# Spark Streaming
# Spark Streaming 基础
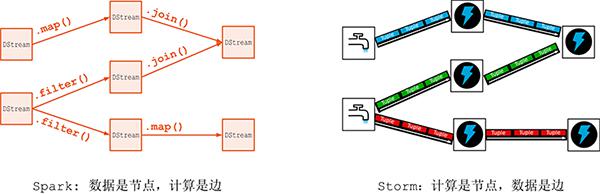
# Spark Streaming和Storm有何区别? 应用场景?
# Spark Streaming 原理
参考
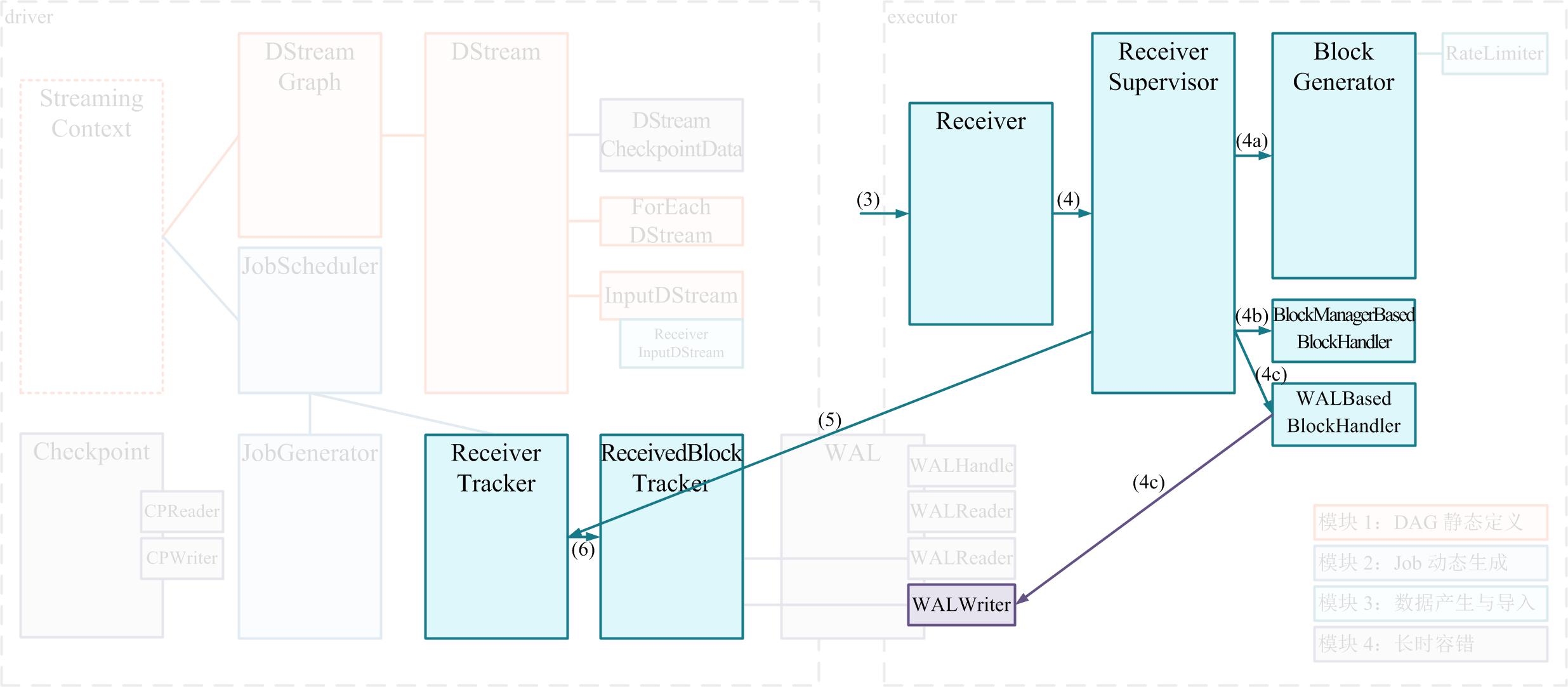
# SS 整体模块
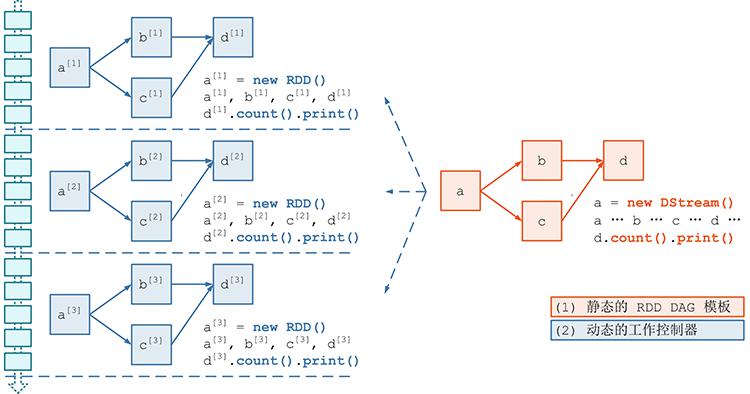
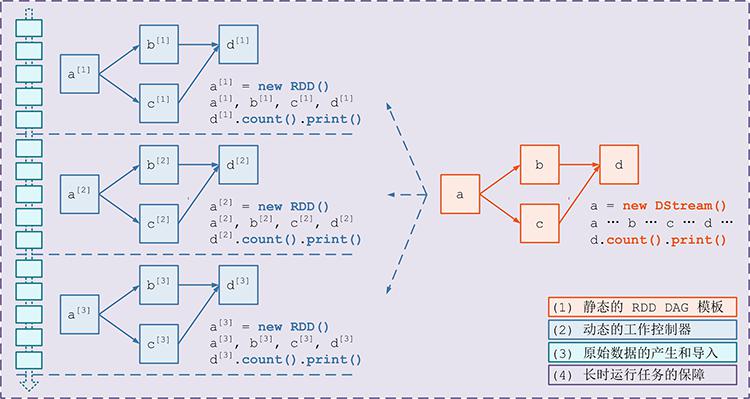
- 模块 1:DAG 静态定义
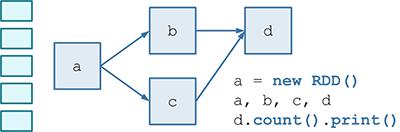
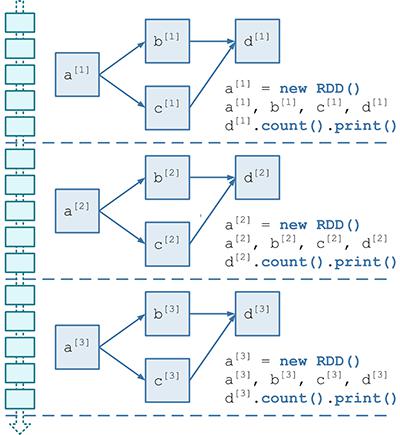
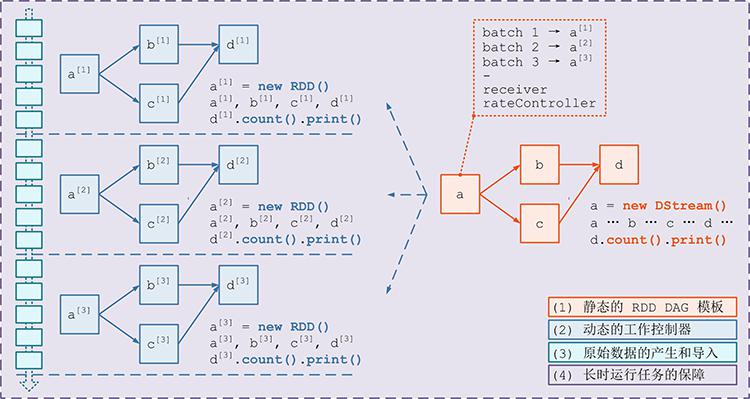
- 应该首先对计算逻辑描述为一个 RDD DAG 的“模板”,在后面 Job 动态生成的时候,针对每个 batch,Spark Streaming 都将根据这个“模板”生成一个 RDD DAG 的实例。
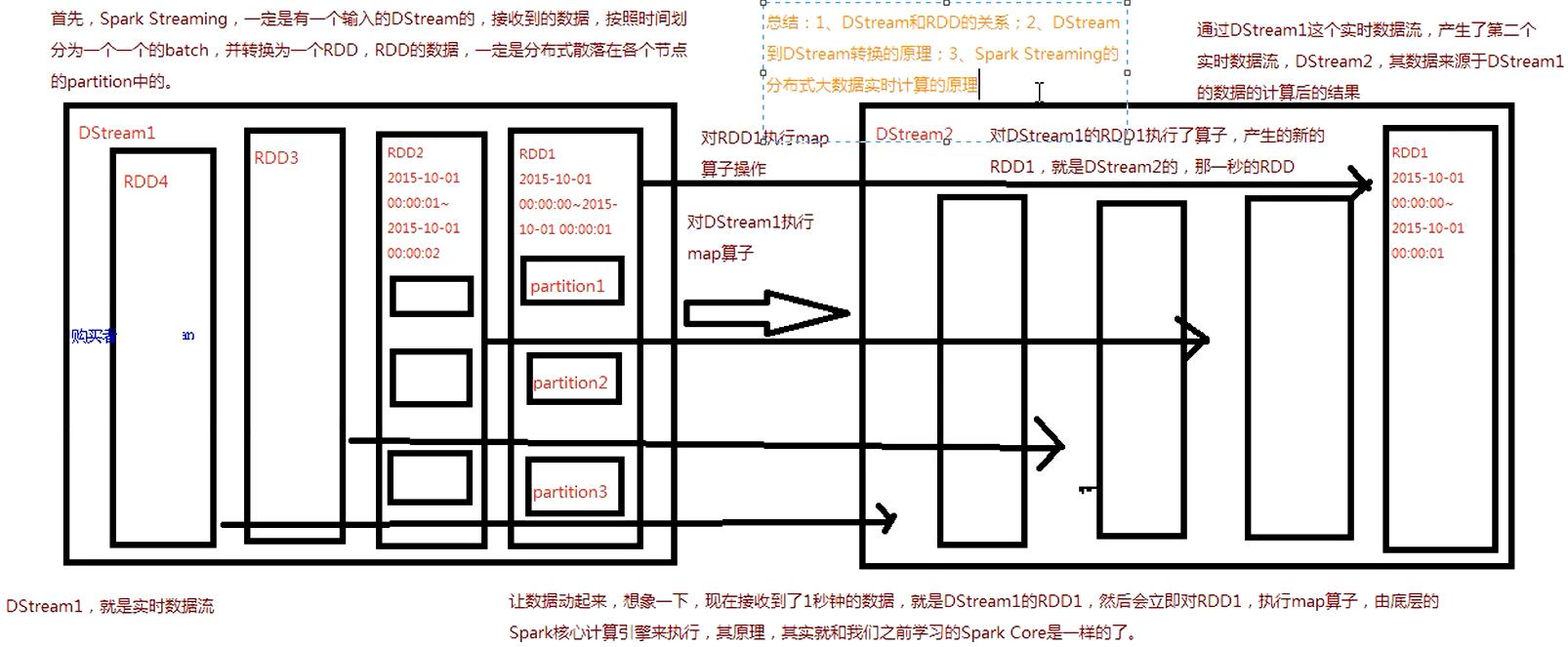
- DStream 和 RDD 的关系
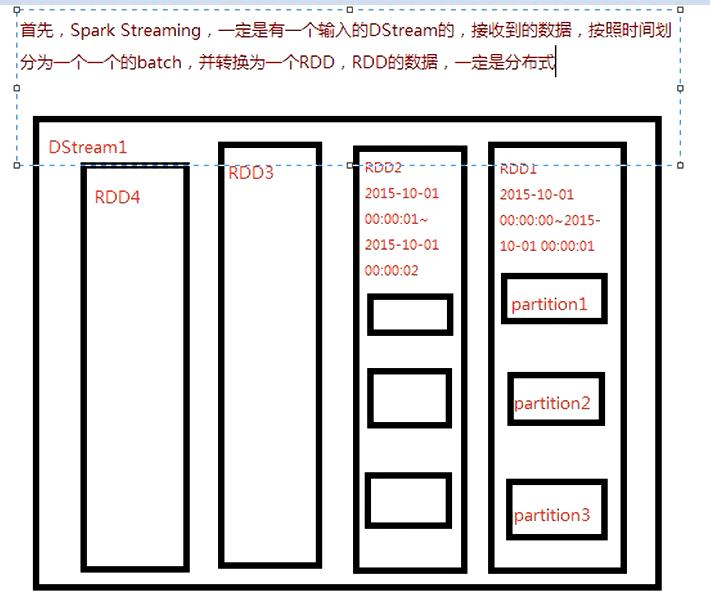
- DStream 是 RDD 的模板,而且 DStream 和 RDD 具有相同的 transformation 操作,比如 map(), filter(), reduce() ……等等(正是这些相同的 transformation 使得 DStreamGraph 能够忠实记录 RDD DAG 的计算逻辑)
- DStream 维护了对每个产出的 RDD 实例的引用
- 可以认为,RDD 加上 batch 维度就是 DStream,DStream 去掉 batch 维度就是 RDD —— 就像 RDD = DStream at batch T。
- 模块 2:Job 动态生成
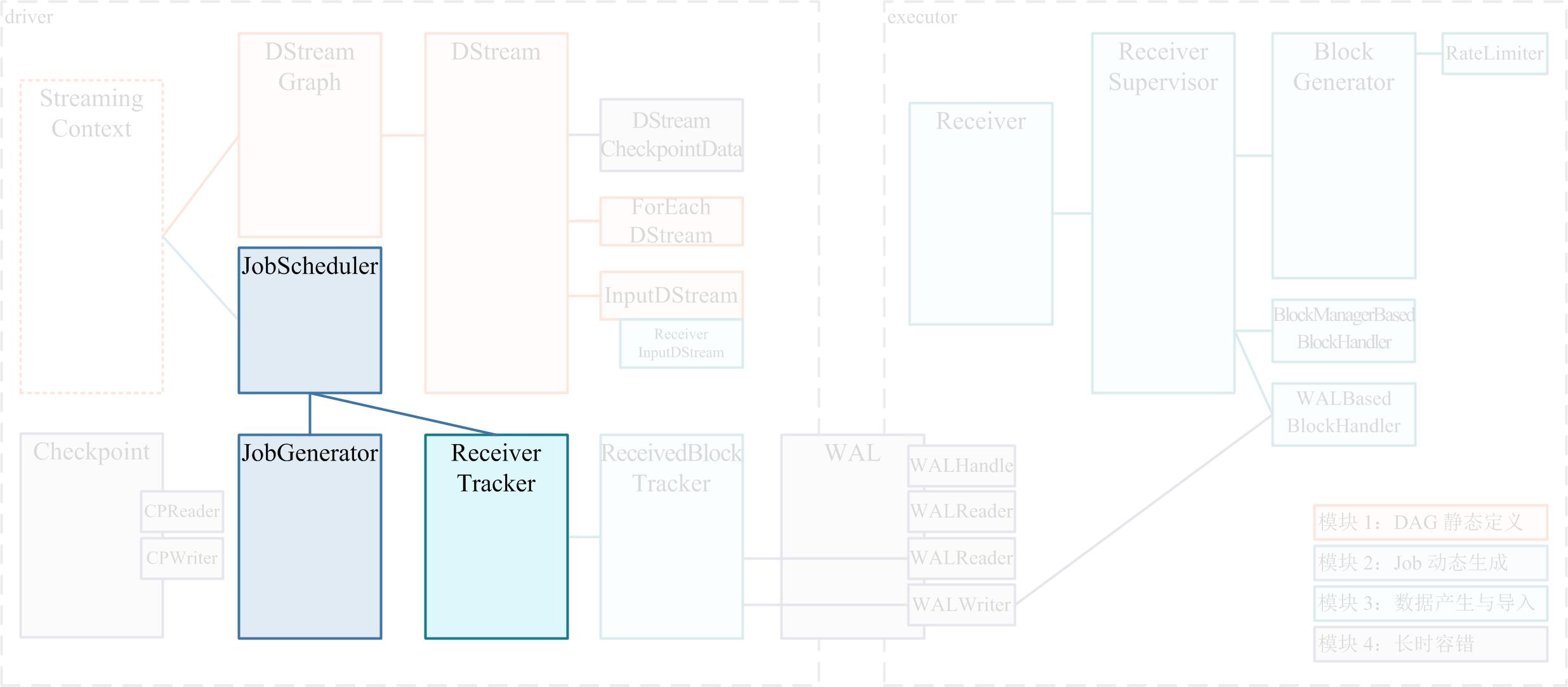
- 在 Spark Streaming 里,总体负责动态作业调度的具体类是 JobScheduler ,在 Spark Streaming 程序开始运行的时候,会生成一个 JobScheduler 的实例,并被 start() 运行起来
- JobScheduler 有两个非常重要的成员:JobGenerator 和 ReceiverTracker。
- JobScheduler 将每个 batch 的 RDD DAG 具体生成工作委托给 JobGenerator
- 而将源头输入数据的记录工作委托给 ReceiverTracker。
