# HDFS
- hdfs怎么新增结点和删除结点?
- hdfs如果一台结点挂了,会有什么结果?十台呢?错误丢失概率是多少?
- hdfs 是什么
- hdfs 的数据压缩算法
- 文件大小默认为 64M,改为 128M 有啥影响,bloack大小为什么增大默认为128M
- 讲述HDFS上传文件和读文件的流程?
- 读数据流程
- 写数据流程
- HDFS在上传文件的时候,如果其中一个块突然损坏了怎么办?(读取文件的异常处理)
- HDFS NameNode 和 DataNode 之间是如何通信,如何协作的?
- HDFS和HBase各自使用场景
- Hadoop namenode的ha,主备切换实现原理,日志同步原理,QJM中用到的分布式一致性算法(就是paxos算法)
- 为什么HDFS 块为64MB或者128MB
- 名称节点 数据节点 和 SecondaryNameNode
- HDFS SecondaryNameNode和HA(高可用)区别
# hdfs怎么新增结点和删除结点?
# 参考
Hadoop动态扩容,增加节点-华为云 (opens new window)
# 新增节点 hadoop-daemon.sh start datanode # 查看集群情况 hdfs dfsadmin -report # 数据传输带宽比较低,可以设置为64M hdfs dfsadmin -setBalancerBandwidth 67108864 sbin/start-balancer.sh -threshold 5
Hadoop记录-Hadoop集群添加节点和删除节点 - 信方 - 博客园 (opens new window)
# A:修改Name节点的hdfs-site.xml增加 <property> <name>dfs.hosts.exclude</name> <value>/soft/hadoop/conf/excludes</value> </property> # B:修改Name节点的mapred-site.xml增加 <property> <name>mapred.hosts.exclude</name> <value>/soft/hadoop/conf/excludes</value> <final>true</final> </property> # C:新建excludes文件,文件里写要删除节点的hostname # D:Name节点执行 hadoop mradmin –refreshNodes hadoop dfsadmin –refreshNodes<br>(task进程可以kill进程ID) # 查看关闭进程 hadoop dfsadmin -report # 当节点处于Decommissioned,表示关闭成功。
# hdfs如果一台结点挂了,会有什么结果?十台呢?错误丢失概率是多少?
# 参考
# hdfs 是什么
Hadoop 自带的一个分布式文件系统,Hadoop Distribut File System 流式数据访问模式来存储超大文件
- 超大文件
- 流式数据访问 一次写入、多次读取
- 商用硬件廉价的机器上
- 不支持低延迟,如果需要,使用Hbase
- 不适合大量小文件 对namenode压力太大
- 只支持单用户写入,只支持添加到末尾
# hdfs 的数据压缩算法
使用压缩的优点如下:
