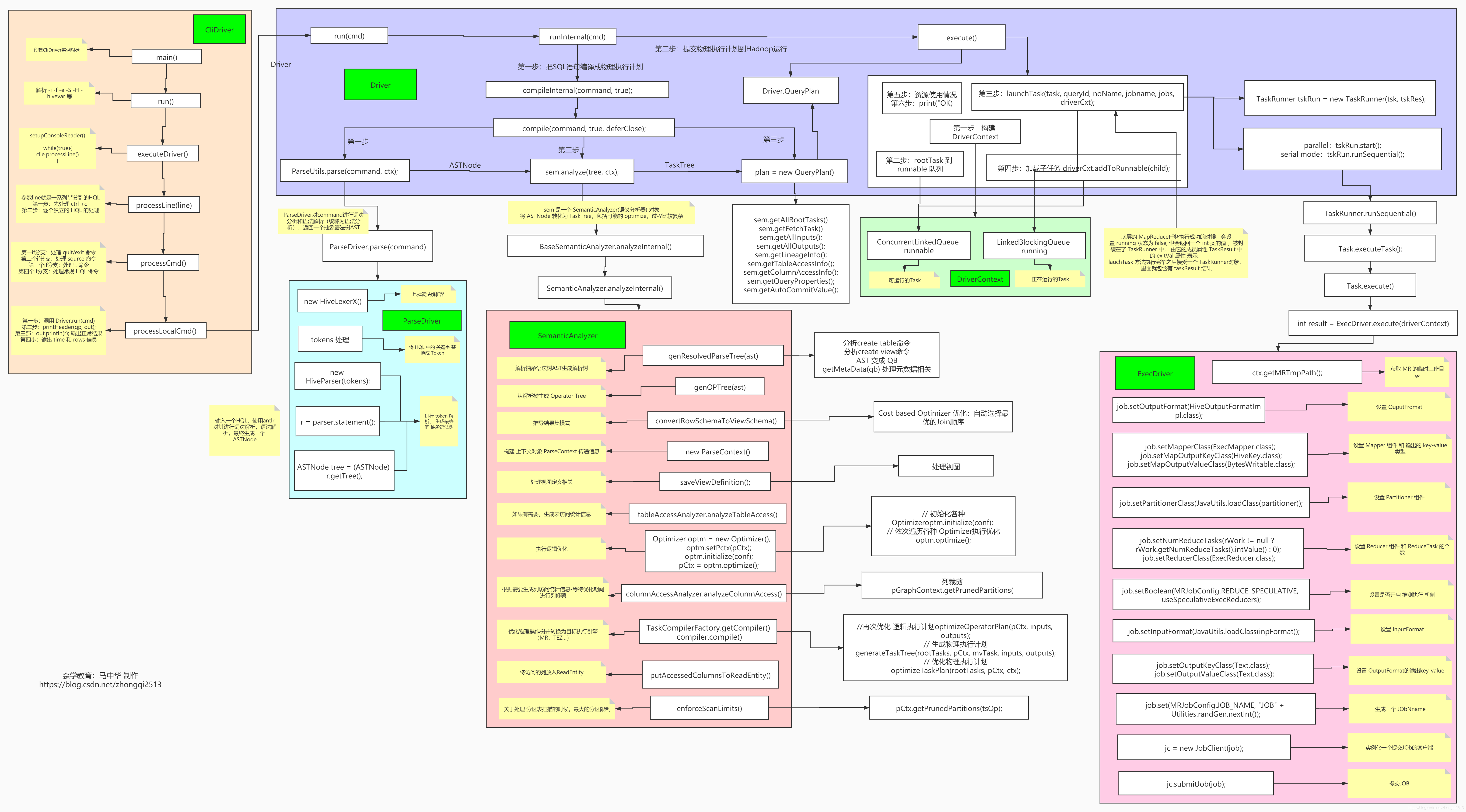
# Hive底层执行逻辑深度剖析
FaceBook的工程师早期在使用开源Hadoop进行海量数据分析的时候,发现直接编写MapReduce比较低效,遂研发了一个Hadoop的SQL客户端来管理存储在Hadoop中的结构化数据,从而提高开发效率,而且也降低了入 门大数据开发和分析的门]槛。 未来开发的趋势:
- Web UI平台
- SQL开发/拖拽开发
- 流式计算处理引擎
一句话总结就是:将来的大数据处理,都是平台化的管理方式,底层运行的是高效的流式计算引擎,用户的不是直接编写流式计算弓|擎的应用代码,而是SQL语句。
# Hive定义
Hive依赖于HDFS存储数据I Hive将HQL转换成MapReduce执行,所以说Hive是基于Hadoop的一个数据仓 库工具,实质就是一款基于HDFS的MapReduce计算框架, 对存储在HDFS中的数据进行分析和管理。
