# 状态原理
# 参考
# Flink State 最佳实践
四个维度来区分两种不同的 state:operator state 以及 keyed state。
- 是否存在当前处理的 key(current key):operator state 是没有当前 key 的概念,而 keyed state 的数值总是与一个 current key 对应。
- 存储对象是否 on heap: 目前 operator state backend 仅有一种 on-heap 的实现;而 keyed state backend 有 on-heap 和 off-heap(RocksDB)的多种实现。
- 是否需要手动声明快照(snapshot)和恢复 (restore) 方法:operator state 需要手动实现 snapshot 和 restore 方法;而 keyed state 则由 backend 自行实现,对用户透明。
- 数据大小:一般而言,我们认为 operator state 的数据规模是比较小的;认为 keyed state 规模是相对比较大的。需要注意的是,这是一个经验判断,不是一个绝对的判断区分标准。
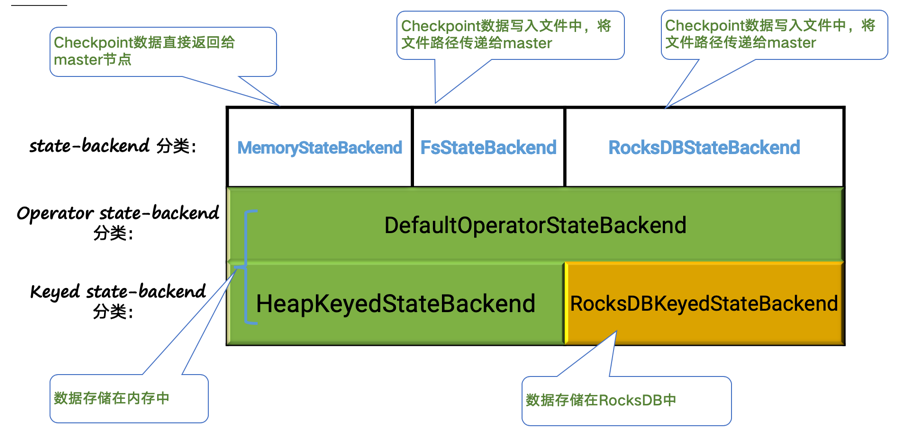
在生产中,我们会在 FsStateBackend 和 RocksDBStateBackend 间选择:
- FsStateBackend:性能更好;日常存储是在堆内存中,面临着 OOM 的风险,不支持增量 checkpoint。
- RocksDBStateBackend:无需担心 OOM 风险,是大部分时候的选择。
RocksDB
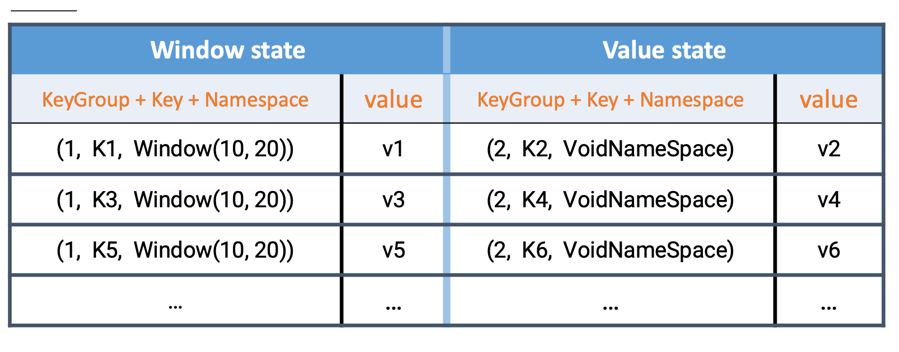
在 RocksDB 中,每个 state 独享一个 Column Family,而每个 Column family 使用各自独享的 write buffer 和 block cache,上图中的 window state 和 value state实际上分属不同的 column family。
配置
state.backend.rocksdb.thread.num 后台 flush 和 compaction 的线程数. 默认值 ‘1‘. 建议调大 state.backend.rocksdb.writebuffer.count 每个 column family 的 write buffer 数目,默认值 ‘2‘. 如果有需要可以适当调大 state.backend.rocksdb.writebuffer.size 每个 write buffer 的 size,默认值‘64MB‘. 对于写频繁的场景,建议调大 state.backend.rocksdb.block.cache-size 每个 column family 的 block cache大小,默认值‘8MB’,如果存在重复读的场景,建议调大
实践
# Operator state 使用建议
- 慎重使用长 list job master 就会因为收到 task 发来的“巨大”的 offset 数组,而内存不断增长直到超用无法正常响应
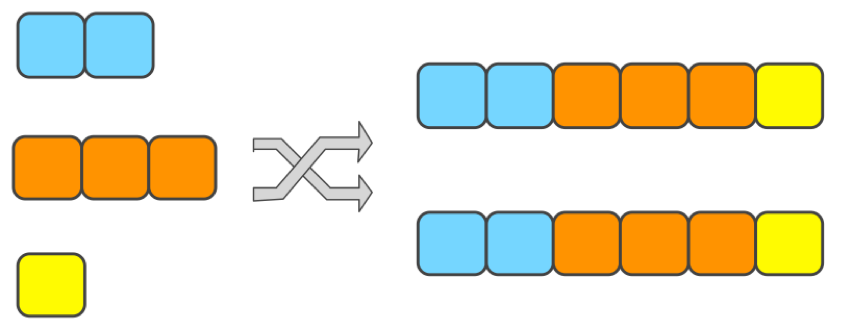
- 正确使用 UnionListState。
- union list state 目前被广泛使用在 kafka connector 中,不过可能用户日常开发中较少遇到,他的语义是从检查点恢复之后每个并发 task 内拿到的是原先所有operator 上的 state,如下图所示:
# Keyed state 使用建议
- 如何正确清空当前的 state
- state.clear() 只能清理当前key的state,如果想要清空整个 state,需要借助于 applyToAllKeys 方法

- state 有过期需求,借助于 state TTL
- 如何正确清空当前的 state
# 一些使用 checkpoint 的使用建议