# Hbase
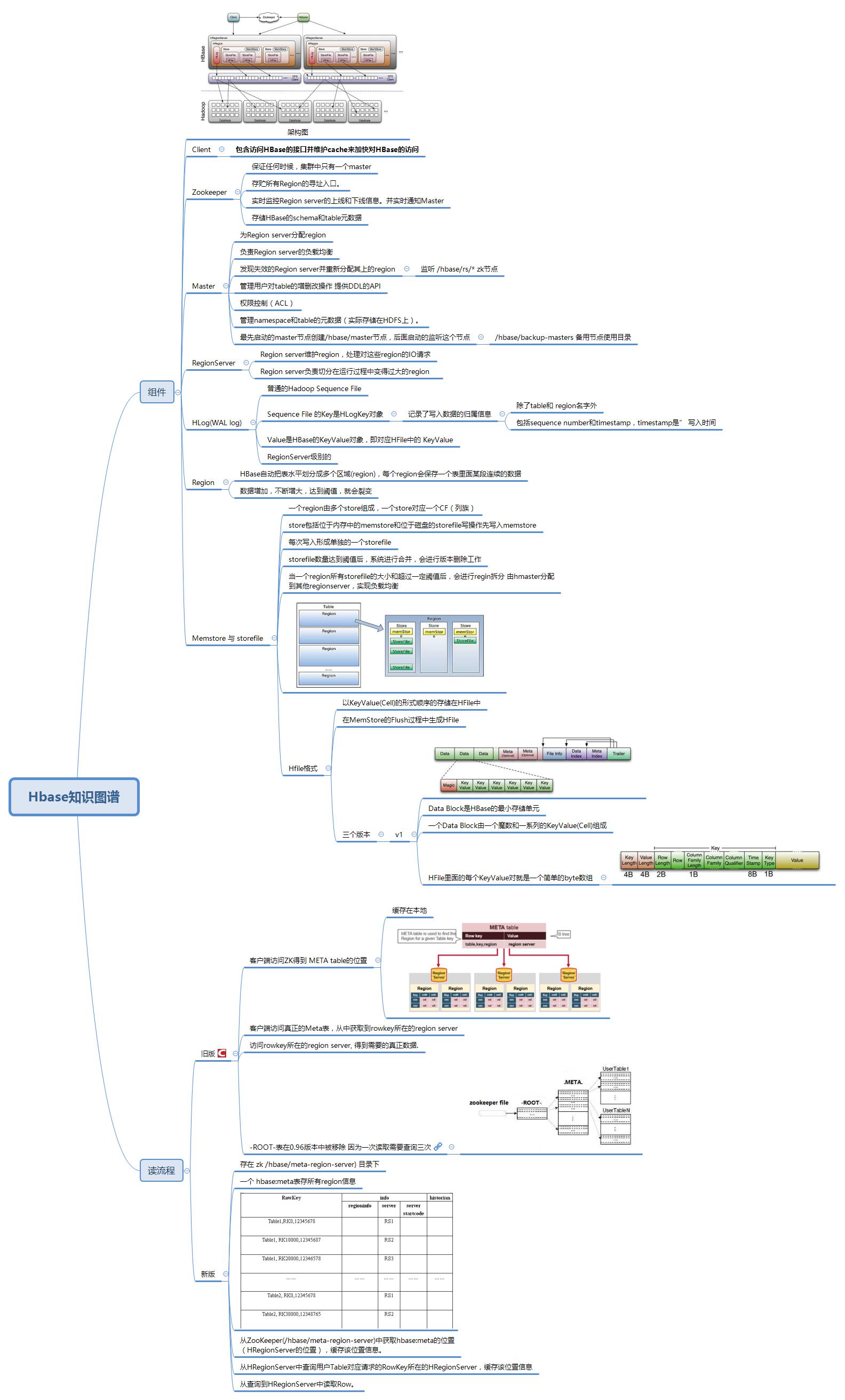
# hbase 架构讲解
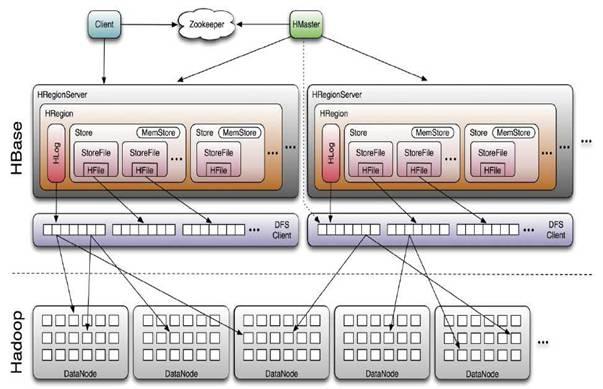
参考 深入HBase架构解析(一) - 上善若水 - BlogJava (opens new window)