- Hive由Facebook实现并开源
- Hive是基于Hadoop的一个数据仓库工具
- Hive存储的数据其实底层存储在HDFS上
- Hive将HDFS上的结构化的数据映射为一张数据库表,类似于exce1或者msyq1的表
- Hive提供HQL (Hive SQL) 查询功能
- Hive的本质是将SQL语句转换为MapReduce任务运行,使不熟悉MapReduce的用户很方便地利用HQL处理和计算HDFS 上的结构化的数据,适用于离线的批量数据计算
- Hive 使用户可以极大简化分布式计算程序的编写,而将精力集中于业务逻辑
# 架构
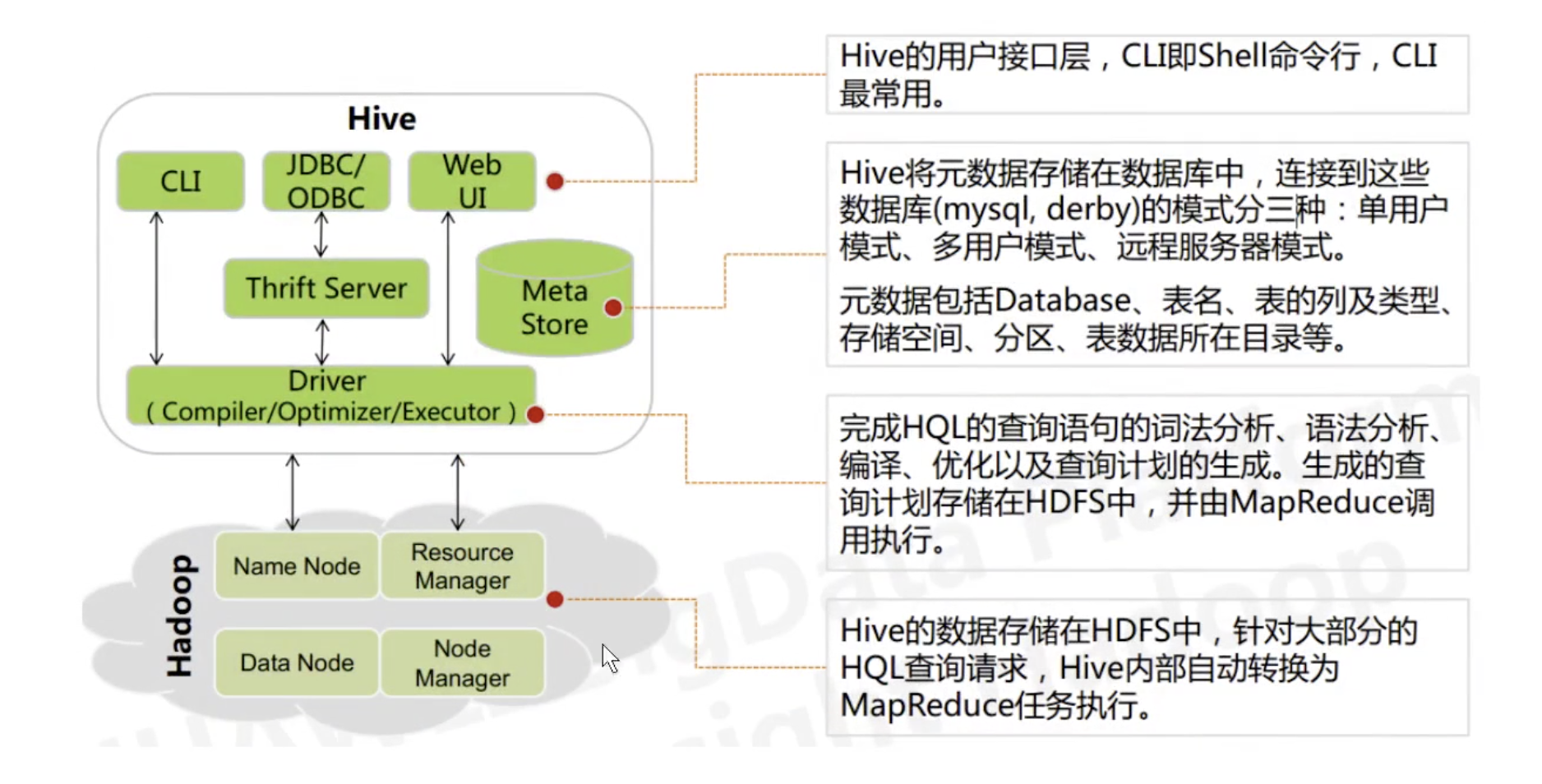
# 语法支持
Hive SQL的编译过程 - 美团技术团队 (opens new window)
支持的语法: .
1. select * from db. table1
