# Hadoop
- Mapreduce
- Mapreduce的过程
- 谈谈数据倾斜,如何发生的,并给出优化方案
- 简单概述hadoop的combine与partition的区别
- MapReduce 中排序发生在哪几个阶段?这些排序是否可以避免?为什么?
- hadoop的shuffer的概念
- hadoop的二次排序
- 如何减少Hadoop Map端到Reduce端的数据传输量?
- hadoop常见的链接join操作?
- 简答说一下hadoop的map-reduce编程模型
- hadoop的TextInputFormat作用是什么,如何自定义实现
- hadoop和spark的都是并行计算,那么他们有什么相同和区别
- map-reduce程序运行的时候会有什么比较常见的问题
- WritableComparator 如何使用
- 其他问题
- Hadoop运维
# Mapreduce
# Mapreduce的过程
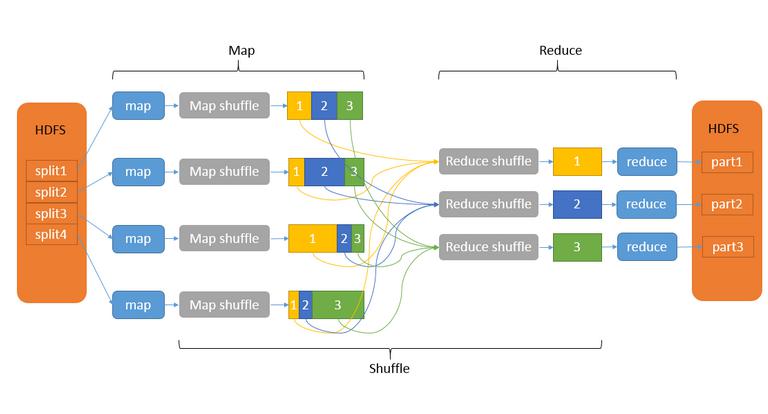
- 由算个阶段构成 Map、shuffle、Reduce
- Map 是映射,将原始数据转换为键值对
- Reduce 是合并,将相同的key值得value进行处理后在输出新的键值对作为最终结果
- 为了让Reduce可以并行处理Map的结果,必须对Map的输出进行一定的排序与分割
- 将Map输出进行进一步整理并交给Reduce的过程就是Shuffle
- MapReduce shuffle过程详解 (opens new window)
# 谈谈数据倾斜,如何发生的,并给出优化方案
集群中,某个map任务的key对应的value值远远大于其他节点的key所对应的值,导致某个节点mapreduce执行效率很慢,解决根本方法就是避免某个节点上执行任务数据量过大,可以使用map阶段的partiion对过大的数据进行分区,大数据块分成小数据块
造成数据倾斜的原因:
- 分组 注:group by 优于distinct group
- 情形:group by 维度过小,某值的数量过多
- 后果:处理某值的reduce非常耗时
- 去重 distinct count(distinct xx)
- 情形:某特殊值过多
- 后果:处理此特殊值的reduce耗时。
- 连接 join
- 情形1:其中一个表较小,但是key集中。
- 后果1:分发到某一个或几个Reduce上的数据远高于平均值
- 情形2:大表与大表,但是分桶的判断字段0值或空值过多
- 后果2:这些空值都由一个reduce处理,非常慢。
Hive join 数据倾斜
- set hive.map.aggr=true; map端做部分聚合操作,效率高,需要更多内存
- set hive.groupby.skewindata=true; 生成两个 MRjob
- 第一个MRJob 中,Map的输出结果集合会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的GroupBy Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的
- 第二个MRJob再根据预处理的数据结果按照GroupBy Key分布到Reduce中(这个过程可以保证相同的GroupBy Key被分布到同一个Reduce中),最后完成最终的聚合操作。
在 key 上面做文章,在 map 阶段将造成倾斜的key 先分成多组,例如 aaa 这个 key,map 时随机在 aaa 后面加上 1,2,3,4 这四个数字之一,把 key 先分成四组,先进行一次运算,之后再恢复 key 进行最终运算
