# Hbase写数据流程
# 参考
- 一条数据的HBase之旅,简明HBase入门教程-Write全流程 (opens new window)
- 一条数据的HBase之旅,简明HBase入门教程-Flush与Compaction (opens new window)
- HBase - 数据写入流程解析 – 有态度的HBase/Spark/BigData (opens new window)
# HBase - 数据写入流程解析
HBase默认适用于写多读少的应用
客户端
- 用户提交put请求后,HBase客户端会将put请求添加到本地buffer中,符合一定条件就会通过AsyncProcess异步批量提交 HBase默认设置autoflush=true 可设置为false,没有保护机制
- 在提交之前,HBase会在元数据表.meta.中根据rowkey找到它们归属的region server,这个定位的过程是通过HConnection的locateRegion方法获得的
- HBase会为每个HRegionLocation构造一个远程RPC请求MultiServerCallable,然后通过rpcCallerFactory.newCaller()执行调用
服务端
服务器端RegionServer接收到客户端的写入请求后,首先会反序列化为Put对象,然后执行各种检查操作,比如检查region是否是只读、memstore大小是否超过blockingMemstoreSize
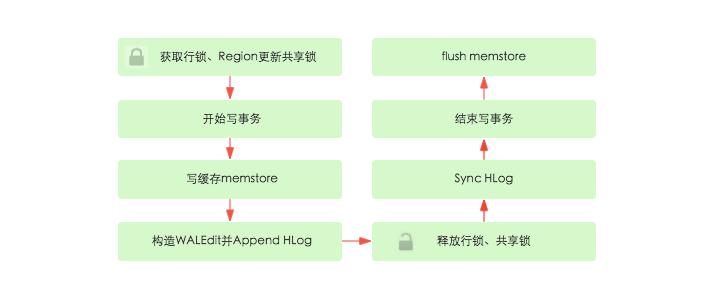
- 获取行锁、Region更新共享锁 同行数据的原子性
- 开始写事务:获取write number,用于实现MVCC,实现数据的非锁定读,在保证读写一致性的前提下提高读取性能