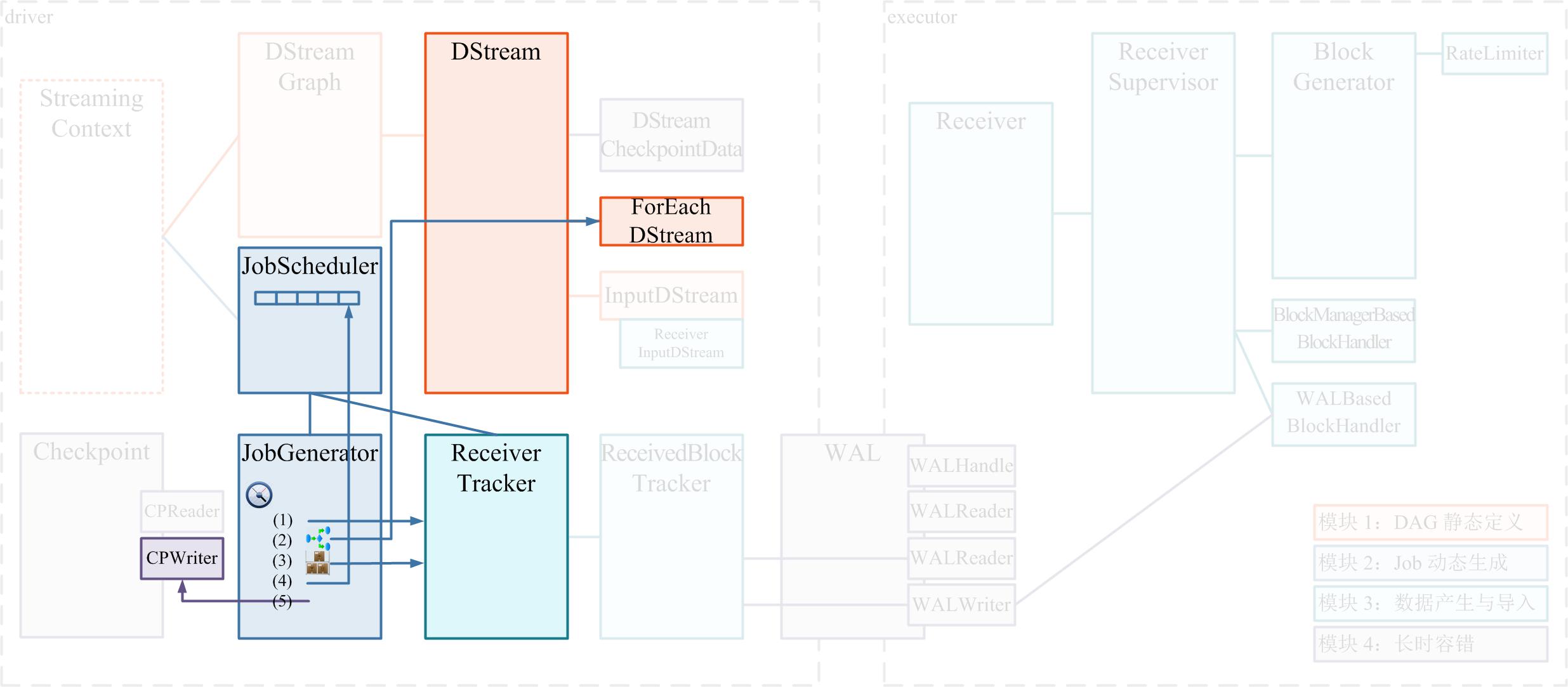
- JobGenerator 维护了一个定时器,周期就是我们刚刚提到的 batchDuration,定时为每个 batch 生成 RDD DAG 的实例。
- 要求 ReceiverTracker 将目前已收到的数据进行一次 allocate,即将上次 batch 切分后的数据切分到到本次新的 batch 里;
- 要求 DStreamGraph 复制出一套新的 RDD DAG 的实例,具体过程是:DStreamGraph 将要求图里的尾 DStream 节点生成具体的 RDD 实例,并递归的调用尾 DStream 的上游 DStream 节点……以此遍历整个 DStreamGraph,遍历结束也就正好生成了 RDD DAG 的实例;
- 获取第 1 步 ReceiverTracker 分配到本 batch 的源头数据的 meta 信息;
- 将第 2 步生成的本 batch 的 RDD DAG,和第 3 步获取到的 meta 信息,一同提交给 JobScheduler 异步执行;
- 只要提交结束(不管是否已开始异步执行),就马上对整个系统的当前运行状态做一个 checkpoint。
- 模块 3:数据产生与导入
- 模块 4:长时容错 数据安全
- executor
- (1) 热备: MEMORY_AND_DISK_2 MEMORY_ONLY_2
- (2) 冷备:冷备是每次存储块数据前,先把块数据作为 log 写出到 WriteAheadLog 里,再存储到本 executor。executor 失效时,就由另外的 executor 去读 WAL,再重做 log 来恢复块数据。WAL 通常写到可靠存储如 HDFS 上,所以恢复时可能需要一段 recover time
- (3) 重放: kafka 重放
- (4) 忽略

- driver 端长时容错
- 块数据的 meta 信息上报到 ReceiverTracker,然后交给 ReceivedBlockTracker 做具体的管理。ReceivedBlockTracker 也采用 WAL 冷备方式进行备份,在 driver 失效后,由新的 ReceivedBlockTracker 读取 WAL 并恢复 block 的 meta 信息。
- executor
# DStream, DStreamGraph 架构原理
- Spark Streaming 的 模块 1 DAG 静态定义 要解决的问题就是如何把计算逻辑描述为一个 RDD DAG 的“模板”,在后面 Job 动态生成的时候,针对每个 batch,都将根据这个“模板”生成一个 RDD DAG 的实例。