# Hbase 热点现象及解决办法
# RowKey的设计原则?
# 参考
rowkey的设计原则:各个列簇数据平衡,长度原则、相邻原则,创建表的时候设置表放入regionserver缓存中,避免自动增长和时间,使用字节数组代替string,最大长度64kb,最好16字节以内,按天分表,两个字节散列,四个字节存储时分毫秒。
# 一条数据的HBase之旅
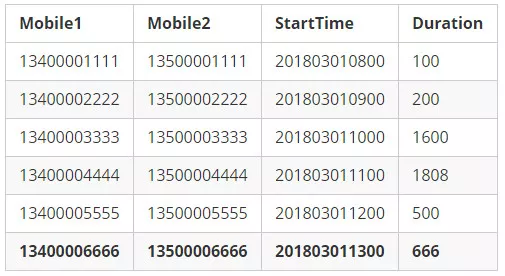
RowKey Format 1: Mobile1 + StartTime
RowKey Format 2: StartTime + Mobile1
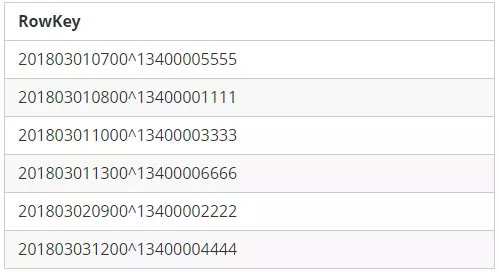
我们将RowKey中的第一个字段称之为"先导字段"。
第一种设计,有利于查询"手机号码XXX的在某时间范围内的数据记录",但不利于查询"某段时间范围内有哪些手机号码拨出了电话?",而第二种设计却恰好相反。
两种设计都是两个字段的直接组合,这种设计在实际应用中,会带来读写热点问题,难以保障数据读写请求在所有Regions之间的负载均衡。避免热点的常见方法有如下几种:
Reversing
如果先导字段本身会带来热点问题,但该字段尾部的信息却具备良好的随机性,此时,可以考虑将先导字段做反转处理,将尾部几位直接提前到前面,或者直接将整个字段完全反转。
将先导字段Mobile1翻转后,就具备非常好的随机性。
例如:
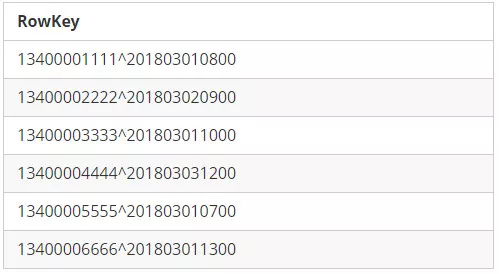
13400001111^201803010800
将先导字段Mobile1反转后的RowKey变为:
11110000431^201803010800

RowKey应该为: 66660000431^201803011300
因为创建表时预设的Region与RowKey强相关,我们现在才可以给出本文样例所需要创建的表的"Region分割点"信息:
假设,Region分割点为"1,2,3,4,5,6,7,8,9",基于这9个分割点,可以预先创建10个Region,这10个Region的StartKey和StopKey如下所示:
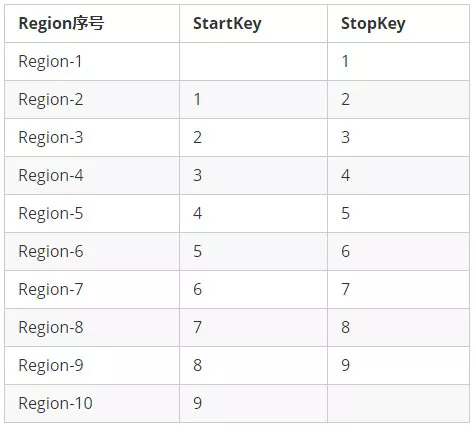
由于Mobile1字段的最后一位是0~9之间的随机数字,因此,可以均匀打散到这10个Region中
Salting
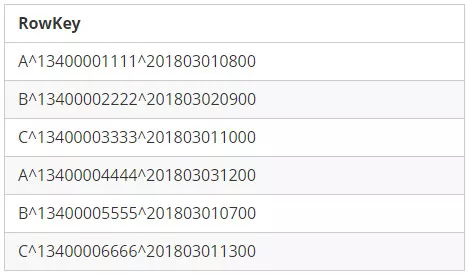
Salting的原理是在RowKey的前面添加固定长度的随机Bytes,随机Bytes能保障数据在所有Regions间的负载均衡。
能够分散,但是对于读取不是很友好,查询并不知道前面添加的是什么,所以包含 A B C的regions都得去查一下
Hashing
Hashing是将一个RowKey通过一个Hash函数生成一组固定长度的bytes,Hash函数能保障所生成的随机bytes具备良好的离散度,从而也能够均匀打散到各个Region中
Hashing既有利于随机写入,又利于基于知道RowKey各字段的确切信息之后的随机读取操作,但如果是基于RowKey范围的Scan或者是RowKey的模糊信息进行查询的话,就会带来显著的性能问题,因为原来在字典顺序相邻的RowKey列表,通过Hashing打散后导致这些数据被分散到了多个Region中
