# Kylin
# kylin 概述
Hadoop平台上的开源OLAP引擎,多维立方体预计算技术,将sql提升到亚秒级别

空间换时间,线性增加的资源需求到线性降低的查询时间
# kylin的构建原理
Apache Kylin Cube 构建原理
Apache Kylin On Druid Storage 原理与实践
Kylin构建Cube过程详解
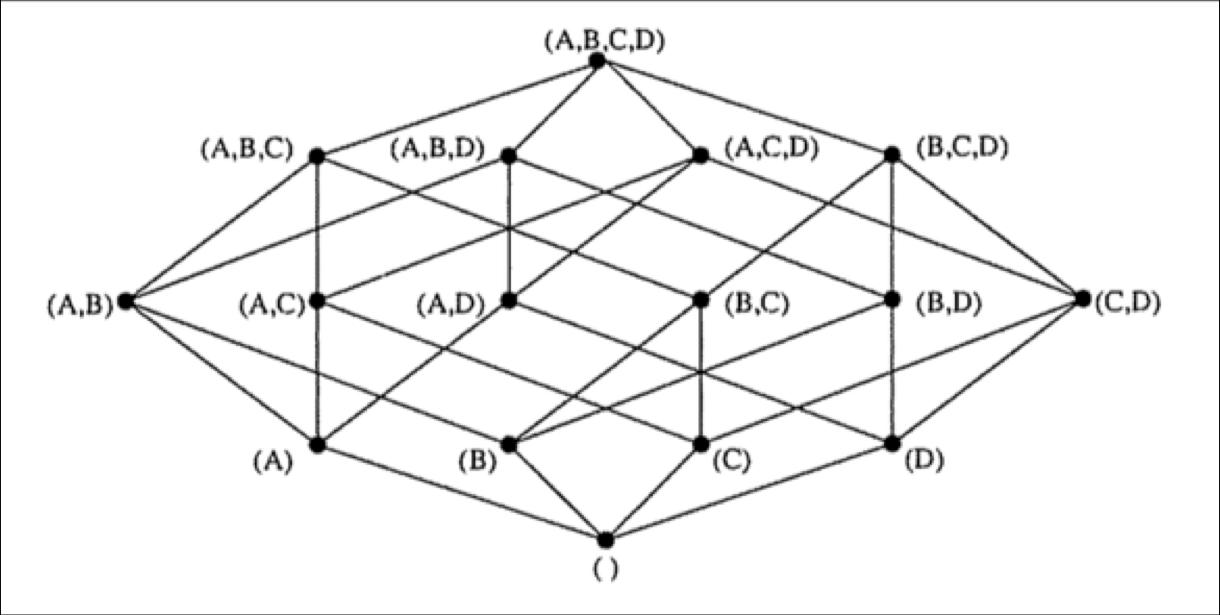
理念:空间换时间
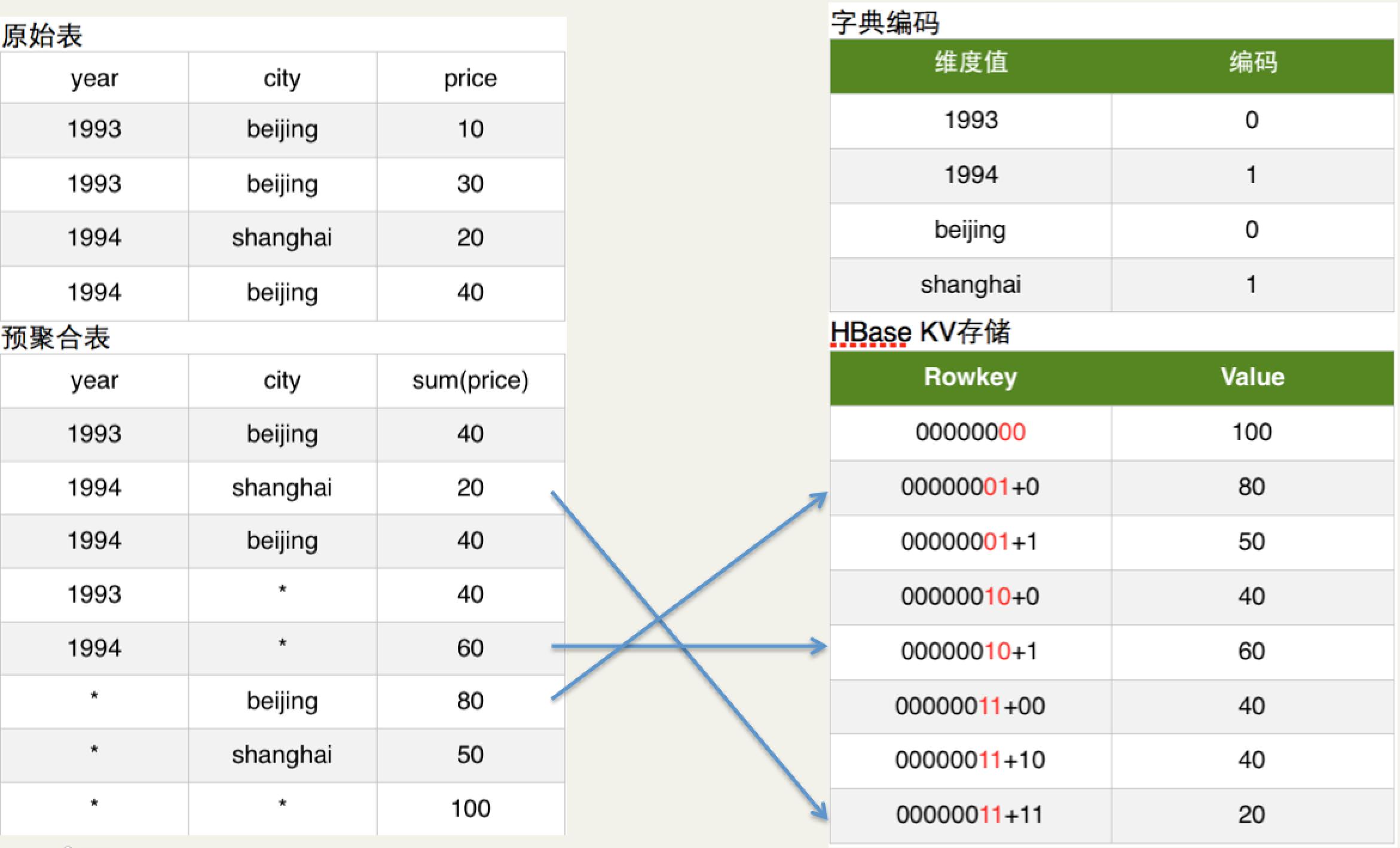
HTable对应的RowKey,就是各种维度组合,指标存在Column中
将不同维度组合查询SQL,转换成基于RowKey的范围扫描,然后对指标进行汇总计算,以实现快速分析查询
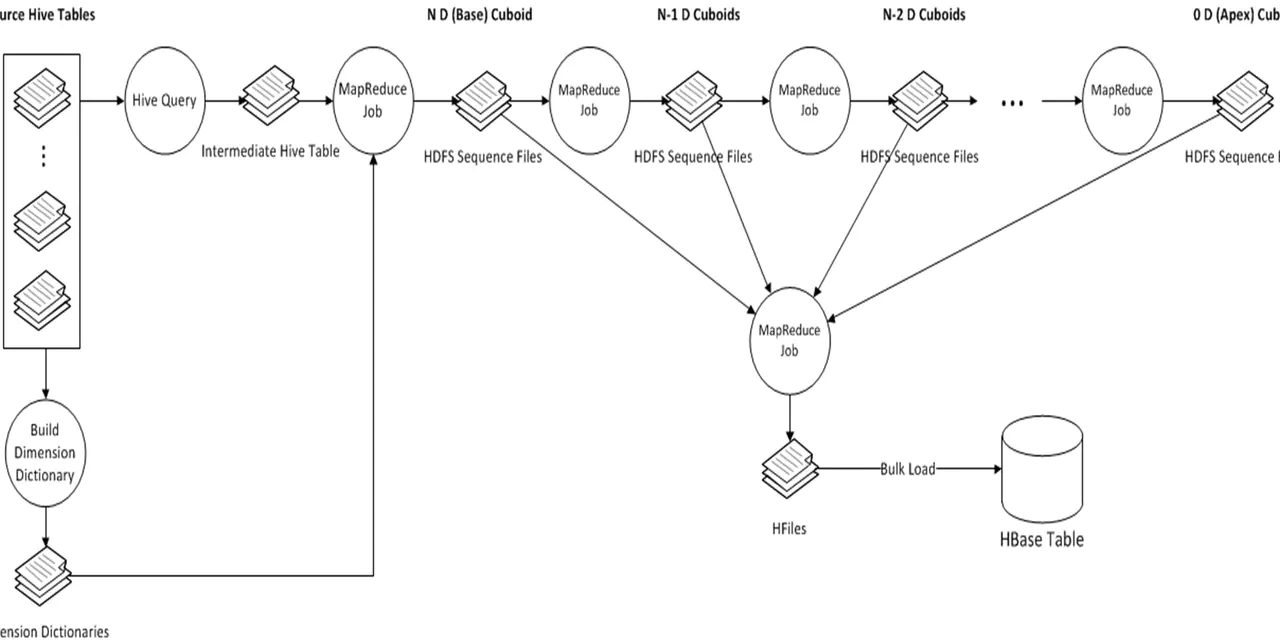
步骤:
- 创建Hive事实表中间表。hive 外部表。根据cube定义,查询出度量 维度 插入到新表去
- 重新分配中间表 文件的有的大有的小,不均匀,重分区,一百万行一个文件
- 提取事实表不同列值。计算出每一个出现在事实表中的维度列的distinct值 写入文件,如果有的列dinstinct值过大,就会OOM
- 创建维度字典 上一步生成的distinct column文件和维度表计算出所有维度的子典信息,并以字典树的方式压缩编码,生成维度字典,目的是节约空间
- 保存Cuboid的统计信息
- 创建HTable。 列族的设置,默认是一个列族, 默认使用lzo压缩 kylin强依赖于HBase的coprocessor,所以需要在创建HTable为该表部署coprocessor,这个文件会首先上传到HBase所在的HDFS上,然后在表的元信息中关联
- 构建 spark or mr ,由底层向顶层构建,直到一个不带group by的sql
- 将Cuboid数据转换成HFile 接口插入性能差,使用 将Cuboid数据转换成HFile, bulkLoad的方式将文件和HTable进行关联,这样可以大大降低Hbase的负载
- 导HFile入HBase表 将HFile文件load到HTable中,这一步完全依赖于HBase的工具
- key的格式由cuboid编号+每一个成员在字典树的id组成,value可能保存在多个列组里,包含在原始数据中按照这几个成员进行GROUP BY计算出的度量的值
- 更新Cube信息
- 清理
# kylin的查询流程?
Kylin执行查询流程分析
← 基于Flink的百亿数据去重实践 学习资源 →