- 写缓存memstore:HBase中每列族都会对应一个store,用来存储该列数据。每个store都会有个写缓存memstore,用于缓存写入数据。HBase并不会直接将数据落盘,而是先写入缓存,等缓存满足一定大小之后再一起落盘。
- Append HLog:HBase使用WAL机制保证数据可靠性,即首先写日志再写缓存,即使发生宕机,也可以通过恢复HLog还原出原始数据。
- 释放行锁以及共享锁
- Sync HLog:HLog真正sync到HDFS,在释放行锁之后执行sync操作是为了尽量减少持锁时间,提升写性能 如果Sync失败,执行回滚操作将memstore中已经写入的数据移除。
- 结束写事务
- flush memstore:当写缓存满64M之后,会启动flush线程将数据刷新到硬盘
# 一条数据的HBase之旅Write全流程-Nosql漫谈
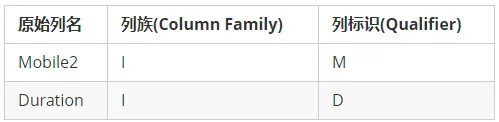
基于RowKey和列定义信息,就可以组建HBase的Put对象,一个Put对象用来描述待写入的一行数据,一个Put可以理解成与某个RowKey关联的1个或多个KeyValue的集合。
# 初始化ZooKeeper Session
在第一次从ZooKeeper中读取META Region的地址时,需要先初始化一个ZooKeeper Session。ZooKeeper Session是ZooKeeper Client与ZooKeeper Server端所建立的一个会话,通过心跳机制保持长连接。
# 获取Region路由信息
通过前面建立的连接,从ZooKeeper中读取meta Region所在的RegionServer 获取了meta Region的路由信息以后,再从meta Region中定位要读写的RowKey所关联的Region信息
