# Spark
- 基础知识
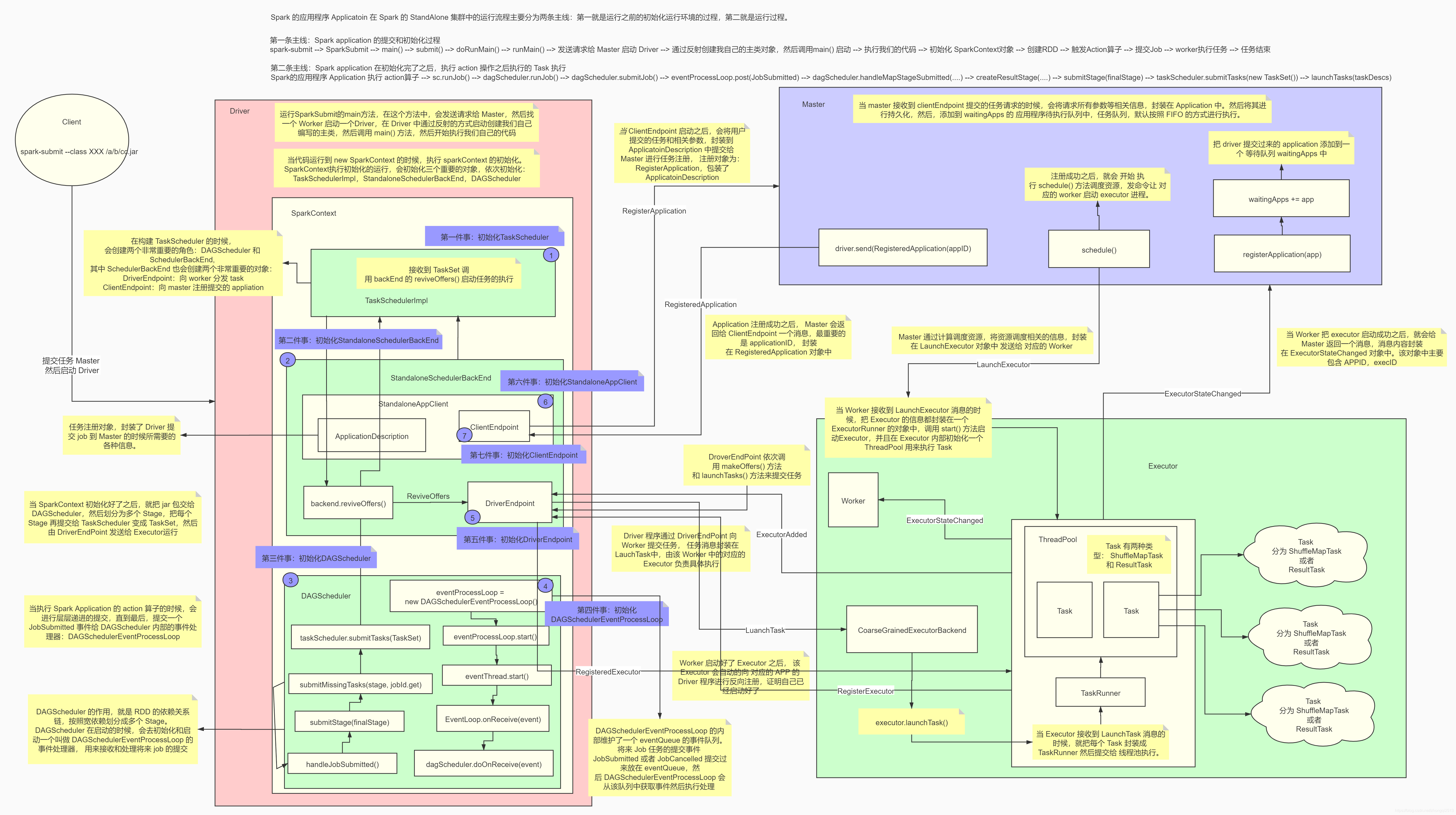
- Spark任务执行与调度组件
- Spark性能优化主要有哪些手段?