# Hbase BlockCache的理解
BlockCache也称为读缓存,HBase会将一次文件查找的Block块缓存到Cache中,以便后续同一请求或者邻近数据查找请求直接从内存中获取,避免昂贵的IO操作,重要性不言而喻。BlockCache有两种实现机制:LRUBlockCache和BucketCache(通常是off-heap)
- BlockCache的内容
# 行式存储和列式存储的优劣势?
# Hbase 二级索引实现
- 技术分享 | HBase二级索引实现方案 - 后端 - 掘金 (opens new window)
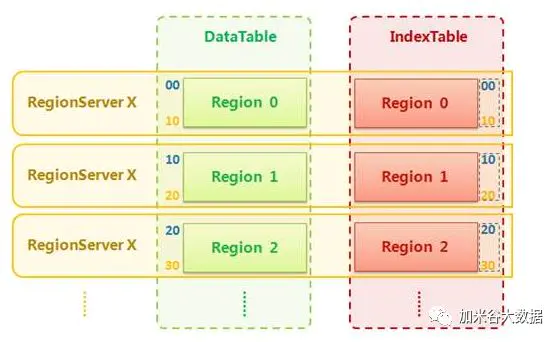
- IndexTable的创建过程如下:
- 获取DataTable的所有RegionInfo,得到所有DataTable Region的StartKey。
- 结合索引定义和DataTable Region的StartKey信息,调用HBaseAdmin的createTable(final HTableDescriptor desc, byte [][] splitKeys)方法创建索引表。
- 通过以上两步便建立了IndexTable Region和DataTable Region的以StartKey为依据的一一对应关系。
- IndexTable RowKey

# HBase Master和Regionserver的交互;
# HBase的HA,Zookeeper在其中的作用;
# Master宕机的时候,哪些能正常工作,读写数据;
# region分裂的过程?
# Hbase 列簇的设计原则
列族的设计原则:尽可能少(按照列族进行存储,按照region进行读取,不必要的io操作),经常和不经常使用的两类数据放入不同列族中,列族名字尽可能短。
# hbase性能解决方案:
1、hbase怎么给web前台提供接口来访问? hbase有一个web的默认端口60010,是提供客户端用来访问hbase的
2、hbase有没有并发问题?
3、Hbase中的metastore用来做什么的? Hbase的metastore是用来保存数据的,其中保存数据的方式有有三种第一种与第二种是本地储存,第三种是远程储存这一种企业用的比较多
4、HBase在进行模型设计时重点在什么地方?一张表中定义多少个Column Family最合适?为什么? 具体看表的数据,一般来说划分标准是根据数据访问频度,如一张表里有些列访问相对频繁,而另一些列访问很少,这时可以把这张表划分成两个列族,分开存储,提高访问效率
5、如何提高HBase客户端的读写性能?请举例说明。 ①开启bloomfilter过滤器,开启bloomfilter比没开启要快3、4倍 ②Hbase对于内存有特别的嗜好,在硬件允许的情况下配足够多的内存给它 ③通过修改hbase-env.sh中的 export HBASE_HEAPSIZE=3000 #这里默认为1000m ④增大RPC数量 通过修改hbase-site.xml中的 hbase.regionserver.handler.count属性,可以适当的放大。默认值为10有点小
6、直接将时间戳作为行健,在写入单个region 时候会发生热点问题,为什么呢? HBase的rowkey在底层是HFile存储数据的,以键值对存放到SortedMap中。并且region中的rowkey是有序存储,若时间比较集中。就会存储到一个region中,这样一个region的数据变多,其它的region数据很好,加载数据就会很慢。直到region分裂可以解决。