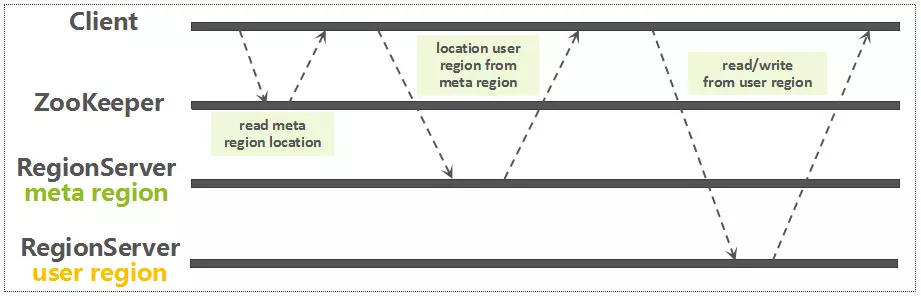
因为每一个用户表Region都是一个RowKey Range,meta Region中记录了每一个用户表Region的路由以及状态信息,以RegionName(包含表名,Region StartKey,Region ID,副本ID等信息)作为RowKey。基于一条用户数据RowKey,快速查询该RowKey所属的Region的方法其实很简单:只需要基于表名以及该用户数据RowKey,构建一个虚拟的Region Key,然后通过Reverse Scan的方式,读到的第一条Region记录就是该数据所关联的Region。如下图所示

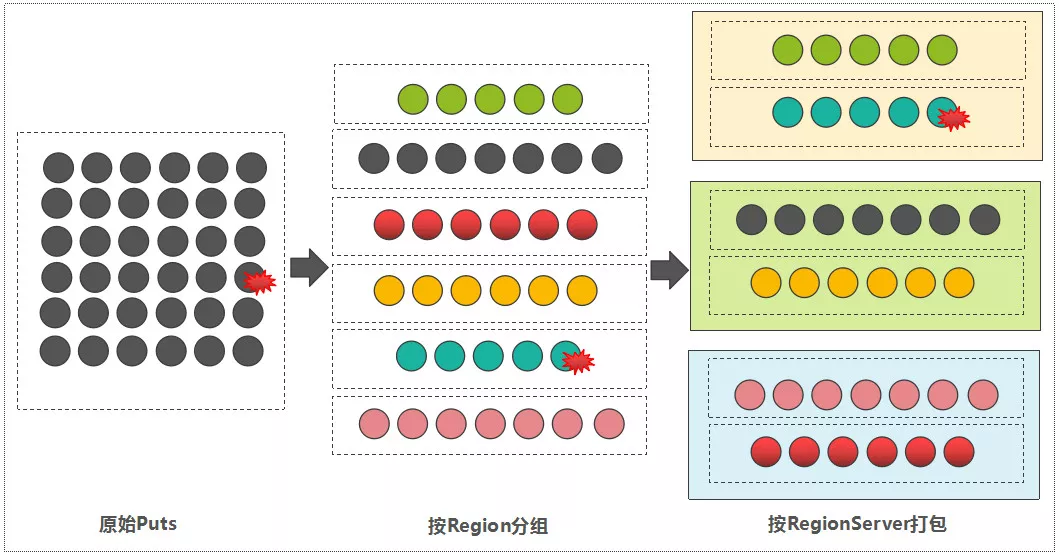
# 分组打包
Single Put: 先定位该RowKey所对应的Region以及RegionServer信息后,Client直接发送写请求到RegionServer侧即可
Batch Put: 客户端在将所有的数据写到对应的RegionServer之前,会先分组"打包"
- 按Region分组 ,遍历每一条Rowkey,根据meta表,得到每一条数据属于哪一个获取到Region到RowKey列表的映射关系。
- 按RegionServer"打包" 因为Region一定归属于某一个RegionServer 属于同一个RegionServer的多个Regions的写入请求,被打包成一个MultiAction对象,这样可以一并发送到每一个RegionServer中
# Client发RPC请求到RegionServer

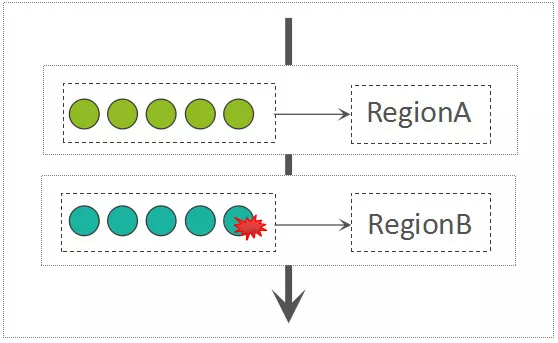
