# 学习资源
# 学习网站
# 推荐博客
# z小赵系列
重要:Kafka第3篇之一条消息如何被存储到Broker上 (opens new window)
Kafka系列第4篇:消息发送时,网络“偷偷”帮忙做的那点事儿 (opens new window)
kafka系列第5篇:一文读懂消费者背后的那点"猫腻" (opens new window)
Kafka系列第6篇:消息是如何在服务端存储与读取的,你真的知道吗? (opens new window)
Kafka:你必须要知道集群内部工作原理的一些事! (opens new window)
# Kafka数据可靠性深度解读
Kafka数据可靠性深度解读-InfoQ (opens new window)
# 分区结构
drwxr-xr-x 2 root root 4096 Apr 10 16:10 topic_vms_test-0
drwxr-xr-x 2 root root 4096 Apr 10 16:10 topic_vms_test-1
drwxr-xr-x 2 root root 4096 Apr 10 16:10 topic_vms_test-2
drwxr-xr-x 2 root root 4096 Apr 10 16:10 topic_vms_test-3
segment结构
00000000000000000000.index
00000000000000000000.log
00000000000000170410.index
00000000000000170410.log
00000000000000239430.index
00000000000000239430.log
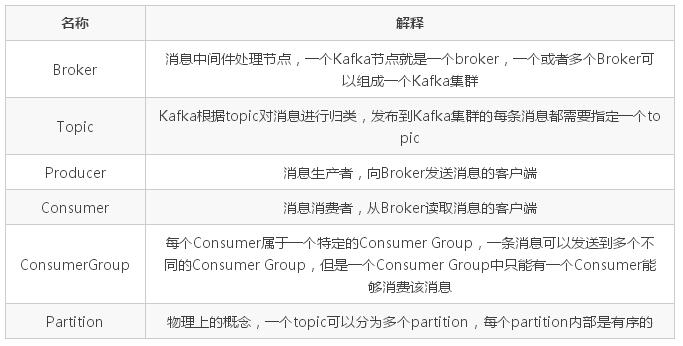
index与log的对应关系
“.index”索引文件存储大量的元数据,“.log”数据文件存储大量的消息,索引文件中的元数据指向对应数据文件中 message 的物理偏移地址
其中以“.index”索引文件中的元数据 [3, 348] 为例,在“.log”数据文件表示第 3 个消息,即在全局 partition 中表示 170410+3=170413 个消息,该消息的物理偏移地址为 348。