- 对于Spark你觉得他对于现有大数据的现状的优势和劣势在哪里?
- Spark的Shuffle原理及调优?
- spark如何保证宕机迅速恢复
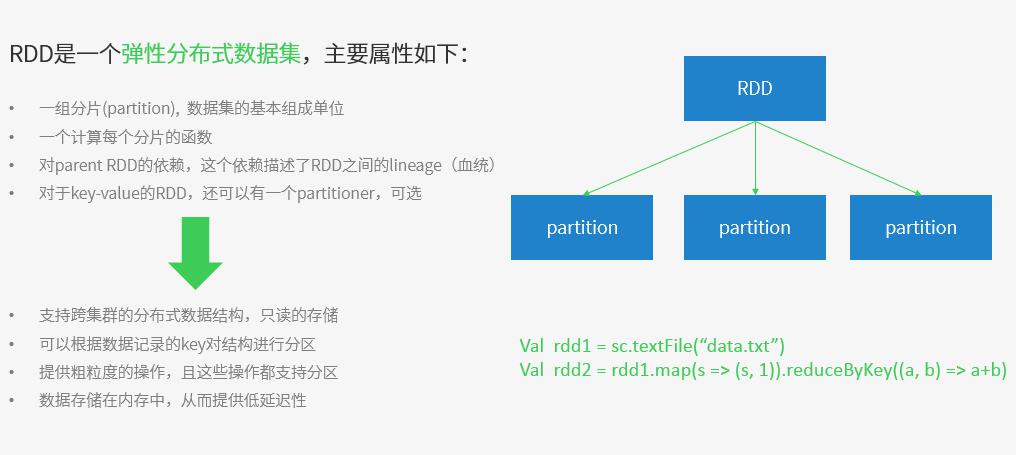
- RDD的原理以及持久化原理
- spark排序实现流程,reduce端怎么实现的;
- Spark的特点是什么
- Spark的三种提交模式是什么
- spark 实现高可用性:High Availability?
- spark中怎么解决内存泄漏问题?
- Spark-submit模式yarn-cluster和yarn-client的区别
- spark运行原理,从提交一个jar到最后返回结果,整个过程
- Yarn-Cluster
- Yarn-Client
- spark的stage划分是怎么实现的?拓扑排序?怎么实现?还有什么算法实现?
- spark rpc,spark2.0为啥舍弃了akka,而用netty
- spark的各种shuffle,与mapreduce的对比;
- spark的各种ha,master的ha,worker的ha,executor的ha,driver的ha,task的ha,在容错的时候对集群或是task有什么影响?
- spark的内存管理机制,spark1.6前后对比分析
- spark2.0做出了哪些优化?tungsten引擎?cpu与内存两个方面分别说明
- spark rdd、dataframe、dataset区别
- HashPartitioner与RangePartitioner的实现,以及水塘抽样;
- spark有哪几种join,使用场景,以及实现原理
- dagschedule、taskschedule、schedulebankend实现原理;
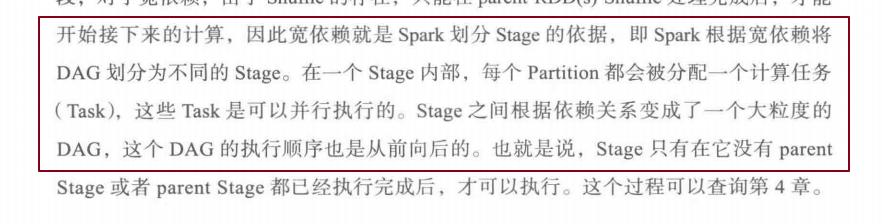
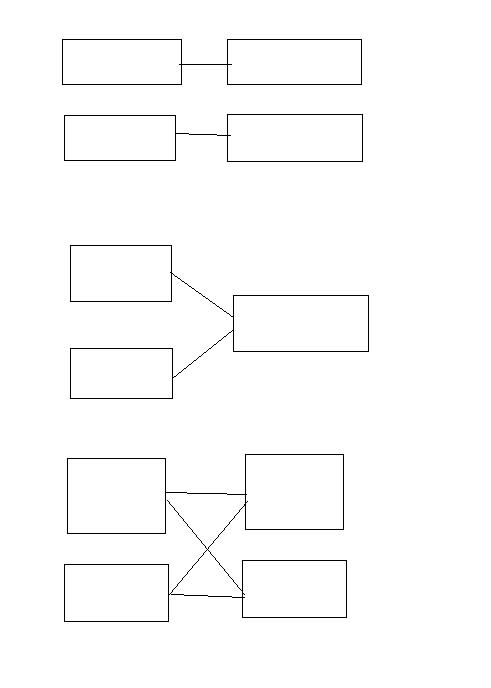
- 宽依赖、窄依赖的概念?宽依赖、窄依赖的例子?以下图中所指的是何种依赖
- Spark数据倾斜,怎么定位、怎么解决(阿里);
- spark有哪些组件?