# 简单概述hadoop的combine与partition的区别
- combine分为map端和reduce端,作用是把同一个key的键值对合并在一起,可以自定义的。减少网络 传输
- partition是分割map每个节点的结果,按照key分别映射给不同的reduce
# MapReduce 中排序发生在哪几个阶段?这些排序是否可以避免?为什么?
- 一个MapReduce作业由Map阶段和Reduce阶段两部分组成,这两阶段会对数据排序
- MapReduce框架本质就是一个Distributed Sort
- Map阶段,Map Task会在本地磁盘输出一个按照key排序(采用的是快速排序)的文件(中间可能产生多个文件,但最终会合并成一个)
- 在Reduce阶段,每个Reduce Task会对收到的数据排序
- Map阶段的排序就是为了减轻Reduce端排序负载
- sort对后续操作有何好处 而是这个sort为许多应用和后续应用开发带来很多好处 试想分布式计算框架不提供排序 要你自己排 真是哇哇叫 谁还用
- https://www.zhihu.com/question/35999547/answer/65443663 (opens new window)
- https://blog.csdn.net/play_chess_ITmanito/article/details/51089200 (opens new window)
# hadoop的shuffer的概念
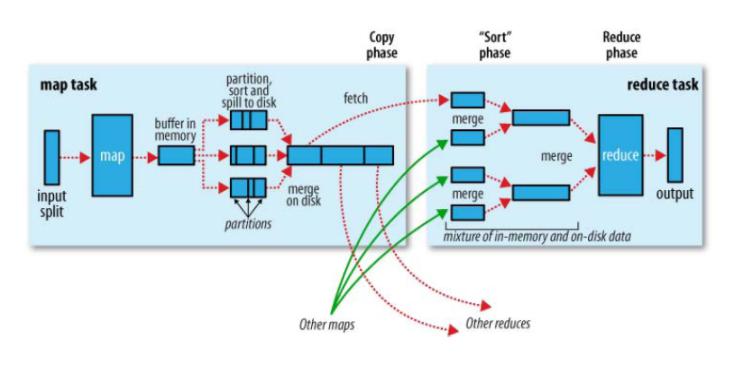
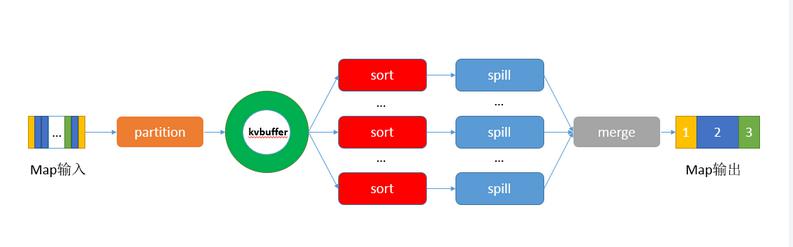
- MapReduce:详解Shuffle(copy,sort,merge)过程 (opens new window)
- Shuffle的正常意思是洗牌或弄乱
- shuffle针对多个map任务的输出按照不同的分区(Partition)通过网络复制到不同的reduce任务节点上,这个过程就称作为Shuffle。
- Map端三个步骤
- map函数产生key value对,输出先放入缓存,缓存区默认100MB(io.sort.mb),达到0.8阀值,spill到本次磁盘(mappred.local.dir)新建一个溢写文件
- 写磁盘钱,进行partition sort combine 分区 不同类型分开处理,对不同分区的数据进行排序,排序后的进行combine,最后记录写完,合并为一个分区并排序的文件
- 等待reducer来拉去
- Reduce端
- Copy阶段,通过http拉取,从n个map中拉取,速度不尽相同,有的还没弄完
- Merge阶段 http拉取来的放入缓存,达到阈值写入磁盘,同样进行partition combine、排序等过程。多个文件也会合并,最后一次合并作为reduce最终输入
- 传入到reduce任务当中
- Hadoop-Shuffle过程 (opens new window)
# hadoop的二次排序
- Hadoop MapReduce 二次排序原理及其应用
- 在0.20.0以前使用的是 setPartitionerClass setOutputkeyComparatorClass setOutputValueGroupingComparator
- 在0.20.0以后使用是
job.setPartitionerClass(Partitioner p);
job.setSortComparatorClass(RawComparator c);
job.setGroupingComparatorClass(RawComparator c);
setGroupingComparatorClass
就是通过一个comparator比较两个值是否返回0,如果是0,则就表示是一个组中的。 然后开始构造一个key对应的value迭代器。这时就要用到分组,使用jobjob.setGroupingComparatorClass设置的分组函数类。只要这个比较器比较的两个key相同,他们就属于同一个组,它们的value放在一个value迭代器,而这个迭代器的key使用属于同一个组的所有key的第一个key 如果不用分组,那么同一组的记录就要在多次reduce方法中独立处理,那么有些状态数据就要传递了,就会增加复杂度,在一次调用中处理的话,这些状态只要用方法内的变量就可以的。比如查找最大值,只要读第一个值就可以了。