那么如何从 partition 中通过 offset 查找 message 呢?
以上图为例,读取 offset=170418 的消息,首先查找 segment 文件,其中 00000000000000000000.index 为最开始的文件,第二个文件为 00000000000000170410.index(起始偏移为 170410+1=170411),而第三个文件为 00000000000000239430.index(起始偏移为 239430+1=239431),所以这个 offset=170418 就落到了第二个文件之中。其他后续文件可以依次类推,以其实偏移量命名并排列这些文件,然后根据二分查找法就可以快速定位到具体文件位置。其次根据 00000000000000170410.index 文件中的 [8,1325] 定位到 00000000000000170410.log 文件中的 1325 的位置进行读取。
要是读取 offset=170418 的消息,从 00000000000000170410.log 文件中的 1325 的位置进行读取,那么怎么知道何时读完本条消息,否则就读到下一条消息的内容了?这个就需要联系到消息的物理结构了,消息都具有固定的物理结构,包括:offset(8 Bytes)、消息体的大小(4 Bytes)、crc32(4 Bytes)、magic(1 Byte)、attributes(1 Byte)、key length(4 Bytes)、key(K Bytes)、payload(N Bytes) 等等字段,可以确定一条消息的大小,即读取到哪里截止。
# 复制原理和同步方式
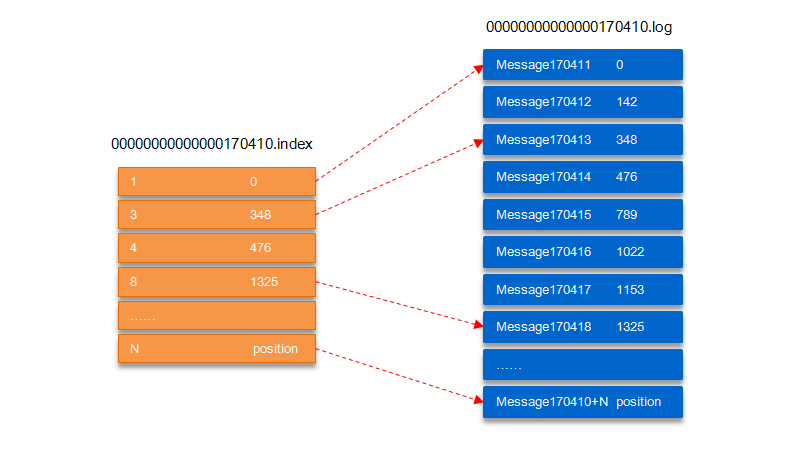
LEO,LogEndOffset 的缩写,表示每个partition 的log 最后一条Message 的位置
HW 是HighWatermark 的缩写,是指consumer 能够看到的此partition 的位置
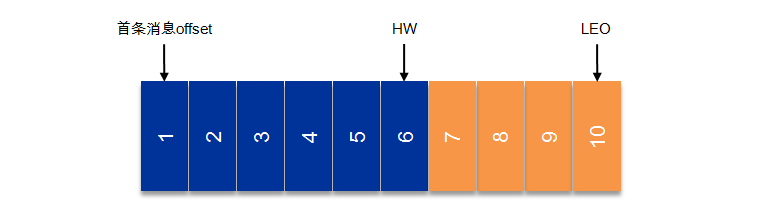