- Spark的适用场景
- spark 架构
- spark task解析?
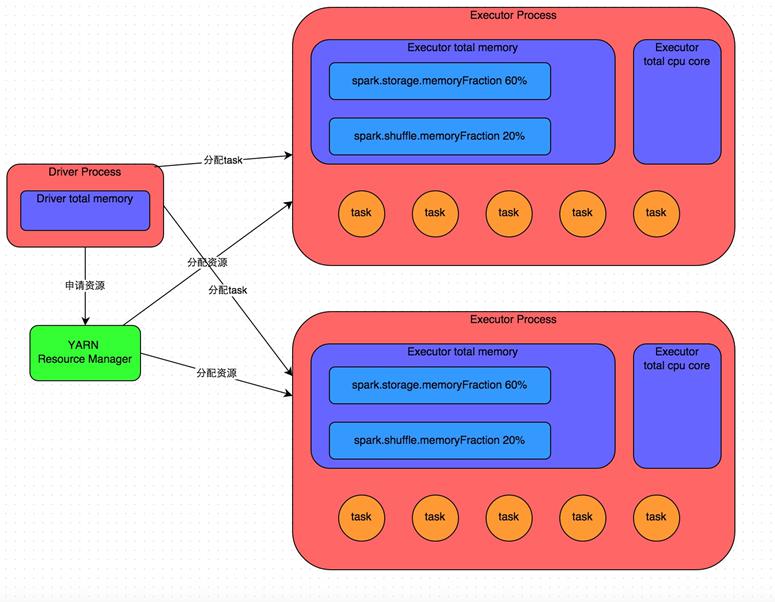
- spark 集群 100g内存 有两百g文件,去读取,有什么问题
- Spark 优化
- 原理
# 基础知识
# Spark任务执行与调度组件
# Spark性能优化主要有哪些手段?
1、常规性能调优:分配资源、并行度。。。等
2、JVM调优(Java虚拟机):JVM相关的参数,通常情况下,如果你的硬件配置、基础的JVM的配置,都ok的话,JVM通常不会造成太严重的性能问题;反而更多的是,在troubleshooting中,JVM占了很重要的地位;JVM造成线上的spark作业的运行报错,甚至失败(比如OOM)。
3、shuffle调优(相当重要):spark在执行groupByKey、reduceByKey等操作时的,shuffle环节的调优。这个很重要。shuffle调优,其实对spark作业的性能的影响,是相当之高!!!经验:在spark作业的运行过程中,只要一牵扯到有shuffle的操作,基本上shuffle操作的性能消耗,要占到整个spark作业的50%~90%。10%用来运行map等操作,90%耗费在两个shuffle操作。groupByKey、countByKey。
4、spark操作调优(spark算子调优,比较重要):groupByKey,countByKey或aggregateByKey来重构实现。有些算子的性能,是比其他一些算子的性能要高的。foreachPartition替代foreach。如果一旦遇到合适的情况,效果还是不错的。
5、广播大变量
spark性能调优都有哪些方法 - CSDN博客 (opens new window) spark性能优化 - 掘金 (opens new window)