- 这个 RDD “模板”对应的具体的类是 DStream,RDD DAG “模板”对应的具体类是 DStreamGraph。
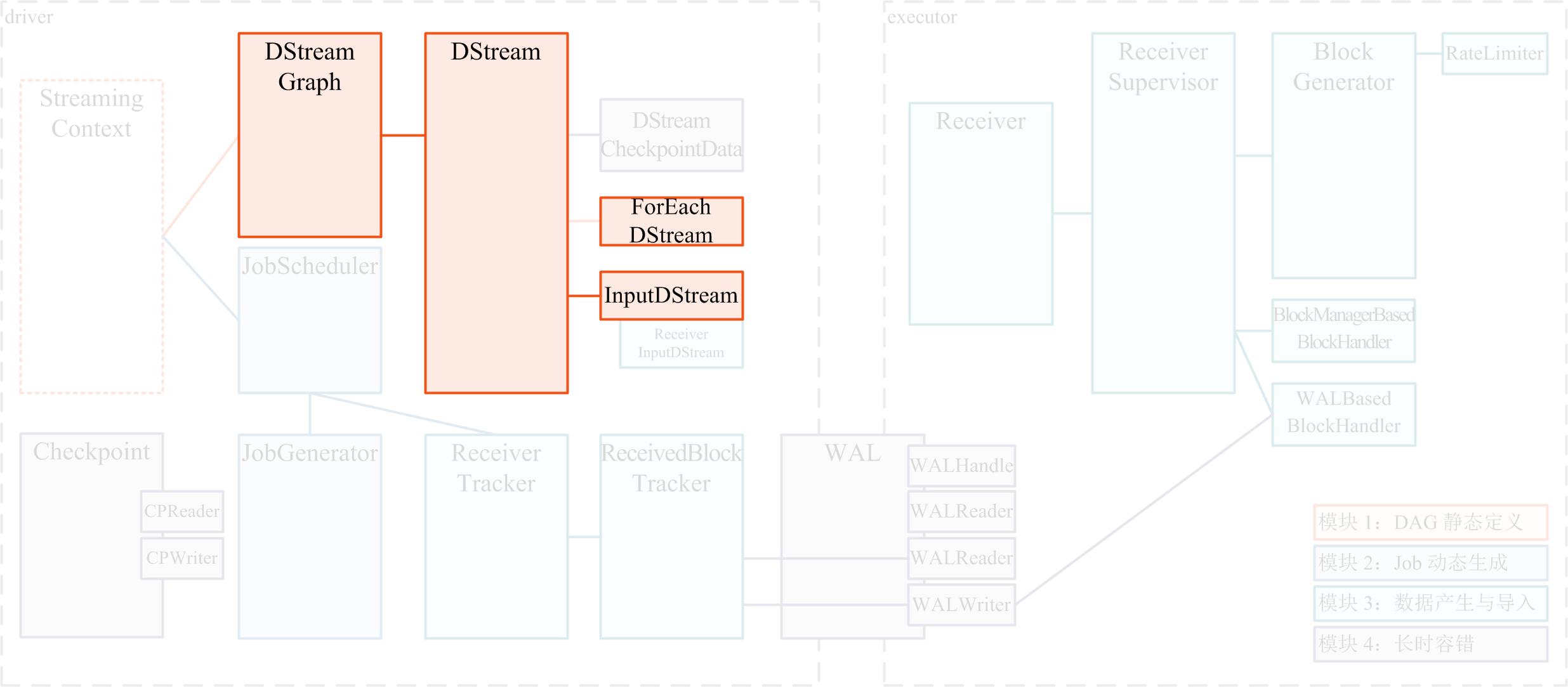
- RDD 的定义是一个只读、分区的数据集(an RDD is a read-only, partitioned collection of records),而 DStream 又是 RDD 的模板,所以我们把 Dstream 也视同数据集
- 由已有的 DStream 产生新 DStream 的操作统称 transformation。一些典型的 tansformation 包括 map(), filter(), reduce(), join() 等 。
- 另一些 不产生新 DStream 数据集,而是只在已有 DStream 数据集上进行的操作和输出,统称为 output 。比如 a.print() 就不会产生新的数据集,而是只是将 a 的内容打印出来,所以 print() 就是一种 output 操作。一些典型的 output 包括 print(), saveAsTextFiles(), saveAsHadoopFiles(), foreachRDD()

- 总结一下:
- transformation:可以看到基本上 1 种 transformation 将对应产生一个新的 DStream 子类实例,如: .flatMap() 将产生 FaltMappedDStream 实例 .map() 将产生 MappedDStream 实例
- output:将只产生一种 ForEachDStream 子类实例,用一个函数 func 来记录需要做的操作 如对于 print() 就是:func = cnt => cnt.print()
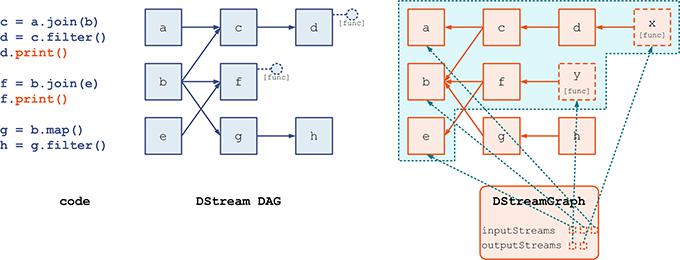
- Spark Streaming 在进行物理记录时却是反向 相同与RDD 的先计算上游的思路 DStream 也采用的反向表示 所以,这里 d 对 c 的引用,表达的是一个上游依赖(dependency)的关系;也就是说,不求值则已,一旦 d.print() 这个 output 操作触发了对 d 的求值,那么就需要从 d 开始往上游进行追溯计算。
- 我们总结一下:
- (1) DStream 逻辑上通过 transformation 来形成 DAG,但在物理上却是通过与 transformation 反向的依赖(dependency)来构成表示的
- (2) 当某个节点调用了 output 操作时,就产生一个新的 ForEachDStream ,这个新的 ForEachDStream 记录了具体的 output 操作是什么
- (3) 在每个 batch 动态生成 RDD 实例时,就对 (2) 中新生成的 DStream 进行 BFS 遍历