# ISR
ISR (In-Sync Replicas),这个是指副本同步队列,对吞吐量有一定影响,但是极大增强了可用性
ISR 列表,follower 从 leader 同步数据有一些延迟(包括延迟时间 replica.lag.time.max.ms 和延迟条数 replica.lag.max.messages 两个维度, 当前最新的版本 0.10.x 中只支持 replica.lag.time.max.ms 这个维度
AR 默认情况下 Kafka 的 replica 数量为 1,即每个 partition 都有一个唯一的 leader,为了确保消息的可靠性,通常应用中将其值 (由 broker 的参数 offsets.topic.replication.factor 指定) 大小设置为大于 1,比如 3。 所有的副本(replicas)统称为 Assigned Replicas,即 AR。
ISR 是 AR 中的一个子集,由leader维护ISR
Kafka 0.10.x 版本后移除了 replica.lag.max.messages 参数,只保留了 replica.lag.time.max.ms 作为 ISR 中副本管理的参数。为什么这样做呢?
主要是峰值流量的影响,比如某一刻 producer瞬间发送很大的消息道broker,而这个时候follower都会被认为是lag的,剔除isr,后面有重新拉去,又回到了isr,所以造成了性能的浪费。
HW 俗称高水位,HighWatermark 的缩写,取一个 partition 对应的 ISR 中最小的 LEO 作为 HW,consumer只能消费到hw的位置,leader,和follower各自维护自己的hw,对于leader,producer发送消息后,不能立即更新hw,要等所有副本都同步后更新 hw
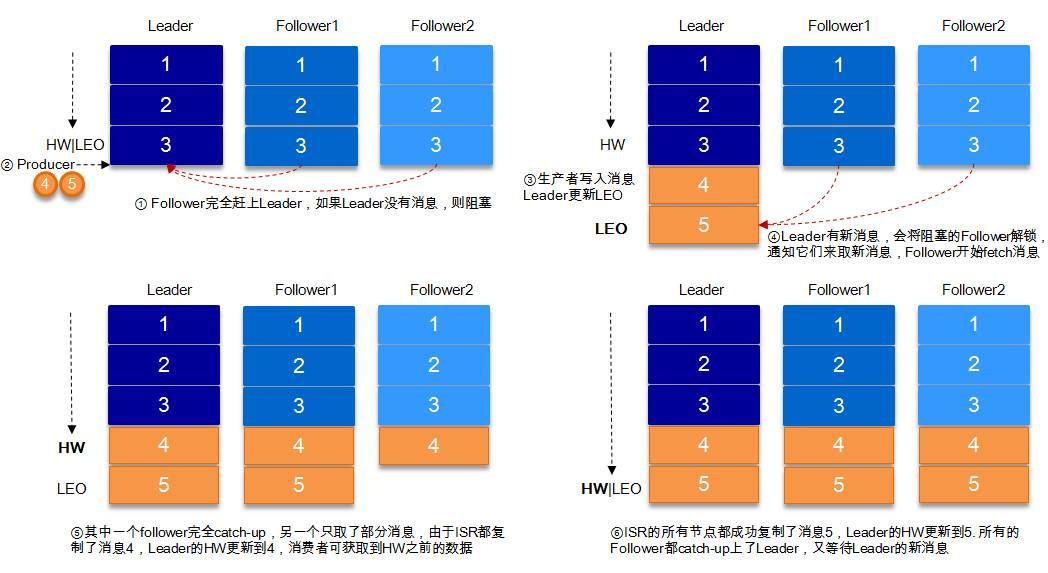
# 可靠性保障
request.required.acks 参数来设置数据可靠性的级别:
- 1 (默认) 只要leader收到了,就可以了,如果leader 挂掉了,就丢了
- 0 什么保证都没有,只管发送,吞吐量最高,但是可靠性最差