# 对于Spark你觉得他对于现有大数据的现状的优势和劣势在哪里?
1.Spark的内存计算 主要体现在哪里? (a) spark, 相比与map reduce最大的速度提升在于做重复计算时,spark可以重复使用相关的缓存数据,而M/R则会笨拙的不断进行disk i/o. (b) 为了提高容错性,M/R所有的中间结果都会persist到disk, 而M/R 则默认保存在内存。 2.目前Spark主要存在哪些缺点? (a) JVM的内存overhead太大,1G的数据通常需要消耗5G的内存 -> Project Tungsten 正试图解决这个问题; (b) 不同的spark app之间缺乏有效的共享内存机制 -> Project Tachyon 在试图引入分布式的内存管理,这样不同的spark app可以共享缓存的数据
spark与hadoop相比,存在哪些缺陷(劣势) - 云+社区 - 腾讯云 (opens new window)
# Spark的Shuffle原理及调优?
用实例说明Spark stage划分原理 - bonelee - 博客园 (opens new window)
# spark如何保证宕机迅速恢复
# RDD的原理以及持久化原理
# spark排序实现流程,reduce端怎么实现的;
# Spark的特点是什么
Spark 特点 - CSDN博客 (opens new window)
- 快速 Spark函数(类似于MapReduce)运行的时候,绝大多数的函数是可以在内存里面去迭代的。只有少部分的函数需要落地到磁盘
- 易用性
- 编写简单,支持80种以上的高级算子,支持多种语言,数据源丰富,可部署在多种集群中
- 通用性
- 兼容性
- 容错性高。
- Spark引进了弹性分布式数据集RDD (Resilient Distributed Dataset) 的抽象,它是分布在一组节点中的只读对象集合,这些集合是弹性的,如果数据集一部分丢失,则可以根据“血统”(即充许基于数据衍生过程)对它们进行重建。另外在RDD计算时可以通过CheckPoint来实现容错,而CheckPoint有两种方式:CheckPoint Data,和Logging The Updates,用户可以控制采用哪种方式来实现容错。
# Spark的三种提交模式是什么
- local(本地模式):常用于本地开发测试,本地还分为local单线程和local-cluster多线程;
- standalone(集群模式):典型的Mater/slave模式,不过也能看出Master是有单点故障的;Spark支持ZooKeeper来实现 HA
- on yarn(集群模式): 运行在 yarn 资源管理器框架之上,由 yarn 负责资源管理,Spark 负责任务调度和计算
- on mesos(集群模式): 运行在 mesos 资源管理器框架之上,由 mesos 负责资源管理,Spark 负责任务调度和计算
- on cloud(集群模式):比如 AWS 的 EC2,使用这个模式能很方便的访问 Amazon的 S3;Spark 支持多种分布式存储系统:HDFS 和 S3