- 节省数据占用的磁盘空间;
- 加快数据在磁盘和网络中的传输速度,从而提高系统的处理速度。
Hadoop 对于压缩格式的是自动识别 。如果我们压缩的文件有相应压缩格式的扩展名(比如 lzo,gz,bzip2 等)。Hadoop 会根据压缩格式的扩展名自动选择相对应的解码器来解压数据,此过程完全是 Hadoop 自动处理,我们只需要确保输入的压缩文件有扩展名。
如果压缩的文件没有扩展名,则需要在执行 MapReduce 任务的时候指定输入格式。
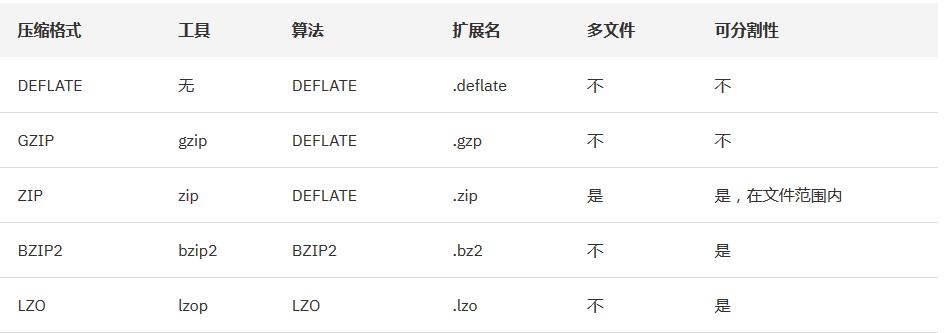
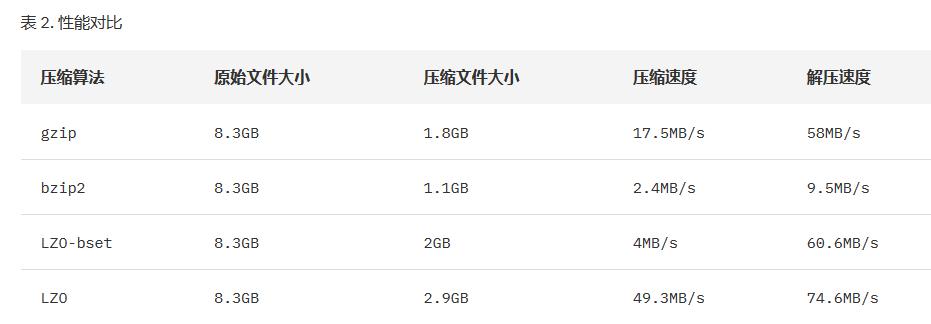
因此我们可以得出
Bzip2 压缩效果明显是最好的,但是 bzip2 压缩速度慢,可分割。
Gzip 压缩效果不如 Bzip2,但是压缩解压速度快,不支持分割。
LZO 压缩效果不如 Bzip2 和 Gzip,但是压缩解压速度最快!并且支持分割!
文件的可分割性在 Hadoop 中是很非常重要的,它会影响到在执行作业时 Map 启动的个数,从而会影响到作业的执行效率!
Hadoop 压缩实现分析 (opens new window)
HADOOP与HDFS数据压缩格式 - 简书 (opens new window)
# 文件大小默认为 64M,改为 128M 有啥影响,bloack大小为什么增大默认为128M
- 减轻了namenode的压力 原因是hadoop集群在启动的时候,datanode会上报自己的block的信息给namenode。namenode把这些信息放到内存中。那么如果块变大了,那么namenode的记录的信息相对减少,所以namenode就有更多的内存去做的别的事情,使得整个集群的性能增强。
- 增大会不会带来负面相应。 因为这个可以灵活设置,所以这里不是问题。关键是什么时候,该如何设置。 如果对于数两级别为PB的话,建议可以block设置的大一些。 如果数据量相对较少,可以设置的小一些64M也未尝不可。
- 参考
# 讲述HDFS上传文件和读文件的流程?
# 读数据流程
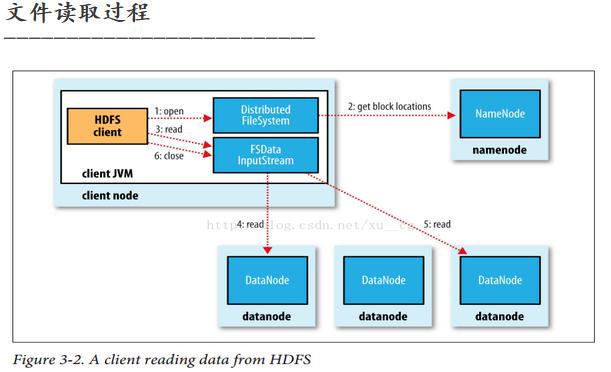
- 客户端(Client)调用FileSystem的open()函数打开文件。
- DistributeFileSystem通过RPC调用元数据节点,得
- 到文件的数据块信息。 对于每一个数据块,元数据节点返回数据块的数据节点位置。
- DistributedFileSystem返回FSDataInputStream给客户端,用来读取数据。客户端调用stream的read()方法读取数据。
- FSDataInputStream连接保存此文件第一个数据块的 最近的数据节点 ,Data从数据节点读到客户端(Client)。
- 当此数据块读取完毕后,FSDataInputStream关闭和此数据节点的连接,然后读取保存下一个数据块的最近的数据节点。
- 当数据读取完毕后,调用FSDataInputStream的close()函数。
- 在数据读取过程中,如果客户端在与数据节点通信时出现错误, 则会尝试读取包含有此数据块的下一个数据节点 ,并且失败的数据节点会被记录,以后不会再连接
# 写数据流程
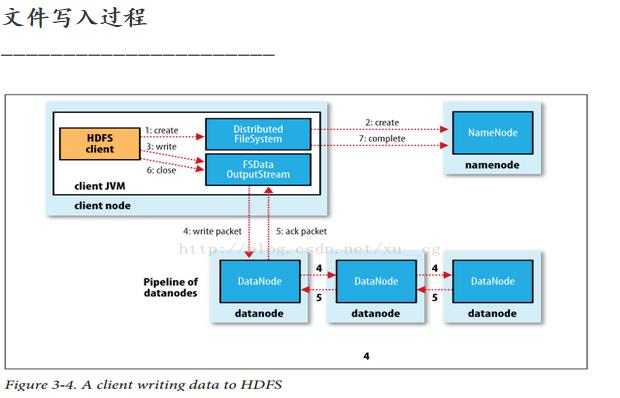