# RegionServer:Region分发
# single put
在发送过来的请求参数MutateRequest中,已经携带了这条记录所关联的Region,那么直接将该请求转发给对应的Region即可
# batch puts
则接收到的请求参数为MultiRequest,在MultiRequest中,混合了这个RegionServer所持有的多个Region的写入请求,每一个Region的写入请求都被包装成了一个RegionAction对象。RegionServer接收到MultiRequest请求以后,遍历所有的RegionAction,而后写入到每一个Region中,此过程是串行的:
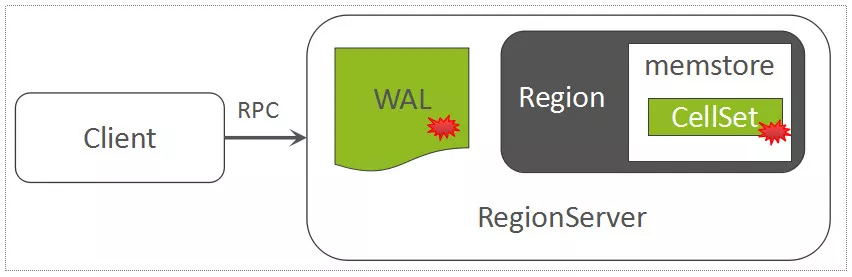
# Region内部处理:写WAL
hbase 基于 LSM-Tree的架构 LSM-Tree利用了传统机械硬盘的“顺序读写速度远高于随机读写速度”的特点
每一个Region中随机写入的数据,都暂时先缓存在内存中(HBase中存放这部分内存数据的模块称之为MemStore)
顺序写入到一个称之为WAL
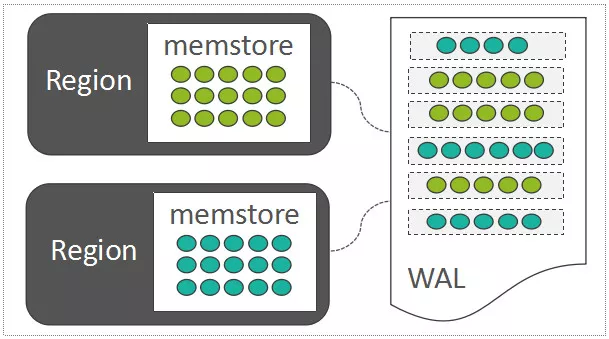
断电 wal 回放即可
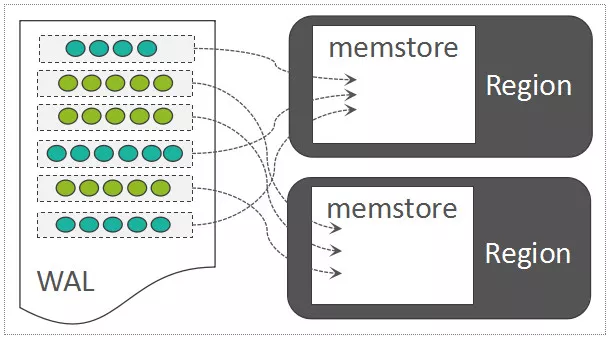
默认一个RegionServer只有一个可写的WAL文件。WAL中写入的记录,以Entry为基本单元,而一个Entry中,包含
- **WALKey **{Encoded Region Name,Table Name,Sequence ID,Timestamp} Sequence ID在维持数据一致性方面起到了关键作用,可以理解为一个事务ID