# spark 实现高可用性:High Availability?
# spark中怎么解决内存泄漏问题?
Spark面对OOM问题的解决方法及优化总结 - CSDN博客 (opens new window)
# Spark-submit模式yarn-cluster和yarn-client的区别
- yarn-client用于测试,因为他的Driver运行在本地客户端,会与yarn集群产生较大的网络通信,从而导致网卡流量激增;它的好处在于直接执行时,在本地可以查看到所有的log,方便调试;
- yarn-cluster用于生产环境,因为Driver运行在NodeManager,相当于一个ApplicationMaster,没有网卡流量激增的问题;缺点在于调试不方便,本地用spark-submit提交后,看不到log,只能通过yarn application_id这种命令来查看,很麻烦
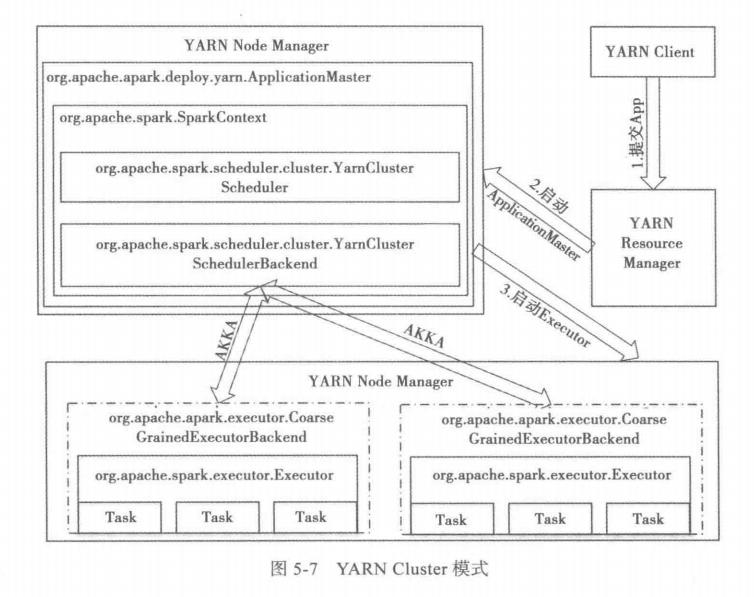

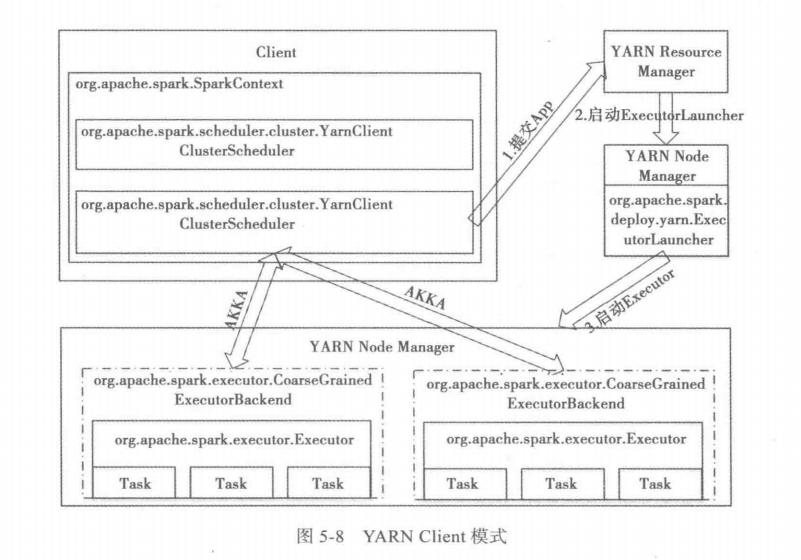