- 客户端调用create()函数创建文件。
- DistributedFileSystem通过RPC调用 元数据节点 ,在文件系统的 命名空间 中创建一个新的文件。元数据节点会首先确定文件原先不存在,并且客户端有创建文件的权限,然后创建新文件。
- DistributedFileSystem返回FSDataOutputStream,客户端用于写数据。
- FSDataOutputStream将数据分成块 ,写入Data Queue。Data Queue由Data Streamer读取,并通知元数据节点分配数据节点用来存储数据块(每块默认复制3份)。分配的数据节点放在一个Pipeline中。Data Streamer将数据块写入Pipeline中的第一个数据节点;第一个数据节点再将数据块发送给第二个数据节点;第二个数据节点再将数据发送给第三个数据节点。
- FSDataoutputStream为发出去的数据块保存了 ACK Queue ,等待Pipeline中的数据节点告知数据已成功写入。如果数据节点在写入过程中失败了,则关闭Pipeline,将Ack Queue中的数据块放入到Data Queue的开始。
- 当前数据块在已经写入的数据节点中会被元数据节点赋予新的标识,则错误节点重启后能察觉到其数据块是过时的,将会被删除。失败的数据节点从Pipeline中移除,另外的数据块则写入Pipeline中的另外两个数据节点。元数据节点则被通知此数据块复制块数不足,将来会再创建第三份备份。
- 当客户端结束写入数据后,则调用stream的close()方法。此操作将所有的数据块写入pipeline中的数据节点,并等待ACK Queue成功返回。最后通知元数据节点写入完毕。
参考
# HDFS在上传文件的时候,如果其中一个块突然损坏了怎么办?(读取文件的异常处理)
HDFS 异常处理与恢复 - mindwind - 博客园 (opens new window)
# HDFS NameNode 和 DataNode 之间是如何通信,如何协作的?
client和namenode之间是通过rpc通信; datanode和namenode之间是通过rpc通信; client和datanode之间是通过简单的socket通信;
# HDFS和HBase各自使用场景
HBase作为面向列的数据库运行在HDFS之上,HDFS缺乏随即读写操作,HBase正是为此而出现,以键值对的形式存储。项目的目标就是快速在主机内数十亿行数据中定位所需的数据并访问它。 HBase是一个数据库,一个NoSql的数据库,像其他数据库一样提供随即读写功能,Hadoop不能满足实时需要,HBase正可以满足。如果你需要实时访问一些数据,就把它存入HBase
# 什么场景下应用Hbase
- 成熟的数据分析主题,查询模式已经确立,并且不会轻易改变。
- 传统的关系型数据库已经无法承受负荷,高速插入,大量读取。
- 适合海量的,但同时也是简单的操作(例如:key-value)。
- 半结构化或非结构化数据 对于数据结构字段不够确定或杂乱无章很难按一个概念去进行抽取的数据适合用HBase。以上面的例子为例,当业务发展需要存储author的email,phone,address信息时RDBMS需要停机维护,而HBase支持动态增加.