2. select count(distinct uid) from db. tab7e1
3. 支持select、union a11. join (1eft、right、fu11 join)、1ike、where、having、 各种聚合函数、支持
json解析
4. UDF (User Defined Function) / UDAF/UDTF
5. 不支持update和delete
6. hive虽然支持in/exists (老版本是不支持的),但是hive推荐使用semi join的方式来代替实现, 而且效率更
高。
7. 支持case .. when
select ... from ... join .. on ... where .... groupby ... having .. order by .. Timit .
不支持的语法:
1. 支持等值链接,不支持非等值链接
select a.*, b.* from a join b on a.age = b.age; 可以
select a.*, b.* from a join b on a.age > b. age; 不可以
2. 支持and多条件过滤,不支持or多条件过滤
select a.*, b.* from a join b on a.id = b.id and a. name = b. name; 可以
select a.*,b.* from a join b on a.id = b.id or a. name = b. name; 不可以
3. 不支持update和delete
# MapReduce 执行原理
mapreduce的执行原理! ! ! 我和李老师,和玄姐三个斗地主,但是呢,只要一幅旧扑克牌。 54张
- 我手速很快,一个人快速的数一下 作死的提升机器的性能。单 机处理思维
- 我随便把这旧牌分成三堆,我, 李老师,玄姐。一人数一堆。效率有所提升。 缺少汇总阶段 我,李老师,玄姐===> 54分布式处理思维 分布式处理思维 必然分成两个阶段: 1. 一个复杂的任务拆分成多个小任务这些小任务可以并行执行I 2. 这多个小任务的计算结果需要进行汇总执行汇总
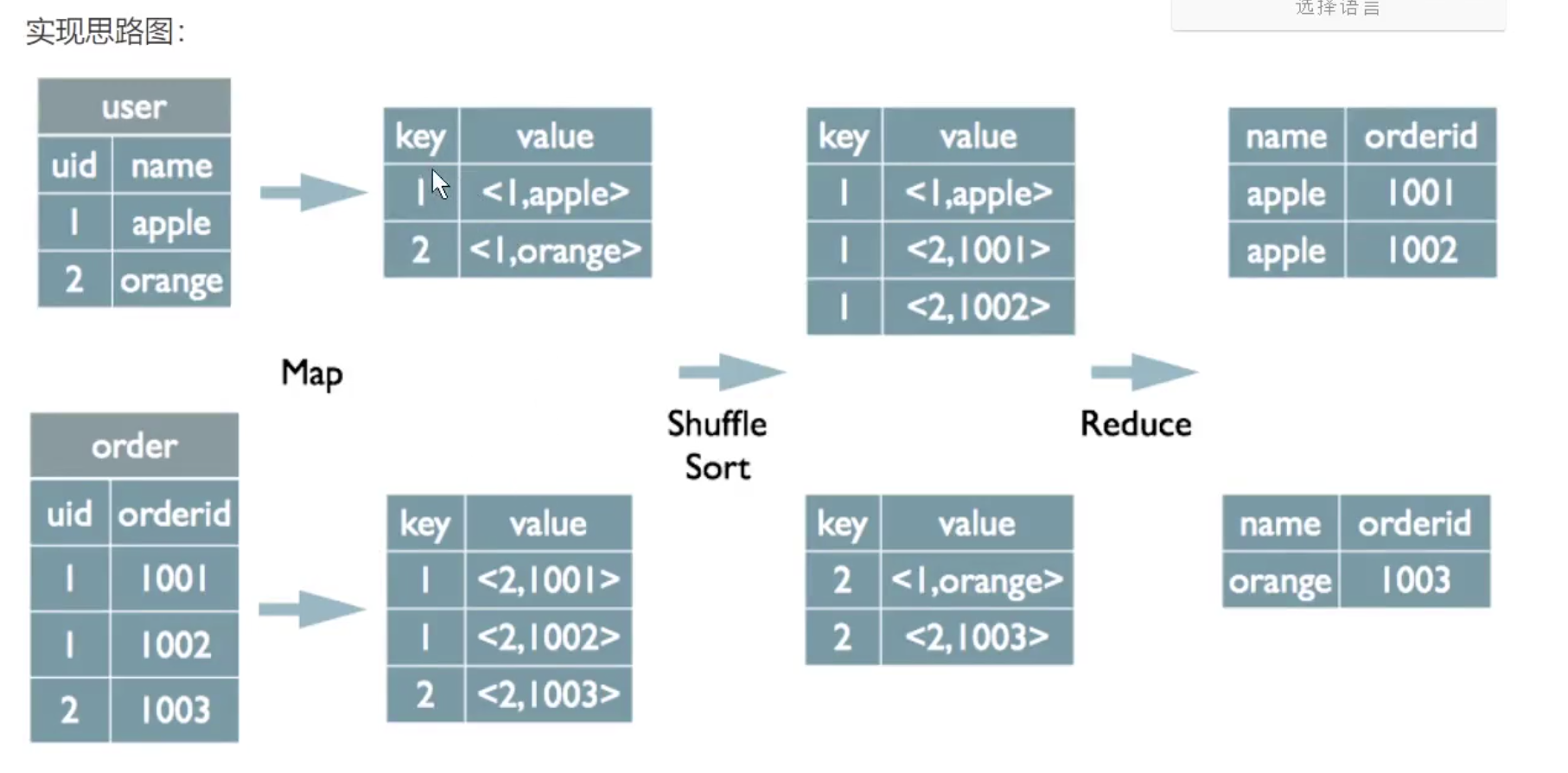
# Join实现
select u. name, o. orderid from order O join user u on o.uid = u. uid;
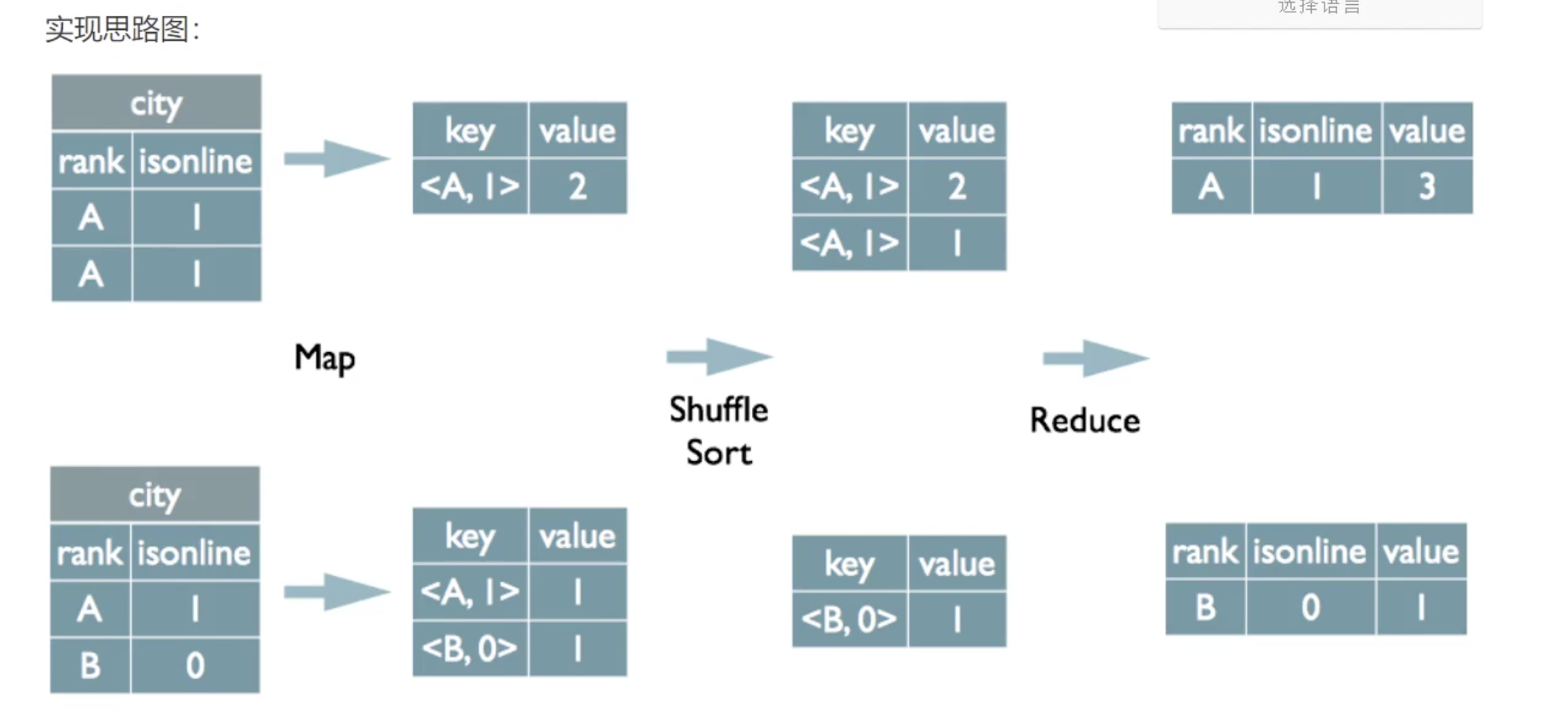
# Group by
select rank, isonline, count(*) from city group by rank , isonline;
# Distinct
select dealid, count(distinct uid) num from order group by dealid;