- 参考
# 如何减少Hadoop Map端到Reduce端的数据传输量?
# hadoop常见的链接join操作?
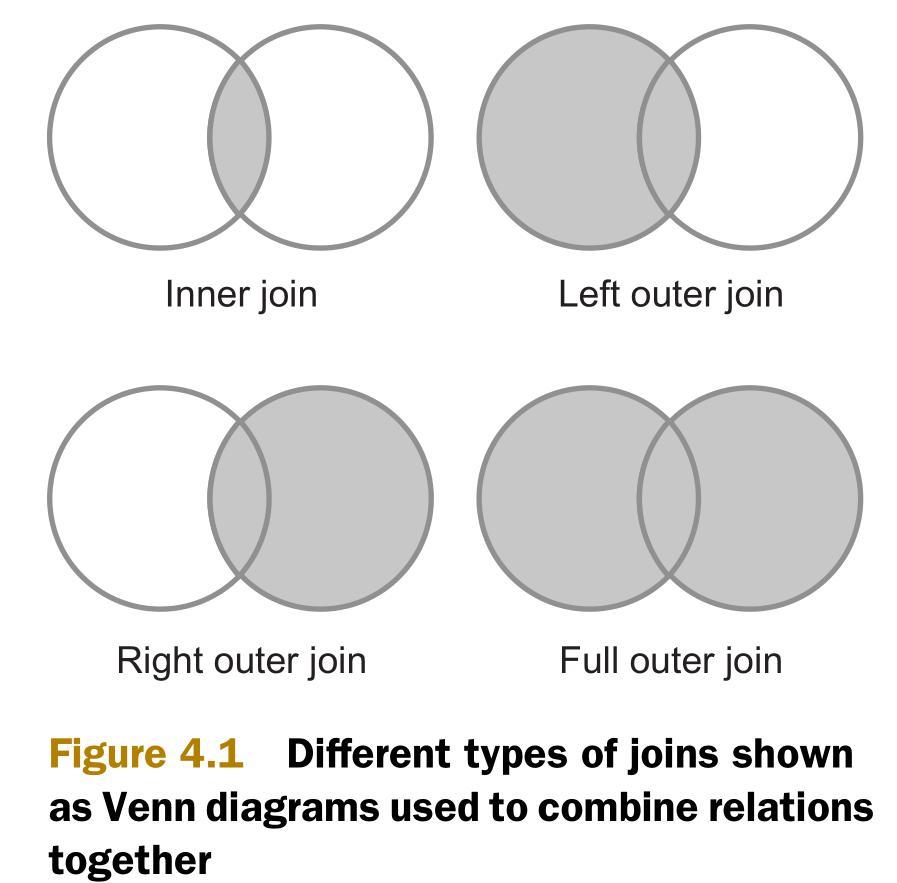
为了实现内连接和外连接,MapReduce中有三种连接策略,如下所示。这三种连接策略有的在map阶段,有的在reduce阶段。它们都针对MapReduce的排序-合并(sort-merge)的架构进行了优化。
- 重分区连接(Repartition join)—— reduce端连接。使用场景:连接两个或多个大型数据集。
- 复制连接(Replication join)—— map端连接。使用场景:待连接的数据集中有一个数据集足够小到可以完全放在缓存中。
- 半连接(Semi-join)—— 另一个map端连接。使用场景:待连接的数据集中有一个数据集非常大,但同时这个数据集可以被过滤成小到可以放在缓存中。
Reduce side join
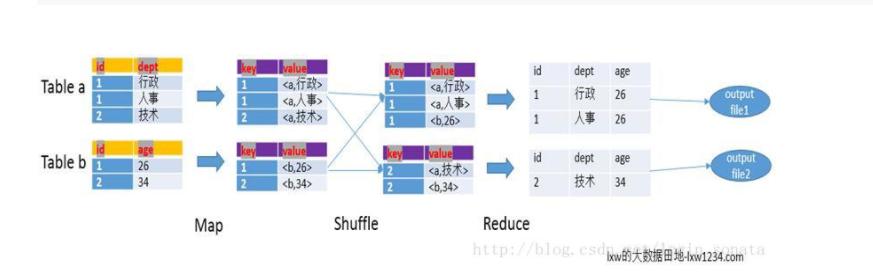
- Map阶段 读取源表的数据,Map输出时候以Join on条件中的列为key,如果Join有多个关联键,则以这些关联键的组合作为key;Map输出的value为join之后所关心的(select或者where中需要用到的)列,同时在value中还会包含表的Tag信息,用于标明此value对应哪个表。
- Shuffle阶 根据key的值进行hash,并将key/value按照hash值推送至不同的reduce中,这样确保两个表中相同的key位于同一个reduce中。
- Reduce阶段 根据key的值完成join操作,期间通过Tag来识别不同表中的数据。
Map Side join
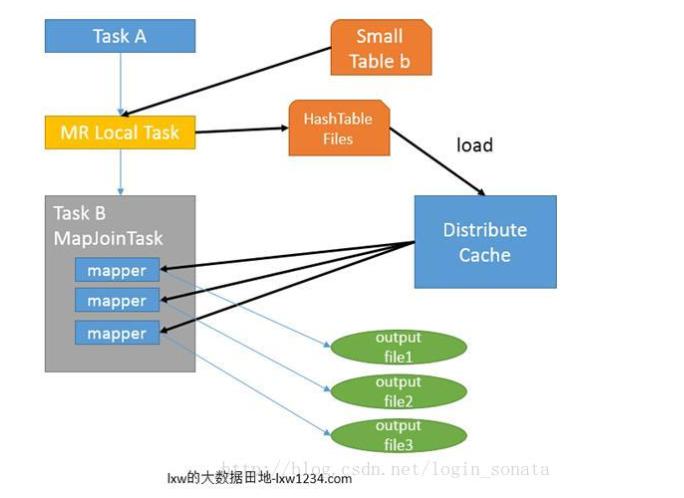
- 没有reduce 直接输出结果
- 独立task 读取小表 放入 DistributeCache
SemiJoin 半连接 SemiJoin,也叫半连接,是从分布式数据库中借鉴过来的方法。它的产生动机是:对于reduce side join,跨机器的数据传输量非常大,这成了join操作的一个瓶颈,如果能够在map端过滤掉不会参加join操作的数据,则可以大大节省网络IO。 实现方法很简单:选取一个小表,假设是File1,将其参与join的key抽取出来,保存到文件File3中,File3文件一般很小,可以放到内存中。在map阶段,使用DistributedCache将File3复制到各个TaskTracker上,然后将File2中不在File3中的key对应的记录过滤掉,剩下的reduce阶段的工作与reduce side join相同。