- (4) Spark Streaming 记录整个 DStream DAG 的方式,就是通过一个 DStreamGraph 实例记录了到所有的 output stream 节点的引用 通过对所有 output stream 节点进行遍历,就可以得到所有上游依赖的 DStream 不能被遍历到的 DStream 节点 —— 如 g 和 h —— 则虽然出现在了逻辑的 DAG 中,但是并不属于物理的 DStreamGraph,也将在 Spark Streaming 的实际运行过程中不产生任何作用
- (5) DStreamGraph 实例同时也记录了到所有 input stream 节点的引用 DStreamGraph 时常需要遍历没有上游依赖的 DStream 节点 —— 称为 input stream —— 记录一下就可以避免每次为查找 input stream 而对 output steam 进行 BFS 的消耗

# DStream 生成 RDD 的原理
- Spark Streaming 的 模块 1 DAG 静态定义 要解决的问题就是如何把计算逻辑描述为一个 RDD DAG 的“模板”,在后面 Job 动态生成的时候,针对每个 batch,都将根据这个“模板”生成一个 RDD DAG 的实例。
- RDD “模板”对应的具体的类是 DStream,RDD DAG “模板”对应的具体类是 DStreamGraph。
- DStream 通过 generatedRDD 管理已生成的 RDD
- DStream 内部用一个类型是 HashMap 的变量 generatedRDD 来记录已经生成过的 RDD:

- 每一个不同的 DStream 实例,都有一个自己的 generatedRDD
- 实现
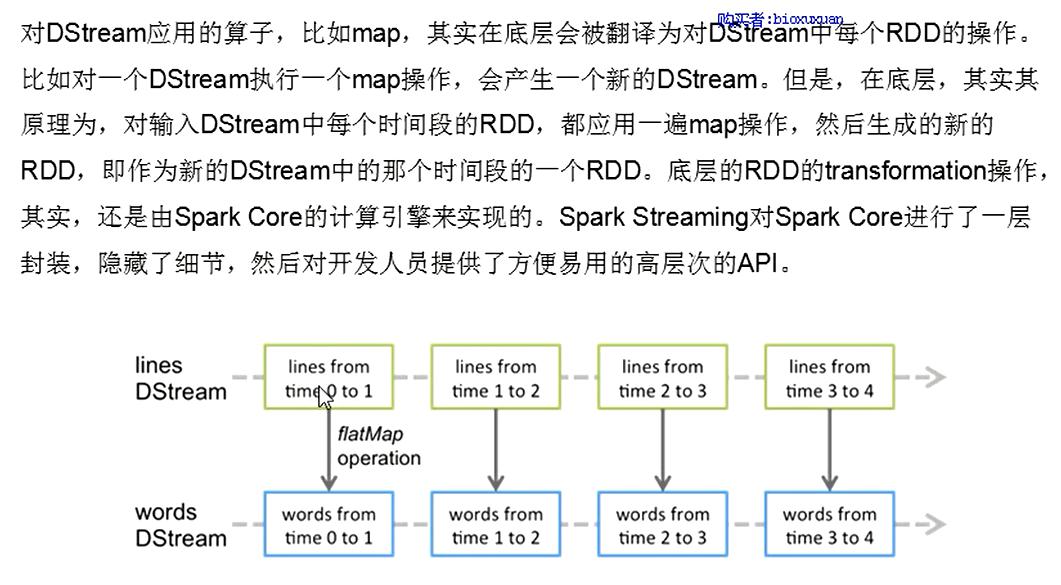
- (a) InputDStream 的 compute(time) 实现 1. (1) 先通过一个 findNewFiles() 方法,找到 validTime 以后产生的多个新 file (2) 对每个新 file,都将其作为参数调用 sc.newAPIHadoopFile(file),生成一个 RDD 实例 (3) 将 (2) 中的多个新 file 对应的多个 RDD 实例进行 union,返回一个 union 后的 UnionRDD
