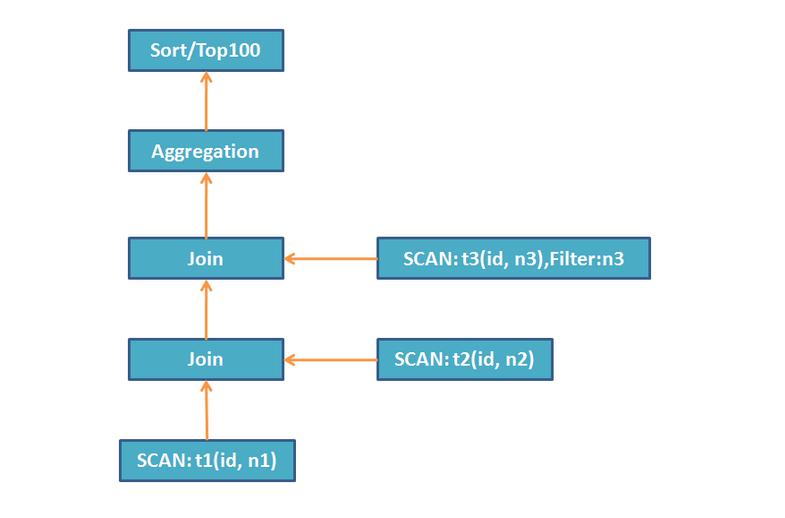
下图展示了执行select t1.n1, t2.n2, count(1) as c from t1 join t2 on t1.id = t2.id join t3 on t1.id = t3.id where t3.n3 between ‘a’ and ‘f’ group by t1.n1, t2.n2 order by c desc limit 100;查询的执行逻辑,首先Query Planner生成单机的物理执行计划,如下图所示:
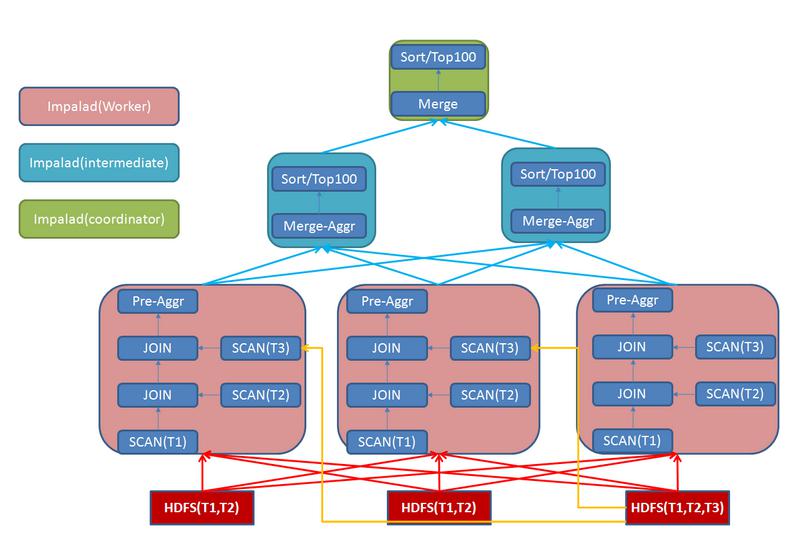
# Impala的部署方式
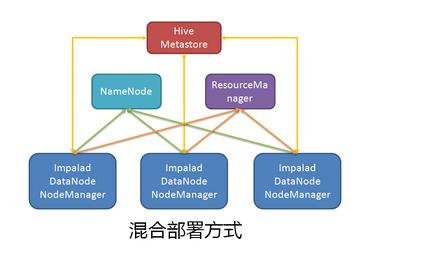
# 混合部署
混合部署意味着将Impala集群部署在Hadoop集群之上,共享整个Hadoop集群的资源, 前者的优势是Impala可以和Hadoop集群共享数据,不需要进行数据的拷贝,但是存在Impala和Hadoop集群抢占资源的情况,进而可能影响Impala的查询性能
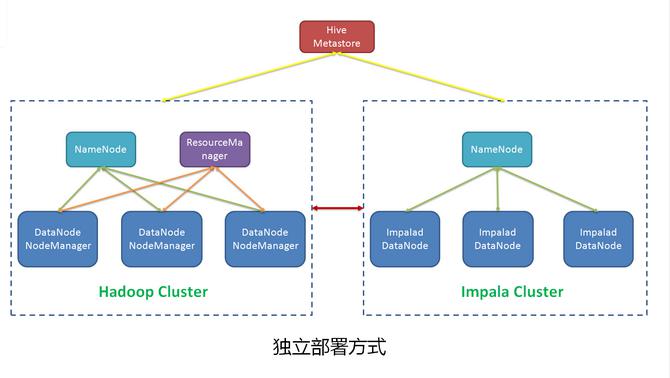
# 独立部署
独立部署则是单独使用部分机器只部署HDFS和Impala 而后者可以提供稳定的高性能,但是需要持续的从Hadoop集群拷贝数据到Impala集群上,增加了ETL的复杂度
# impala和hive的关系
impala是基于Hive的大数据实时分析查询引擎,直接使用Hive的元数据库Metadata,意味着impala元数据都存储在Hive的metastore中。并且impala兼容Hive的sql解析,实现了Hive的SQL语义的子集,功能还在不断完善中。
直接选用impala代替hive,是因为impala快
- 基于内存计算,能够对PB级数据进行交互式实时查询、分析。
- 摒弃了MR计算改用C++编写,有针对性的硬件优化,例如使用SSE指令。
- 兼容HiveSQL,无缝迁移。
- 通过使用LLVM来统一编译运行时代码,避免为了支持通用编译而带来的不必要的开销。
- 支持sql92标准,并且有自己的解析器和优化器。
- 具有数据仓库的特性,对hive原有数据做数据分析。
- 使用了支持Data locality的/O调度机制。
- 支持列式存储。
- 支持jdbc/odbc远程访问。
执行机制 hive: hive sql–>mr—>yarn—>hdfs 最大的弊端在于mr执行中资源申请消耗数据之间的shuffle。尤其涉及多个mr程序串联 影响会放大
impala:impala sql-->执行计划数-->hdfs语言层面 hive:java 依赖于jvm 涉及启动销毁 属于偏上层语言。 impala: C++ 偏向于底层语言 可以更好的调用系统资源
数据流 hive :推的方式 前述节点计算完毕数据退给后续节点计算 impala:拉的方式 不断调用获取前述节点的计算结果 边拉边计算
内存 hive优先使用内存 如果不足 使用外存(磁盘) impala当下只用内存 内存不足报错 通常去配合hive使用。
调度 hive 资源调度是用yarn完成 impala 自己调度 策略极其简单
容错 hive容错准备来说就是hadoop容错机制 task重试机制 推测执行机制 impala没有容错能力 设计的时候认为 错了再来也会很快 再执行的成本低
适用层面 hive适用于复杂的批处理任务分析 impala适用于交互式实时任务处理 通常要hive使用
# Impala不足
- 基于内存进行计算,对内存依赖性较大
- 改用C++编写,以为着对C++普通用户不可见。
- 基于Hive,与Hive共存亡。
- 实践中impala的分区超过一万,性能严重下降,容易出现问题。
- 稳定性不如Hive