- WALEdit WALEdit中直接保存待写入数据的所有的KeyValues,而这些KeyValues可能来自一个Region中的多行数据。
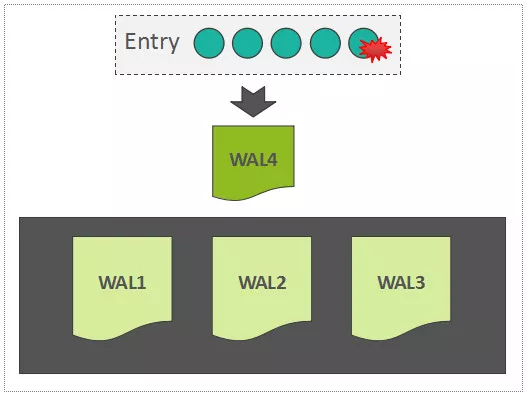
# wal扩展
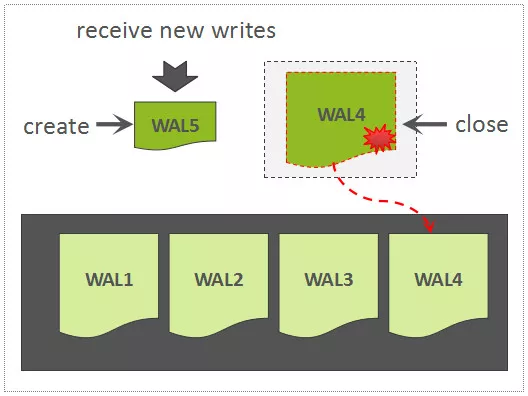
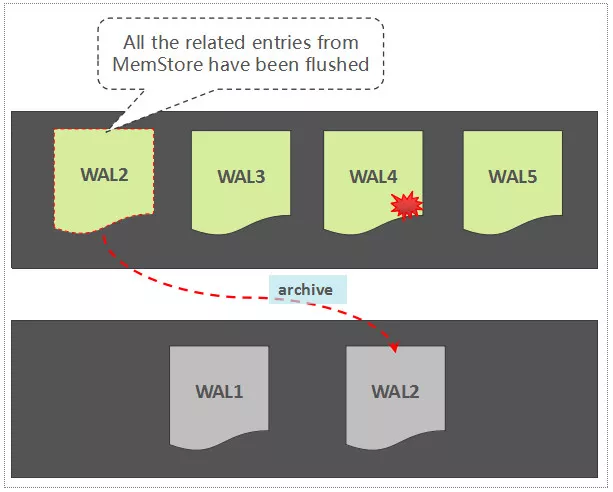
# WAL Roll and Archive
# Region内部处理:写MemStore
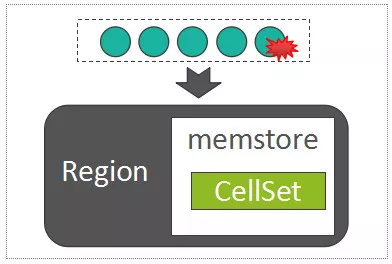
每一个Column Family,在Region内部被抽象为了一个HStore对象,而每一个HStore拥有自身的MemStore,用来缓存一批最近被随机写入的数据
MemStore中用来存放所有的KeyValue的数据结构,称之为CellSet,而CellSet的核心是一个ConcurrentSkipListMap,我们知道,ConcurrentSkipListMap是Java的跳表实现,数据按照Key值有序存放,而且在高并发写入时,性能远高于ConcurrentHashMap。
写MemStore的过程,事实上是将batch put提交过来的所有的KeyValue列表,写入到MemStore的以ConcurrentSkipListMap为组成核心的CellSet中:
# 一条数据的HBase之旅-Flush与Compaction-NoSQL漫谈
# Flush&Compaction
# 1.x
1.x 更早 MemStore中的数据,达到一定的阈值,被Flush成HDFS中的HFile文件。