- (b) 一般 DStream 的 compute(time) 实现 (1) 获取 parent DStream 在本 batch 里对应的 RDD 实例 (2) 在这个 parent RDD 实例上,以 mapFunc 为参数调用 .map(mapFunc) 方法,将得到的新 RDD 实例返回 完全相当于用 RDD API 写了这样的代码:return parentRDD.map(mapFunc) 总结上面 MappedDStream 和 FilteredDStream 的实现,可以看到: DStream 的 .map() 操作生成了 MappedDStream,而 MappedDStream 在每个 batch 里生成 RDD 实例时,将对 parentRDD 调用 RDD 的 .map() 操作 —— DStream.map() 操作完美复制为每个 batch 的 RDD.map() 操作 DStream 的 .filter() 操作生成了 FilteredDStream,而 FilteredDStream 在每个 batch 里生成 RDD 实例时,将对 parentRDD 调用 RDD 的 .filter() 操作 —— DStream.filter() 操作完美复制为每个 batch 的 RDD.filter() 操作
- (c) ForEachDStream 的 compute(time) 实现 (1) 获取 parent DStream 在本 batch 里对应的 RDD 实例 (2) 以这个 parent RDD 和本次 batch 的 time 为参数,调用 foreachFunc(parentRDD, time) 方法
# JobScheduler, Job, JobSet 原理
- 在 Spark Streaming 程序在 ssc.start() 开始运行时,将 JobScheduler 的实例给 start() 运行起来。
- Spark Streaming 的 Job 总调度者 JobScheduler
- JobScheduler 是 Spark Streaming 的 Job 总调度者。
- JobScheduler 有两个非常重要的成员:JobGenerator 和 ReceiverTracker。JobScheduler 将每个 batch 的 RDD DAG 具体生成工作委托给 JobGenerator,而将源头输入数据的记录工作委托给 ReceiverTracker。
- JobGenerator 维护了一个定时器,周期就是我们刚刚提到的 batchDuration,定时为每个 batch 生成 RDD DAG 的实例 DStreamGraph.generateJobs(time) 将返回一个 Seq[Job],其中的每个 Job 是一个 ForEachDStream 实例的 generateJob(time) 返回的结果。
- 就将其包装成一个 JobSet(如上图 (3) ),然后就调用 JobScheduler.submitJobSet(jobSet) 来交付回 JobScheduler

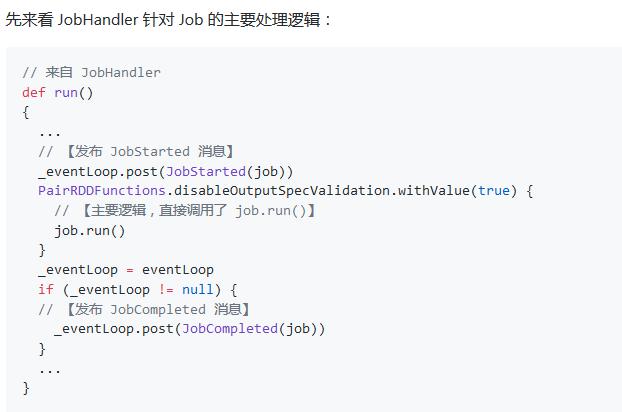