大牛翻译系列Hadoop(3)MapReduce 连接:半连接(Semi-join) (opens new window) 4. reduce side join + BloomFilter 在某些情况下,SemiJoin抽取出来的小表的key集合在内存中仍然存放不下,这时候可以使用BloomFiler以节省空间。 BloomFilter 最常见的作用是:判断某个元素是否在一个集合里面。它最重要的两个方法是:add() 和contains()。最大的特点是不会存在false negative,即:如果contains()返回false,则该元素一定不在集合中,但会存在一定的true negative,即:如果contains()返回true,则该元素可能在集合中。 因而可将小表中的key保存到BloomFilter中,在map阶段过滤大表,可能有一些不在小表中的记录没有过滤掉(但是在小表中的记录一定不会过滤掉),这没关系,只不过增加了少量的网络IO而已。 更多关于BloomFilter的介绍,可参考:Bloom Filter概念和原理 - CSDN博客 (opens new window)
# 简答说一下hadoop的map-reduce编程模型
- map task会从本地文件系统读取数据,转换成key-value形式的键值对集
- 使用的是hadoop内置的数据类型,比如longwritable、text等
- 将键值对集合输入mapper进行业务处理过程,将其转换成需要的key-value在输出
- 之后会进行一个partition分区操作,默认使用的是hashpartitioner,可以通过重写hashpartitioner的getpartition方法来自定义分区规则
- 之后会对key进行进行sort排序,grouping分组操作将相同key的value合并分组输出,在这里可以使用自定义的数据类型,重写WritableComparator的Comparator方法来自定义排序规则,重写RawComparator的compara方法来自定义分组规则
- 之后进行一个combiner归约操作,其实就是一个本地段的reduce预处理,以减小后面shufle和reducer的工作量
- reduce task会通过网络将各个数据收集进行reduce处理,最后将数据保存或者显示,结束整个job
# hadoop的TextInputFormat作用是什么,如何自定义实现
InputFormat会在map操作之前对数据进行两方面的预处理
- 是 getSplits ,返回的是InputSplit数组,对数据进行split分片,每片交给map操作一次
- 是getRecordReader,返回的是RecordReader对象,对每个split分片进行转换为key-value键值对格式传递给map
常用的InputFormat是TextInputFormat,使用的是LineRecordReader对每个分片进行键值对的转换,以行偏移量作为键,行内容作为值 自定义类继承InputFormat接口,重写createRecordReader和isSplitable方法 在createRecordReader中可以自定义分隔符