# bulkload原理?
HBase BulkLoad批量写入数据实战
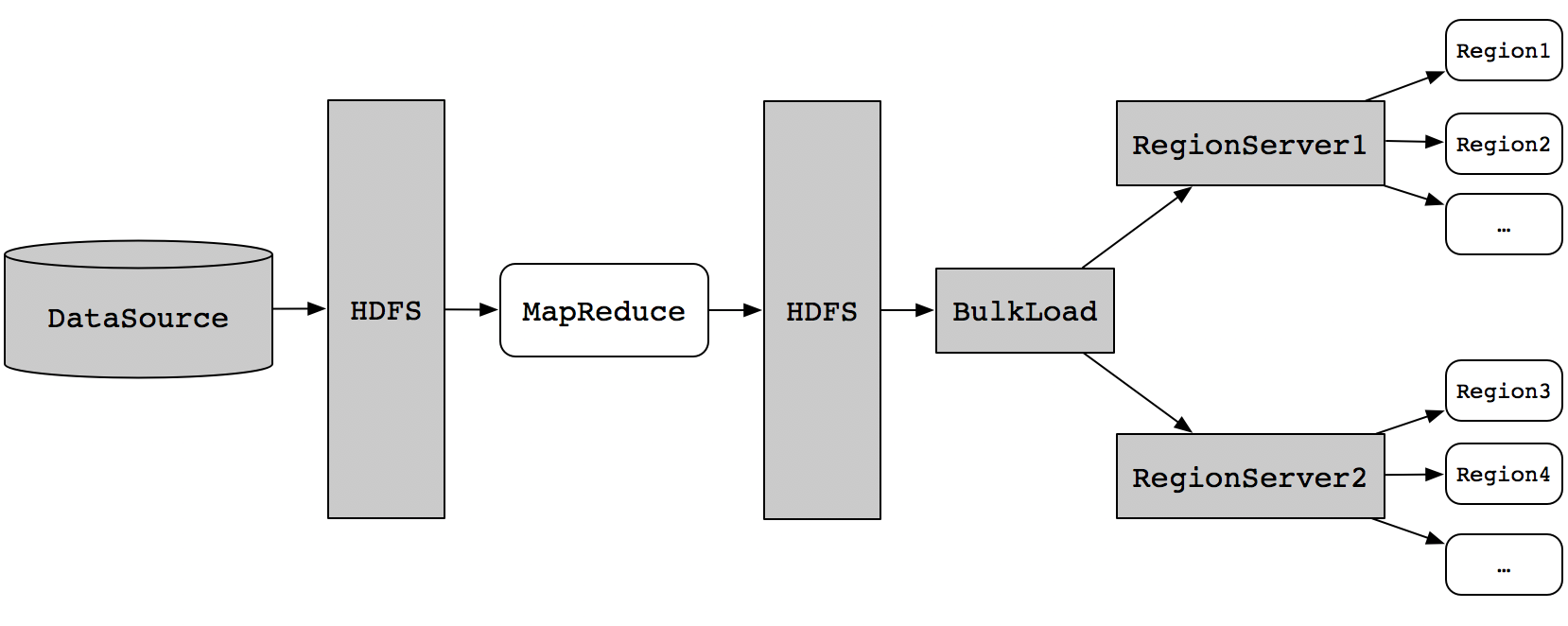
hbase底层文件夹格式 " /hbase/data/default/<tbl_name>/<region_id>/<cf>/<hfile_id>"
按照hbase的底层文件存储在hdfs的原理,使用MR直接生成HFile格式的数据文件 然后通过RS将hfile移动到对应的region中去,HFileOutputFormat2.configureIncrementalLoad(job, table);