- JobHandler 除了做一些状态记录外,最主要的就是调用 job.run()
- Spark Streaming 的 JobSet, Job,与 Spark Core 的 Job, Stage, TaskSet, Task

- Spark Core 的 Job, Stage, Task 就是我们“日常”谈论 Spark 任务时所说的那些含义,而且在 Spark 的 WebUI 上有非常好的体现,比如下图就是 1 个 Job 包含 3 个 Stage;3 个 Stage 各包含 8, 2, 4 个 Task。而 TaskSet 则是 Spark Core 的内部代码里用的类,是 Task 的集合,和 Stage 是同义的。
- Spark Streaming 里的 Job 更像是个 Java 里的 Runnable,可以 run() 一个自定义的 func 函数。而这个 func, 可以:
- 直接调用 RDD 的 action,从而产生 1 个或多个 Spark Core 的 Job
- 先打印一行表头;然后调用 firstTen = RDD.collect(),再打印 firstTen 的内容;最后再打印一行表尾 —— 这正是 DStream.print() 的 Job 实现
- 也可以是任何用户定义的 code,甚至整个 Spark Streaming 执行过程都不产生任何 Spark Core 的 Job —— 如上一小节所展示的测试代码,其 Job 的 func 实现就是:Thread.sleep(Int.MaxValue),仅仅是为了让这个 Job 一直跑在 jobExecutor 线程池里,从而测试 jobExecutor 的并行度 😃
# JobGenerator 原理

- 在启动了 RPC 处理线程 eventLoop 后,就会根据是否是第一次启动,也就是是否存在 checkpoint,来具体的决定是 restart() 还是 startFirstTime()。
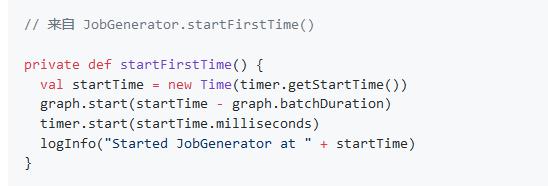
- 先是通过 graph.start() 来告知了 DStreamGraph 第 1 个 batch 的启动时间,然后就是 timer.start() 启动了关键的定时器。
- RecurringTimer
- JobGenerator 维护了一个定时器,周期就是用户设置的 batchDuration,定时为每个 batch 生成 RDD DAG 的实例。

- 整个 timer 的调度周期就是 batchDuration,每次调度起来就是做一个非常简单的工作:往 eventLoop 里发送一个消息 —— 该为当前 batch (new Time(longTime)) GenerateJobs 了!