# hadoop和spark的都是并行计算,那么他们有什么相同和区别
- 相同点
- 都是用mr模型来进行并行计算
- 不同点
- hadoop的一个作业称为job,job里面分为map task和reduce task,每个task都是在自己的进程中运行的,当task结束时,进程也会结束
- spark用户提交的任务成为application,一个application对应一个sparkcontext,app中存在多个job,每触发一次action操作就会产生一个job,每个job中有多个stage,stage是shuffle过程中DAGSchaduler通过RDD之间的依赖关系划分job而来的,每个stage里面有多个task,组成taskset有TaskSchaduler分发到各个executor中执行
- hadoop的job只有map和reduce操作,表达能力比较欠缺而且在mr过程中会重复的读写hdfs,造成大量的io操作,多个job需要自己管理关系
- spark的迭代计算都是在内存中进行的,API中提供了大量的RDD操作如join,groupby等,而且通过DAG图可以实现良好的容错
# map-reduce程序运行的时候会有什么比较常见的问题
比如说作业中大部分都完成了,但是总有几个reduce一直在运行 这是因为这几个reduce中的处理的数据要远远大于其他的reduce,可能是因为对键值对任务划分的不均匀造成的数据倾斜 解决的方法可以在分区的时候重新定义分区规则对于value数据很多的key可以进行拆分、均匀打散等处理,或者是在map端的combiner中进行数据预处理的操作
# WritableComparator 如何使用
# 其他问题
# 简单概述hadoop中的角色的分配以及功能
# hadoop的优化(性能调优)
hadoop性能调优与运维 - CSDN博客 (opens new window)
# hadoop1与hadoop2的区别
Hadoop1.X 与 Hadoop2.X区别及改进 - 奥斯卡影帝 - 博客园 (opens new window)
Hadoop1.x与Hadoop2的区别 - Szz - 博客园 (opens new window)
Hadoop1.x的MapReduce框架的主要局限:
(1)JobTracker 是 Map-reduce 的集中处理点,存在单点故障;
(2)JobTracker 完成了太多的任务,造成了过多的资源消耗,当 map-reduce job 非常多的时候,会造成很大的内存开销,潜在来说,也增加了 JobTracker 失效的风险,这也是业界普遍总结出老 Hadoop 的 Map-Reduce 只能支持 4000 节点主机的上限;
Hadoop2中新方案:YARN+MapReduce
首先的不要被YARN给迷惑住了,它只是负责资源调度管理。而MapReduce才是负责运算的家伙,所以YARN != MapReduce2.
