# 开源动态
- 发布历史
- Feature
- Releases
- Bugs
- [[**FLINK-11457**] PrometheusPushGatewayReporter does not cleanup its metrics - ASF JIRA](https://issues.apache.org/jira/browse/FLINK-11457)
- [Apache Flink 中文用户邮件列表 - Prometheus pushgateway 监控 Flink metrics的问题](http://apache-flink.147419.n8.nabble.com/Prometheus-pushgateway-Flink-metrics-td3028.html#a3032)
- [[FLINK-13787] PrometheusPushGatewayReporter does not cleanup TM metrics when run on kubernetes - ASF JIRA](https://issues.apache.org/jira/browse/FLINK-13787)
# 发布历史
# Flink 1.8.0
Apache Flink: Apache Flink 1.8.0 Release Announcement (opens new window)
- 状态
- 连续增量的清理过期的 state 数据
- 状态恢复时的 schema 兼容性更强
- Savepoint 兼容性
- maven
- Flink 不再提供捆绑 Hadoop 包的发行版本
- Connectors (连接器)
- 增加 KafkaDeserializationSchema 能直接获取 kafka ConsumerRecord
- FlinkKafkaConsumer 将从恢复的数据中过滤不属于当前 topic 的 partition
# Flink 1.9.0
Apache Flink: Apache Flink 1.9.0 Release Announcement (opens new window)
The Apache Flink project’s goal is to develop a stream processing system to unify and power many forms of real-time and offline data processing applications as well as event-driven applications. In this release, we have made a huge step forward in that effort, by integrating Flink’s stream and batch processing capabilities under a single, unified runtime.
Fine-grained Batch Recovery (FLIP-1)
- Until Flink 1.9, task failures in batch jobs were recovered by canceling all tasks and restarting the whole job
- FLIP-1 : Fine Grained Recovery from Task Failures - Apache Flink - Apache Software Foundation (opens new window)
State Processor API (FLIP-43)
Stop-with-Savepoint (FLIP-34)
bin/flink stop -p [:targetDirectory] :jobId
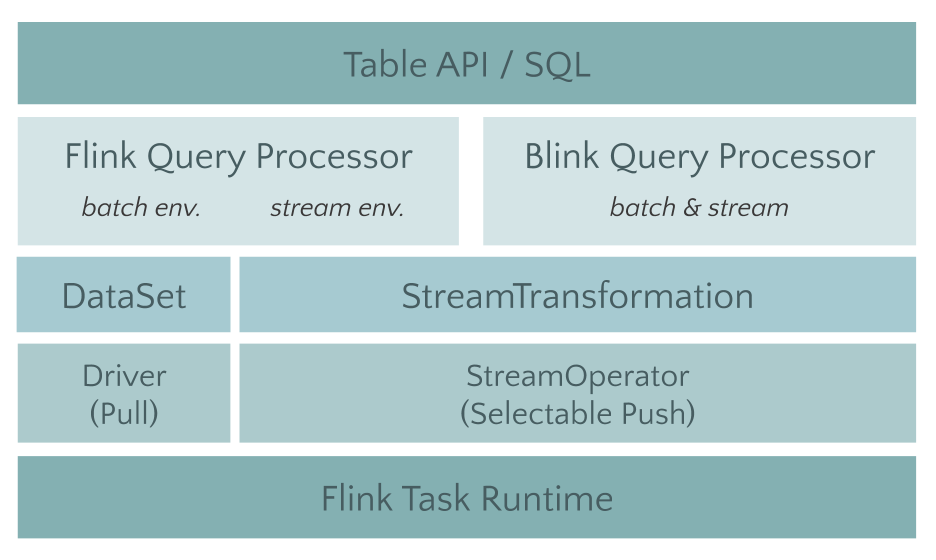
Preview of the new Blink SQL Query Processor
Other Improvements to the Table API and SQL
- Scala-free Table API and SQL for Java users (FLIP-32)
- Rework of the Table API Type System (FLIP-37)
Preview of Full Hive Integration (FLINK-10556)
- you will also be able to persist metadata of Flink tables in Metastore
# Feature
# [FLINK-9187] add prometheus pushgateway reporter - ASF JIRA (opens new window)
# FLIP-44: Support Local Aggregation in Flink - Apache Flink - Apache Software Foundation (opens new window)
# Releases
Flink 1.12 Release 文档解读 - osc_zyjrm8ih的个人空间 - OSCHINA - 中文开源技术交流社区 (opens new window)
# Bugs
# [FLINK-11457] PrometheusPushGatewayReporter does not cleanup its metrics - ASF JIRA (opens new window)
- 描述
取消在基于yarn-cluster的群集上运行的作业,然后关闭群集时,不会删除推送网关上的指标*
- 结论
通过调度程序来删除pushgateway上面的指标
In our product env, we also met the same problem. If pushgateway can implements TTL for pushed metrics[1], it'll very useful. But for now, we use a external schedule system to check whether the flink job is alive or not, then delete metrics by pushgateway's rest api[2].
[1]https://github.com/prometheus/pushgateway/issues/19
[2]https://github.com/prometheus/pushgateway#delete-method
# Apache Flink 中文用户邮件列表 - Prometheus pushgateway 监控 Flink metrics的问题 (opens new window)
描述
flink上报指标到pushgateway,然后被prometheus拉取,grafana做展示显示异常,断断续续
相同问题
结论
虽然我们所用到的flink taskmanager metrics指标发生了中断,但是可以看到pushgateway中的flink jobmanager metrics都还在,且taskmanager metrics存在时,无法查到jobmanager metrics,jobmanager metrics存在时,无法查到taskmanager metrics,两者虽然处于同一个group(pushgateway中的概念,与推送URL相关)下,但是貌似无法同时查到
意即,如果以group为单位使用put方法往pushgateway发数据,则新数据会全盘覆盖老数据,不管metrics name是否相同;如果以group为单位使用post方法往pushgateway发数据,则同一metrics name的新数据会覆盖老数据。根据实验中jobmanager metrics和taskmanager metrics不能兼容的现象,很合理地猜测,当我们所需要的taskmanager metrics消失时,是因为jobmanager metrics使用了PUT的指标推送方式而将taskmanager metrics全盘覆盖了
- 根据 Apache Flink 中文用户邮件列表 - Prometheus Pushgateway 监控 Flink 问题 (opens new window) 设置 randomSuffix为true