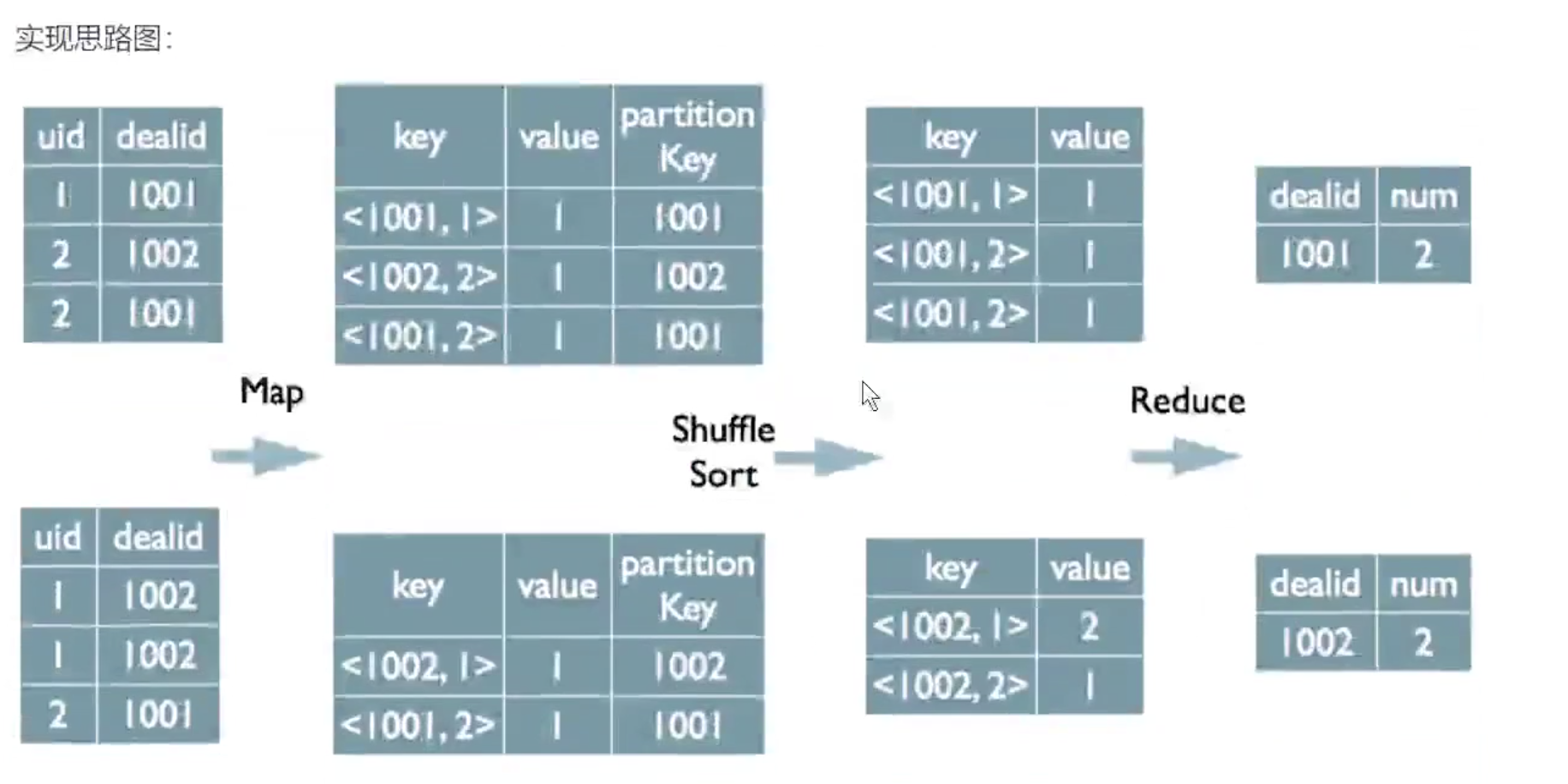
# 怎么转换成MR的
了解了MapReduce实现SQL基本操作之后,我们来看看Hive是如何将SQL转化为MapReduce任务的,整个编译过 程分为六个阶段:
Antlr 定义SQL的语法规则,完成SQL词法, 语法解析,将SQL转化为抽象语法树AST Tree 树上的每个节点就是一个 AST Node
遍历AST Tree,抽象出查询的基本组成单元QueryBlock 子查询

遍历QueryB1ock,翻译为执行操作树operatorTree
逻辑层优化器进行operatorTree变换,合并不必要的Reducesi nkoperator,减少shuff1e数据量
遍历operatorTree,翻译为MapReduce任务
物理层优化器进行MapReduce任务的变换,生成最终的执行计划
# 原理