- GenerateJobs
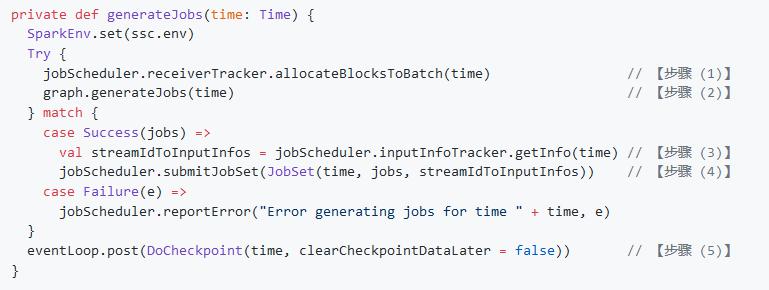
- (1) 要求 ReceiverTracker 将目前已收到的数据进行一次 allocate,即将上次 batch 切分后的数据切分到到本次新的 batch 里
- (2) 要求 DStreamGraph 复制出一套新的 RDD DAG 的实例,具体过程是:DStreamGraph 将要求图里的尾 DStream 节点生成具体的 RDD 实例,并递归的调用尾 DStream 的上游 DStream 节点……以此遍历整个 DStreamGraph,遍历结束也就正好生成了 RDD DAG 的实例
- (3) 获取第 1 步 ReceiverTracker 分配到本 batch 的源头数据的 meta 信息
- (4) 将第 2 步生成的本 batch 的 RDD DAG,和第 3 步获取到的 meta 信息,一同提交给 JobScheduler 异步执行
- 这里我们提交的是将 (a) time (b) Seq[job] (c) 块数据的 meta 信息 这三者包装为一个 JobSet,然后调用 JobScheduler.submitJobSet(JobSet) 提交给 JobScheduler
- 这里的向 JobScheduler 提交过程与 JobScheduler 接下来在 jobExecutor 里执行过程是异步分离的,因此本步将非常快即可返回
- (5) 只要提交结束(不管是否已开始异步执行),就马上对整个系统的当前运行状态做一个 checkpoint
- 这里做 checkpoint 也只是异步提交一个 DoCheckpoint 消息请求,不用等 checkpoint 真正写完成即可返回
- 这里也简单描述一下 checkpoint 包含的内容,包括已经提交了的、但尚未运行结束的 JobSet 等实际运行时信息。
- 整个 DStreamGraph 是由 output stream 通过 dependency 引用关系,索引到上游 DStream 节点。而递归的追溯到最上游的 InputDStream 节点时,就没有对其它 DStream 节点的依赖了,因为 InputDStream 节点本身就代表了最原始的数据集。
参考 CoolplaySpark/2.2 JobGenerator 详解.md at master · lw-lin/CoolplaySpark · GitHub (opens new window)
# Receiver 分发详解
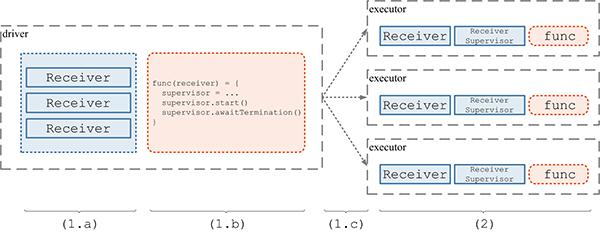
- ReceiverTracker 自身运行在 driver 端,是一个管理分布在各个 executor 上的 Receiver 的总指挥者。在 ssc.start() 时,将隐含地调用 ReceiverTracker.start();而 ReceiverTracker.start() 最重要的任务就是调用自己的 launchReceivers() 方法将 Receiver 分发到多个 executor 上去。然后在每个 executor 上,由 ReceiverSupervisor 来分别启动一个 Receiver 接收数据