- 记录非常稀疏 RDBMS的行有多少列是固定的,为null的列浪费了存储空间。而如上文提到的,HBase为null的Column不会被存储,这样既节省了空间又提高了读性能。
- 多版本数据 如上文提到的根据Row key和Column key定位到的Value可以有任意数量的版本值,因此对于需要存储变动历史记录的数据,用HBase就非常方便了。比如上例中的author的Address是会变动的,业务上一般只需要最新的值,但有时可能需要查询到历史值。
- 超大数据量 当数据量越来越大,RDBMS数据库撑不住了,就出现了读写分离策略,通过一个Master专门负责写操作,多个Slave负责读操作,服务器成本倍增。随着压力增加,Master撑不住了,这时就要分库了,把关联不大的数据分开部署,一些join查询不能用了,需要借助中间层。随着数据量的进一步增加,一个表的记录越来越大,查询就变得很慢,于是又得搞分表,比如按ID取模分成多个表以减少单个表的记录数。经历过这些事的人都知道过程是多么的折腾。采用HBase就简单了,只需要加机器即可,HBase会自动水平切分扩展,跟Hadoop的无缝集成保障了其数据可靠性(HDFS)和海量数据分析的高性能(MapReduce)。
# hadoop主要应用于数据量大的离线场景特征为:
- 数据量大。一般真正线上用Hadoop的,集群规模都在上百台到几千台的机器。这种情况下,T级别的数据也是很小的。Coursera上一门课了有句话觉得很不错:Don't use hadoop, your data isn't that big
- 离线。Mapreduce框架下,很难处理实时计算,作业都以日志分析这样的线下作业为主。另外,集群中一般都会有大量作业等待被调度,保证资源充分利用。
- 数据块大。由于HDFS设计的特点,Hadoop适合处理文件块大的文件。大量的小文件使用Hadoop来处理效率会很低。举个例子,百度每天都会有用户对侧边栏广告进行点击。这些点击都会被记入日志。然后在离线场景下,将大量的日志使用Hadoop进行处理,分析用户习惯等信息。
# Hbase 八大场景
- 对象存储:我们知道不少的头条类、新闻类的的新闻、网页、图片存储在HBase之中,一些病毒公司的病毒库也是存储在HBase之中
- 时序数据:HBase之上有OpenTSDB模块,可以满足时序类场景的需求
- 推荐画像:特别是用户的画像,是一个比较大的稀疏矩阵,蚂蚁的风控就是构建在HBase之上
- 时空数据:主要是轨迹、气象网格之类,滴滴打车的轨迹数据主要存在HBase之中,另外在技术所有大一点的数据量的车联网企业,数据都是存在HBase之中
- CubeDB OLAP:Kylin一个cube分析工具,底层的数据就是存储在HBase之中,不少客户自己基于离线计算构建cube存储在hbase之中,满足在线报表查询的需求
- 消息/订单:在电信领域、银行领域,不少的订单查询底层的存储,另外不少通信、消息同步的应用构建在HBase之上
- Feeds流:典型的应用就是xx朋友圈类似的应用
- NewSQL:之上有Phoenix的插件,可以满足二级索引、SQL的需求,对接传统数据需要SQL非事务的需求
# 不适用于HDFS的场景:
低延迟 HDFS不适用于实时查询这种对延迟要求高的场景,例如:股票实盘。往往应对低延迟数据访问场景需要通过数据库访问索引的方案来解决,Hadoop生态圈中的Hbase具有这种随机读、低延迟等特点。