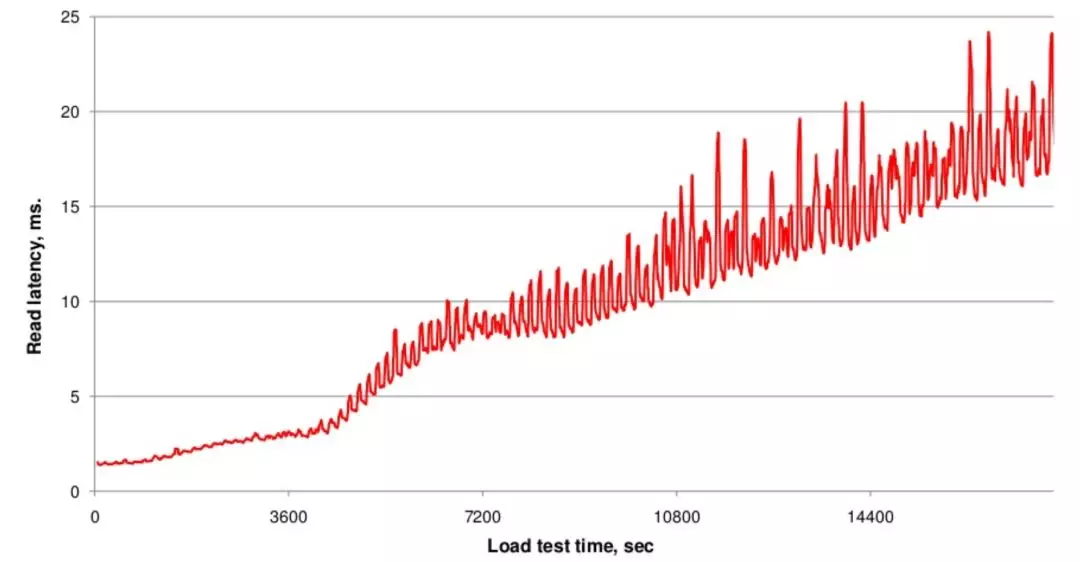
随着HFile的数量的不断增多对读取时延带来的影响
Read流程
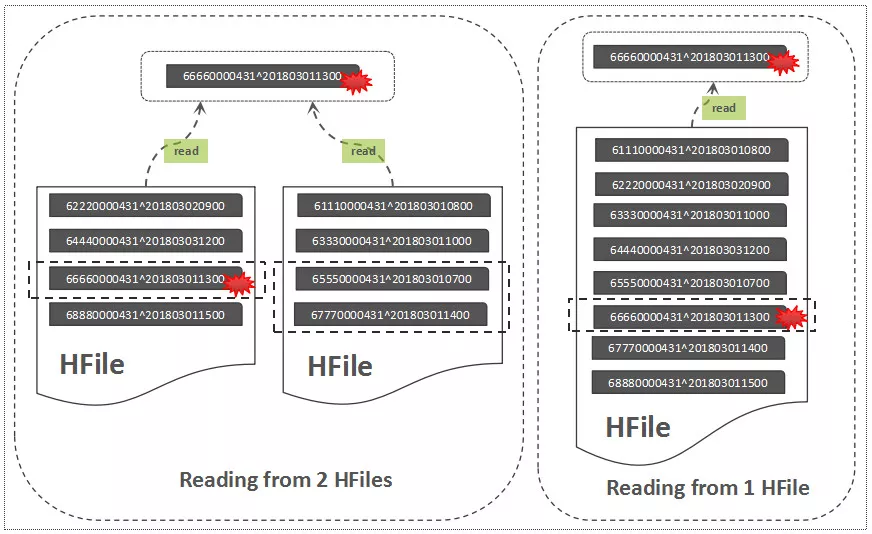
从两个文件中读取,将导致更多的IOPS。这就是HBase Compaction存在的一大初衷,Compaction可以将一些HFile文件合并成较大的HFile文件,也可以把所有的HFile文件合并成一个大的HFile文件,这个过程可以理解为:将多个HFile的“交错无序状态*”*,变成单个HFile的“有序状态*”*,降低读取时延
小范围的HFile文件合并,称之为Minor Compaction,一个列族中将所有的HFile文件合并,称之为Major Compaction
除了范围不同, Major Compaction还会清理一些TTL过期/版本过旧以及被标记删除的数据。
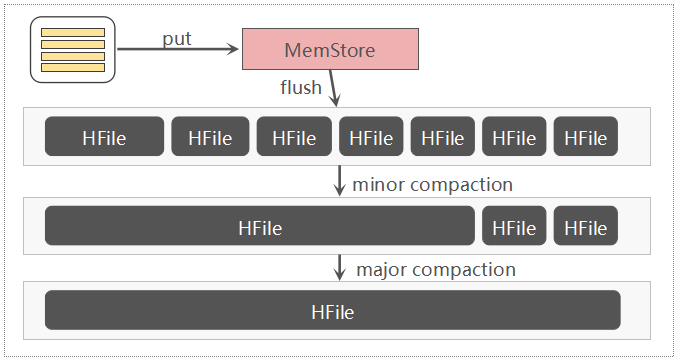
# Flush
默认的Flush,仅仅是将正在写的MemStore中的数据归档成一个不可变的Segment,而这个Segment依然处于内存中,这就是2.0的新特性:In-memory Flush and Compaction
MemStore由一个可写的Segment,以及一个或多个不可写的Segments构成。
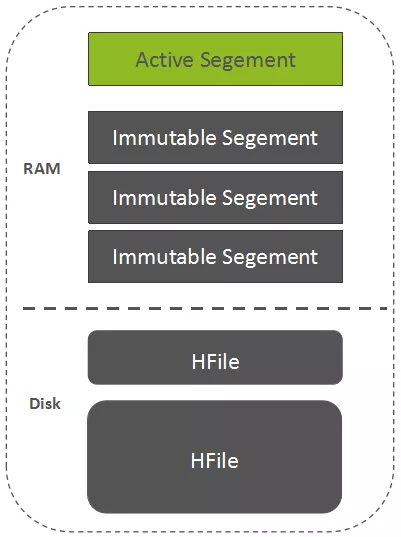
MemStore中的数据先Flush成一个Immutable的Segment,多个Immutable Segments可以在内存中进行Compaction,当达到一定阈值以后才将内存中的数据持久化成HDFS中的HFile文件
# 为什么?
改善IO,避免频繁写文件