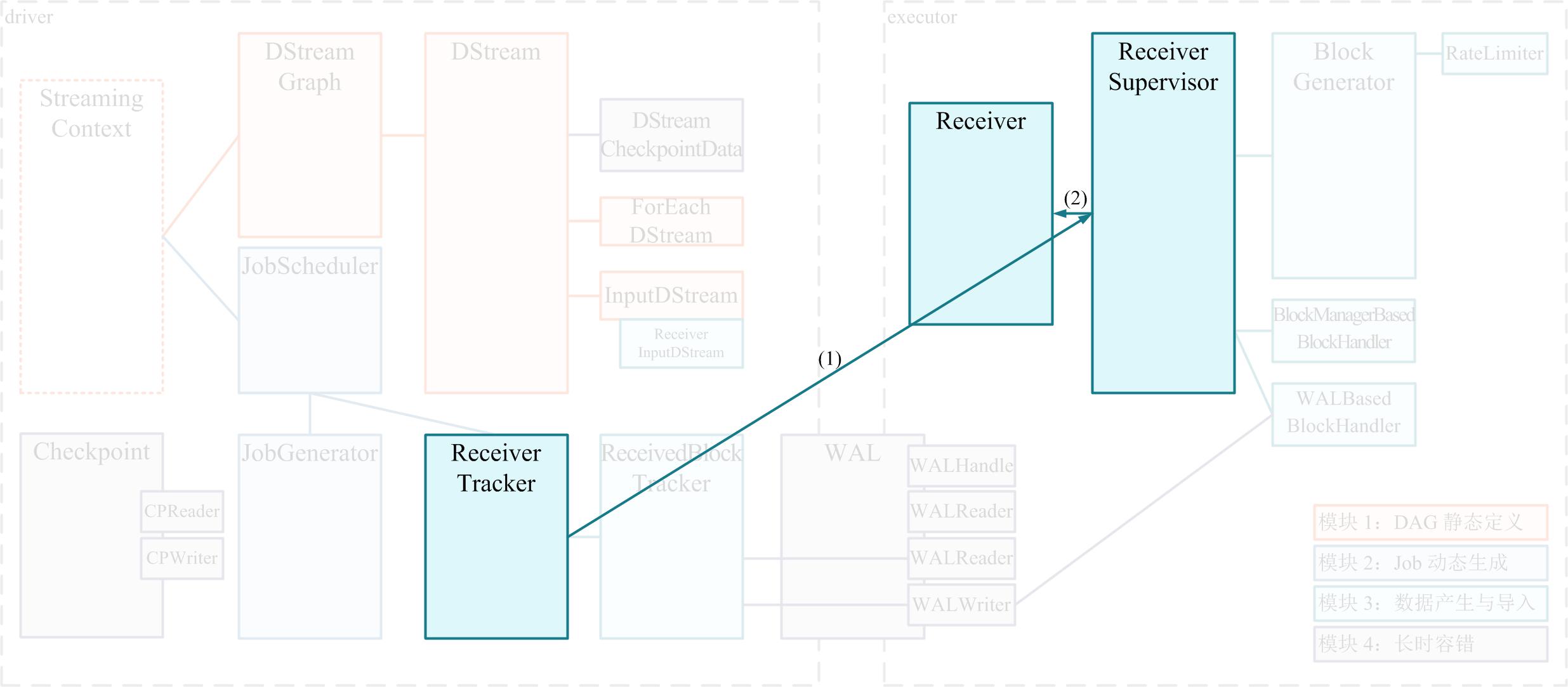
- 通过 1 个 RDD 实例包含 x 个 Receiver,对应启动 1 个 Job 包含 x 个 Task,就可以完成 Receiver 的分发和部署了。上述 (1.a)(1.b)(1.c)(2) 的过程示意如下图:
- Spark 1.5.0 的 launchReceivers() 实现
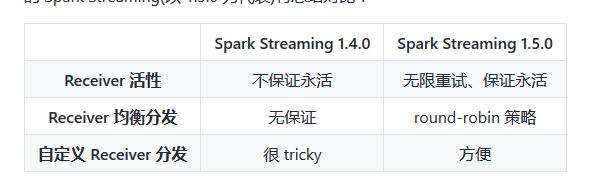
- 从 1.5.0 开始,Spark Streaming 添加了增强的 Receiver 分发策略。对比之前的版本,主要的变更在于: 添加可插拔的 ReceiverSchedulingPolicy 把 1 个 Job(包含 x 个 Task),改为 x 个 Job(每个 Job 只包含 1 个 Task) 添加对 Receiver 的监控重启机制
参考 CoolplaySpark/3.1 Receiver 分发详解.md at master · lw-lin/CoolplaySpark · GitHub (opens new window)
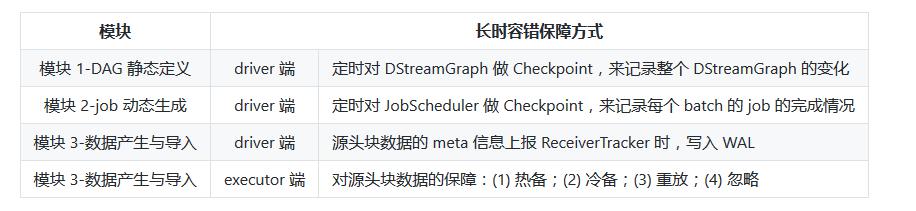
# Receiver, ReceiverSupervisor, BlockGenerator, ReceivedBlockHandler 详解
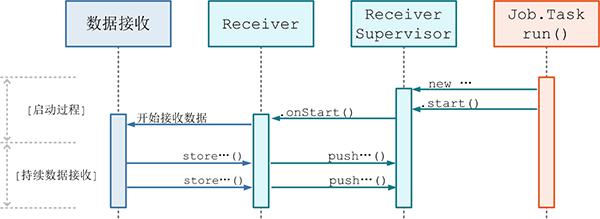
ReceiverSupervisor 将在 executor 端作为的主要角色,并且:
(3) Receiver 在 onStart() 启动后,就将持续不断地接收外界数据,并持续交给 ReceiverSupervisor 进行数据转储;
(4) ReceiverSupervisor 持续不断地接收到 Receiver 转来的数据:
如果数据很细小,就需要 BlockGenerator 攒多条数据成一块(4a)、然后再成块存储(4b 或 4c) 反之就不用攒,直接成块存储(4b 或 4c) 这里 Spark Streaming 目前支持两种成块存储方式,一种是由 blockManagerskManagerBasedBlockHandler 直接存到 executor 的内存或硬盘,另一种由 WriteAheadLogBasedBlockHandler 是同时写 WAL(4c) 和 executor 的内存或硬盘(5) 每次成块在 executor 存储完毕后,ReceiverSupervisor 就会及时上报块数据的 meta 信息给 driver 端的 ReceiverTracker;这里的 meta 信息包括数据的标识 id,数据的位置,数据的条数,数据的大小等信息。
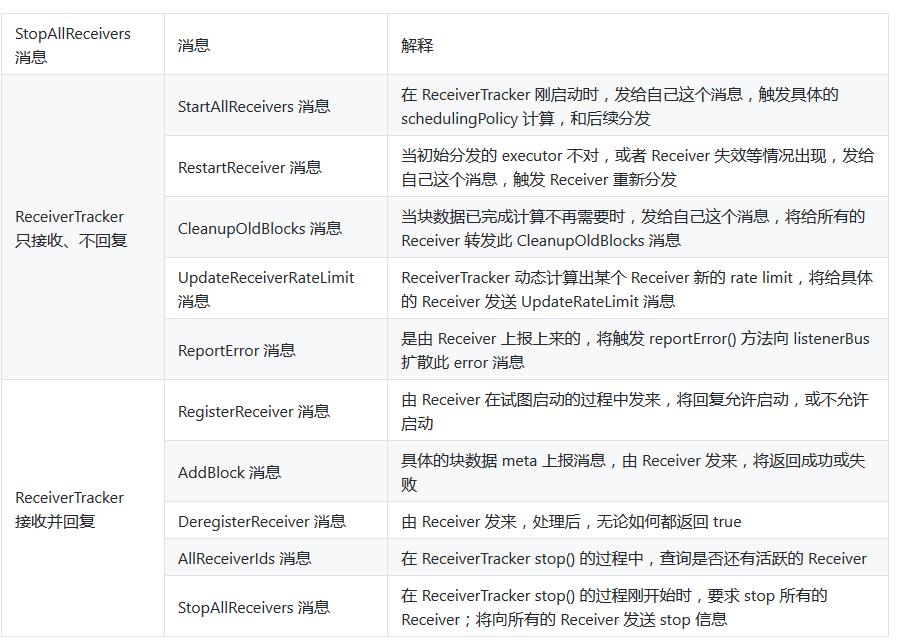
(6) ReceiverTracker 再将收到的块数据 meta 信息直接转给自己的成员 ReceivedBlockTracker,由 ReceivedBlockTracker 专门管理收到的块数据 meta 信息。
# ReceiverTraker, ReceivedBlockTracker 详解
# 常用名词介绍
- Dstream

# SS与Storm的对比