大量小文件 对于Hadoop系统,小文件通常定义为远小于HDFS的block size(默认64MB)的文件,由于每个文件都会产生各自的MetaData元数据,Hadoop通过Namenode来存储这些信息,若小文件过多,容易导致Namenode存储出现瓶颈。
多用户更新 为了保证并发性,HDFS需要一次写入多次读取,目前不支持多用户写入,若要修改,也是通过追加的方式添加到文件的末尾处,出现太多文件需要更新的情况,Hadoop是不支持的。 针对有多人写入数据的场景,可以考虑采用Hbase的方案。
结构化数据 HDFS适合存储半结构化和非结构化数据,若有严格的结构化数据存储场景,也可以考虑采用Hbase的方案。
数据量并不大
参考
- 区分 hdfs hbase hive hbase适用场景 - 李玉龙 - 博客园 (opens new window)
- (第3篇)HDFS是什么?HDFS适合做什么?我们应该怎样操作HDFS系统? - 何石-博客 - 博客园 (opens new window)
- hbase常识及habse适合什么场景 - 天下尽好 - 博客园 (opens new window)
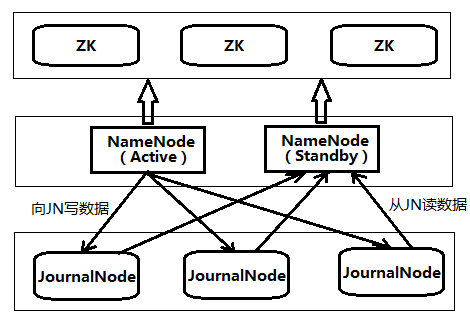
# Hadoop namenode的ha,主备切换实现原理,日志同步原理,QJM中用到的分布式一致性算法(就是paxos算法)
# 联邦HDFS
2.x 引入联邦HDFS,加入多个namenode,m每个namenode管理文件系统空间的一部分,m每个nn管理y一个命名空间卷(namespace volume) 由命名空间卷的原数据和一个 data pool 数据池组成。数据池包含该命名空间下的所有数据块
# namenode 宕机后,新的namenode恢复要做的操作
- 将命名空间的映像导入到内存中
- 重演编辑日志
- 接受足够多的datanode的数据库报告并退出安全模式。
# namenode 备用 HA

# 两种高可用性共享存储 NFS过滤器和QJM
QJM 群体日志管理器(qurom journal manager) 专用HDFS实现,推荐适用,以一组日志节点(journal node)形式运行,每次编辑必须写入多数日志节点,没有适用ZK HDFS namenode 选举时候用到ZK
系统中有一个故障转移i控制器(failover controller) 新尸体,管理活动nn转移为备用nn过程,多种控制器,默认适用ZK,确保只有一个nn,每个nn运行一个轻量级 控制器,见识宿主nn是否失效,并在nn失效的时候故障切换
# 为什么HDFS 块为64MB或者128MB
为了最小化寻址爱笑,hdfs寻址包括磁盘寻到开销,数据块定位开销 ,设计较大的块,可以把上述寻址开销分摊到较多的数据中,降低开销 采用抽象的块概念有几个好处
- 支持大规模文件存储 大文件分成小文件,分开存储,不受限制哟
- 简化系统设计 方便元数据管理
- 适合数据备份
# 名称节点 数据节点 和 SecondaryNameNode
名称节点
- FSImage 维护文件系统数和所有文件文件夹的元数据 系统启动时候加载,然后执行Editlog各项操作 然后创建一个新的Fsimage和空的Editlog
- EditLog 记录了针对文件创建删除 重命名
SecondaryNameNOde