如果MemStore中的数据被直接Flush成HFile,而多个HFile又被Compaction合并成了一个大HFile,随着一次次Compaction发生以后,一条数据往往被重写了多次,这带来显著的IO放大问题,另外,频繁的Compaction对IO资源的抢占,其实也是导致HBase查询时延大毛刺的罪魁祸首之一
那为何不干脆调大MemStore的大小?这里的本质原因在于,ConcurrentSkipListMap在存储的数据量达到一定大小以后,写入性能将会出现显著的恶化。
In-Memory Flush and Compaction
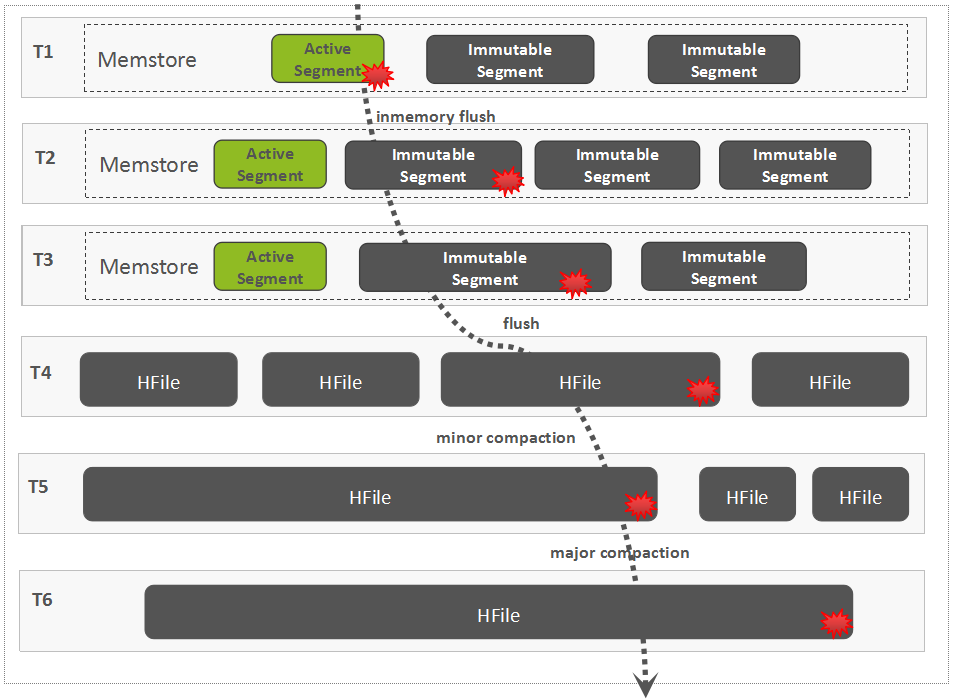
# Compaction
# Compaction会导致写入放大
随着不断的执行Minor Compaction以及Major Compaction,可以看到,这条数据被反复读取/写入了多次,这是导致写放大的一个关键原因,这里的写放大,涉及到网络IO与磁盘IO,因为数据在HDFS中默认有三个副本。
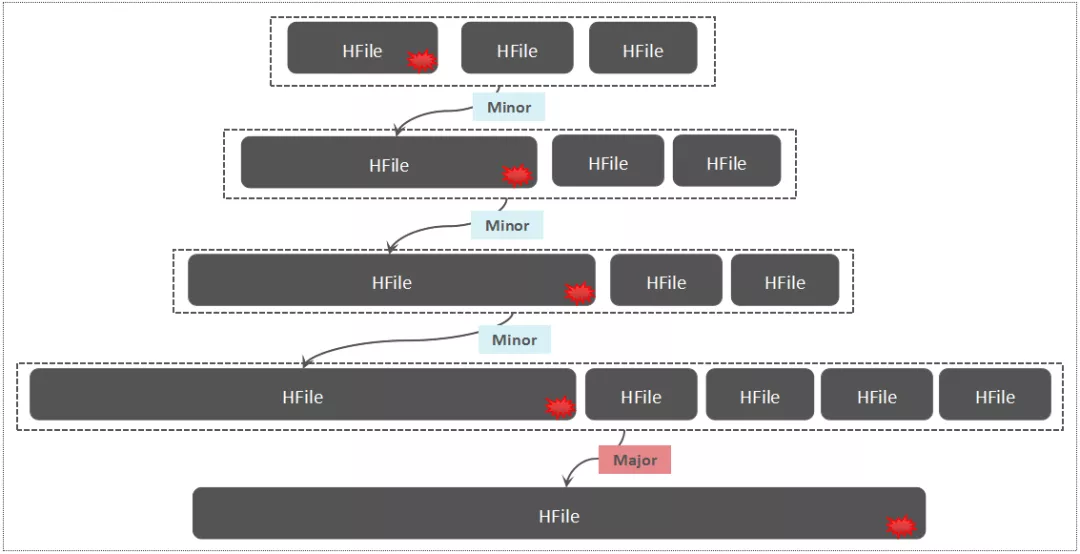
# Compaction的本质
原因:
- 减少HFile文件数量,减少文件句柄数量,降低读取时延
- Major Compaction可以帮助清理集群中不再需要的数据(过期数据,被标记删除的数据,版本数溢出的数据)
- 很多HBase用户在集群中关闭了自动Major Compaction,为了降低Compaction对IO资源的抢占,但出于清理数据的需要,又不得不在一些非繁忙时段手动触发Major Compaction,这样既可以有效降低存储空间,也可以有效降低读取时延。
← Hbase读数据流程 ClickHouse →