YARN 并不是下一代MapReduce(MRv2),下一代MapReduce与第一代MapReduce(MRv1)在编程接口、数据处理引擎(MapTask和ReduceTask)是完全一样的, 可认为MRv2重用了MRv1的这些模块,不同的是资源管理和作业管理系统,MRv1中资源管理和作业管理均是由JobTracker实现的,集两个功能于一身,而在MRv2中,将这两部分分开了。 其中,作业管理由ApplicationMaster实现,而资源管理由新增系统YARN完成,由于YARN具有通用性,因此YARN也可以作为其他计算框架的资源管理系统,不仅限于MapReduce,也是其他计算框架(例如Spark)的管理平台。
该架构将JobTracker中的资源管理及任务生命周期管理(包括定时触发及监控),拆分成两个独立的服务, 用于管理全部资源的ResourceManager以及管理每个应用的ApplicationMaster, ResourceManager用于管理向应用程序分配计算资源,每个ApplicationMaster用于管理应用程序、调度以及协调
# hadoop3的新特性
hadoop3.0新特性 - CSDN博客 (opens new window) Hadoop 3.x 新特性剖析系列1 - 哥不是小萝莉 - 博客园 (opens new window)
# hadoop中两个大表实现join的操作,简单描述?
# hadoop 是什么?
Hadoop是在分布式服务器集群上存储海量数据并运行分布式分析应用的一个平台,其核心部件是HDFS与MapReduce
HDFS是一个分布式文件系统:传统文件系统的硬盘寻址慢,通过引入存放文件信息的服务器Namenode和实际存放数据的服务器Datanode进行串接。对数据系统进行分布式储存读取。
MapReduce是一个计算框架:MapReduce的核心思想是把计算任务分配给集群内的服务器里执行。通过对计算任务的拆分(Map计算\Reduce计算)再根据任务调度器(JobTracker)对任务进行分布式计算。
# Hadoop运维
# 杀死一个job?
yarn job -list yarn application -kill jobId
# 删除hdfs上的/tmp/aaa目录
- hadoop fs -rm hdfs://host:port/file /user/hadoop/emptydir 3.加入一个新的存储节点和删除一个计算节点需要刷新集群状态命令?
# hadoop 集群 加入一个新的存储节点和删除一个计算节点需要刷新集群状态命令
方式1:静态添加datanode,停止namenode方式
1.停止namenode 2.修改slaves文件,并更新到各个节点 3.启动namenode 4.执行hadoop balance命令。(此项为balance集群使用,如果只是添加节点,则此步骤不需要)
方式2:动态添加datanode,不停namenode方式
1.修改slaves文件,添加需要增加的节点host或者ip,并将其更新到各个节点 2.在datanode中启动执行启动datanode命令。命令:sh hadoop-daemon.sh start datanode 3.可以通过web界面查看节点添加情况。或使用命令:sh hadoop dfsadmin -report 4.执行hadoop balance命令。(此项为balance集群使用,如果只是添加节点,则此步骤不需要)
hadoop 集群 加入一个新的存储节点和删除一个计算节点需要刷新集群状态命令 - CSDN博客 (opens new window)