- Fsimage Editlog 合并操作 请求NN 停止Editlog文件,添加一个新的文件Edtlog.new ,然后将Fsimage和editlog拉回到本地,加载到内存,执行合并,然后发送到NN,NN收到后使用新的替换旧的FSimage,用Editlog.nwe替换editlog文件
- 名称节点的检查点 SN成为NN的检查点, 在拉回数据之后的一段时间内,如果NN丢失了,会导致一部分数据丢失,并不是热备份。
# HDFS SecondaryNameNode和HA(高可用)区别
在Hadoop2.0之前,NameNode只有一个,存在单点问题(虽然Hadoop1.0有SecondaryNameNode) 在2.0之后引入HA机制
官方介绍2种方式,一种NFS(Network File System),另一种QJM(Quorum Journal Manager)
quorum
英 [ˈkwɔːrəm] 美 [ˈkwɔːrəm]n. 法定人数
journal
英 [ˈdʒɜːnl] 美 [ˈdʒɜːrnl]n. 日报,杂志;日记;分类账 复数 journals
# NameNode
保存HDFS元数据,比如命名空间信息、块。运行时,这些存在内存,也可以吃就到磁盘山
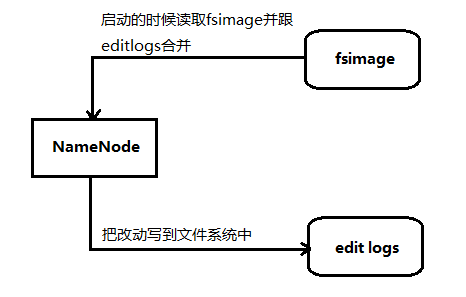
# fsimage
在NN启动的时候,对整个文件系统的快照
# Edits logs
在NN启动后,对文件系统的改动序列
只有在nn重启的时候,edit logs 才会合并到fs image中,从而得到最新的快照。 但是一般nn很少重启nn运行很长后,edit logs 变得很大
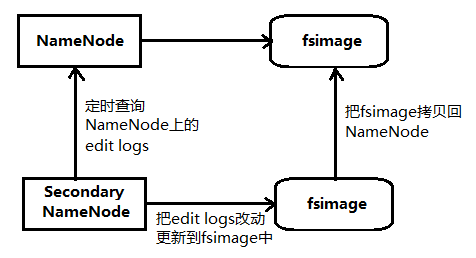
# Secondary NameNode
sn就是帮助解决上面问题,指责就是合并nn的edit logs 到 fsimage种
# HA(高可用)介绍
Hadoop2.0的HA 机制有两个NameNode,一个是Active状态,另一个是Standby状态。两者的状态可以切换,但同时最多只有1个是Active状态
Active NameNode和Standby NameNode之间通过NFS或者JN(JournalNode,QJM方式)来同步数据。
Active NameNode会把最近的操作记录写到本地的一个edits文件中(edits file),并传输到NFS或者JN种,SNN定期检查,从JN把最近的edit文件读过来,合并成一个新的fsimage,合并完成后会通知ANN获取这个新的fsimage。ANN会替换旧的fsimage
# 数据同步方式 NFS 和 QJM
# NFS
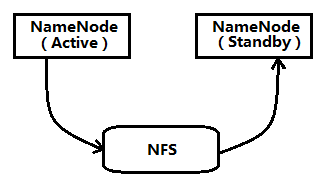
缺点: 如果 ANN 或者 SNN又一个与NFS有网络问题,会造成数据同步出问题
# QJM
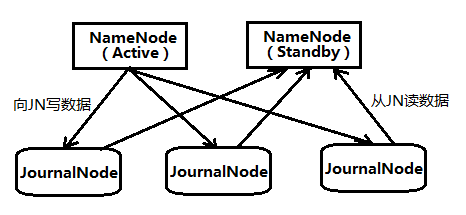
QJM的方式可以解决上述NFS容错机制不足的问题。Active NameNode和Standby NameNode之间是通过一组JournalNode(数量是奇数,可以是3,5,7…,2n+1)来共享数据。Active NameNode把最近的edits文件写到2n+1个JournalNode上,只要有n+1个写入成功就认为这次写入操作成功了,然后Standby NameNode就可以从JournalNode上读取了。可以看到,QJM方式有容错机制,可以容忍n个JournalNode的失败。
# 主备切换