- -1(all) producer 需要等待 ISR 中的所有 follower 都确认接收到数据后才算一次发送完成,可靠性最高, 也不能保证数据完全不丢失,例如如果 ISR中只有leader,这就变成 acks=1的情况
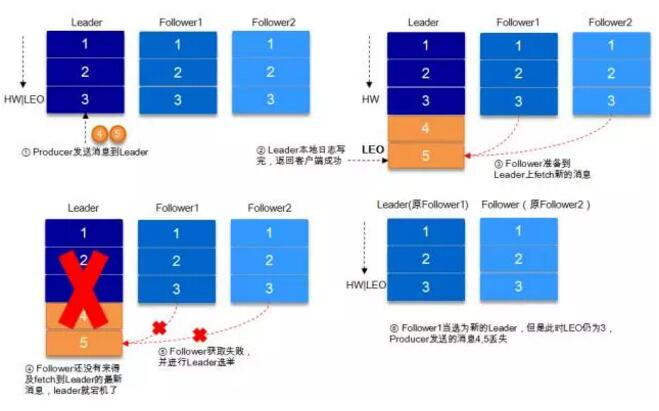
那么如何保证可靠性?
在设置 request.required.acks=-1 的同时,也要 min.insync.replicas 这个参数 (可以在 broker 或者 topic 层面进行设置) 的配合,这样才能发挥最大的功效
min.insync.replicas 这个参数设定 ISR 中的最小副本数是多少,默认为1,仅当 request.required.acks 参数设置为 -1 时,此参数才生效
如果 ISR 中的副本数少于 min.insync.replicas 配置的数量时,客户端会返回异常:org.apache.kafka.common.errors.NotEnoughReplicasExceptoin: Messages are rejected since there are fewer in-sync replicas than required。
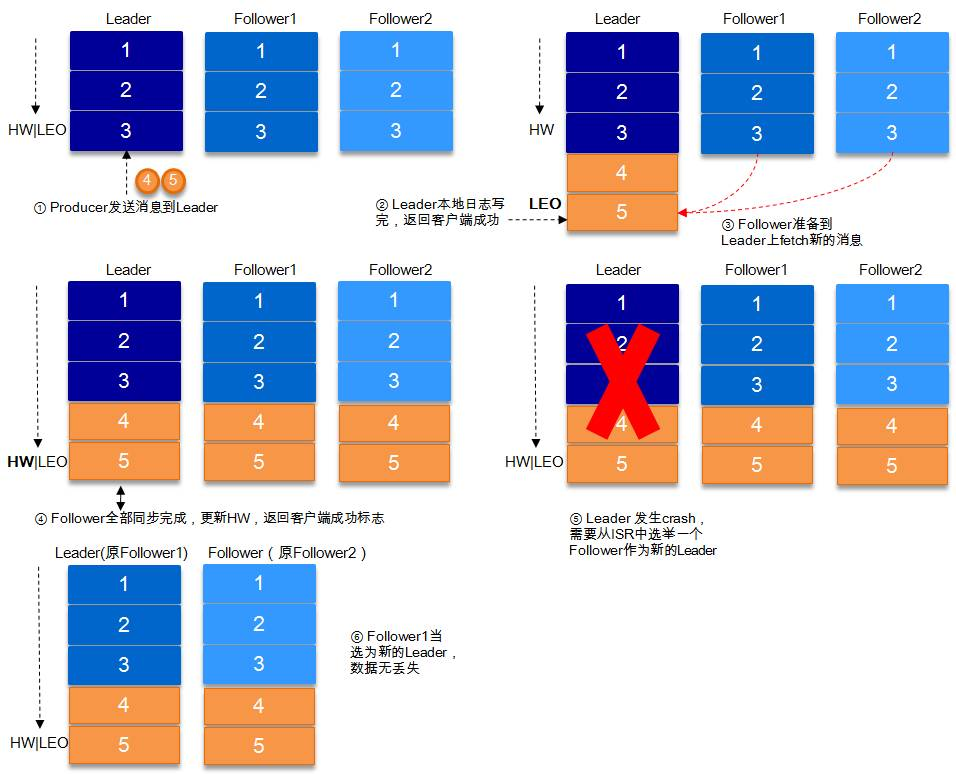
# request.required.acks=-1的两种情况
同步(Kafka 默认为同步,即 producer.type=sync)的发送模式,replication.factor>=2 且 min.insync.replicas>=2 的情况下,不会丢失数据。
情况1: acks=-1 的情况下,数据发送到 leader, ISR 的 follower 全部完成数据同步后,leader 此时挂掉,那么会选举出新的 leader,数据不会丢失。
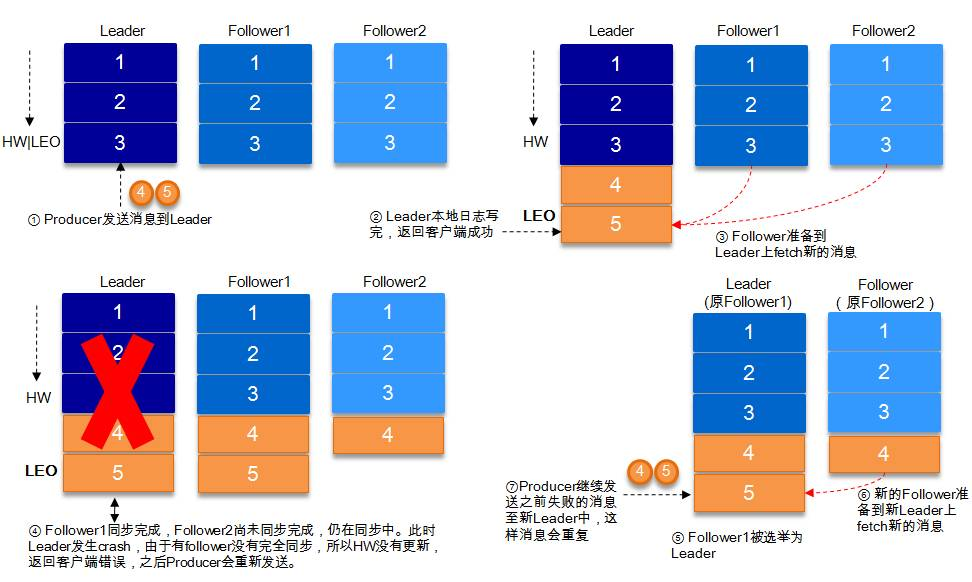
情况2: acks=-1 的情况下,数据发送到 leader 后 ,部分 ISR 的副本同步,leader 此时挂掉。f1 和 f2 都有可能变成leader,p发送异常,可能会重发数据,那么就重复了
← Kafka Kafka核心技术与实战 →