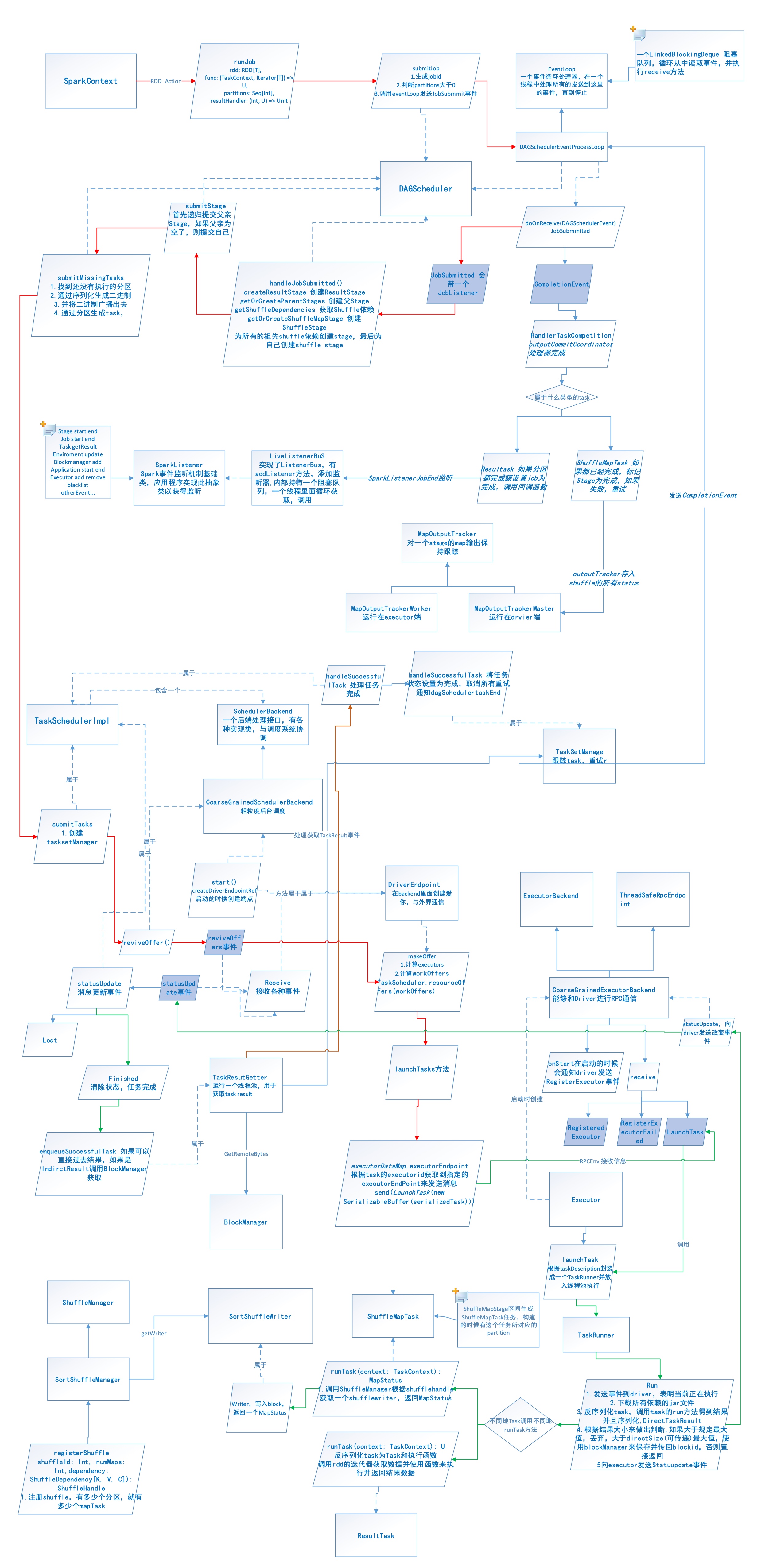
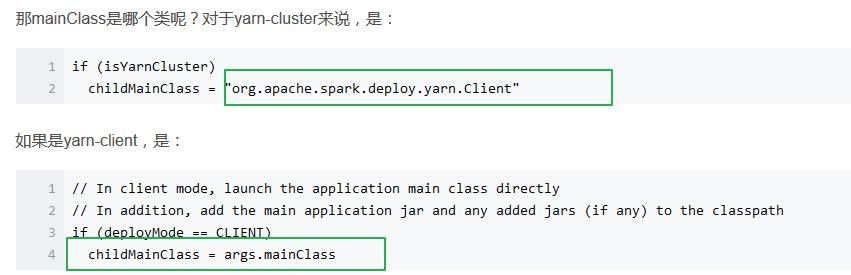
# spark运行原理,从提交一个jar到最后返回结果,整个过程
- 用户通过spark-submit脚本提交应用。
- spark-submit根据用户代码及配置确定使用哪个资源管理器,以及在合适的位置启动driver。
- driver与集群管理器(如YARN)通信,申请资源以启动executor。
- 集群管理器启动executor。
- driver进程执行用户的代码,根据程序中定义的transformation和action,进行stage的划分,然后以task的形式发送到executor。(通过DAGScheduler划分stage,通过TaskScheduler和TaskSchedulerBackend来真正申请资源运行task)
- task在executor中进行计算并保存结果。
- 如果driver中的main()方法执行完成退出,或者调用了SparkContext#stop(),driver会终止executor进程,并且通过集群管理器释放资源。
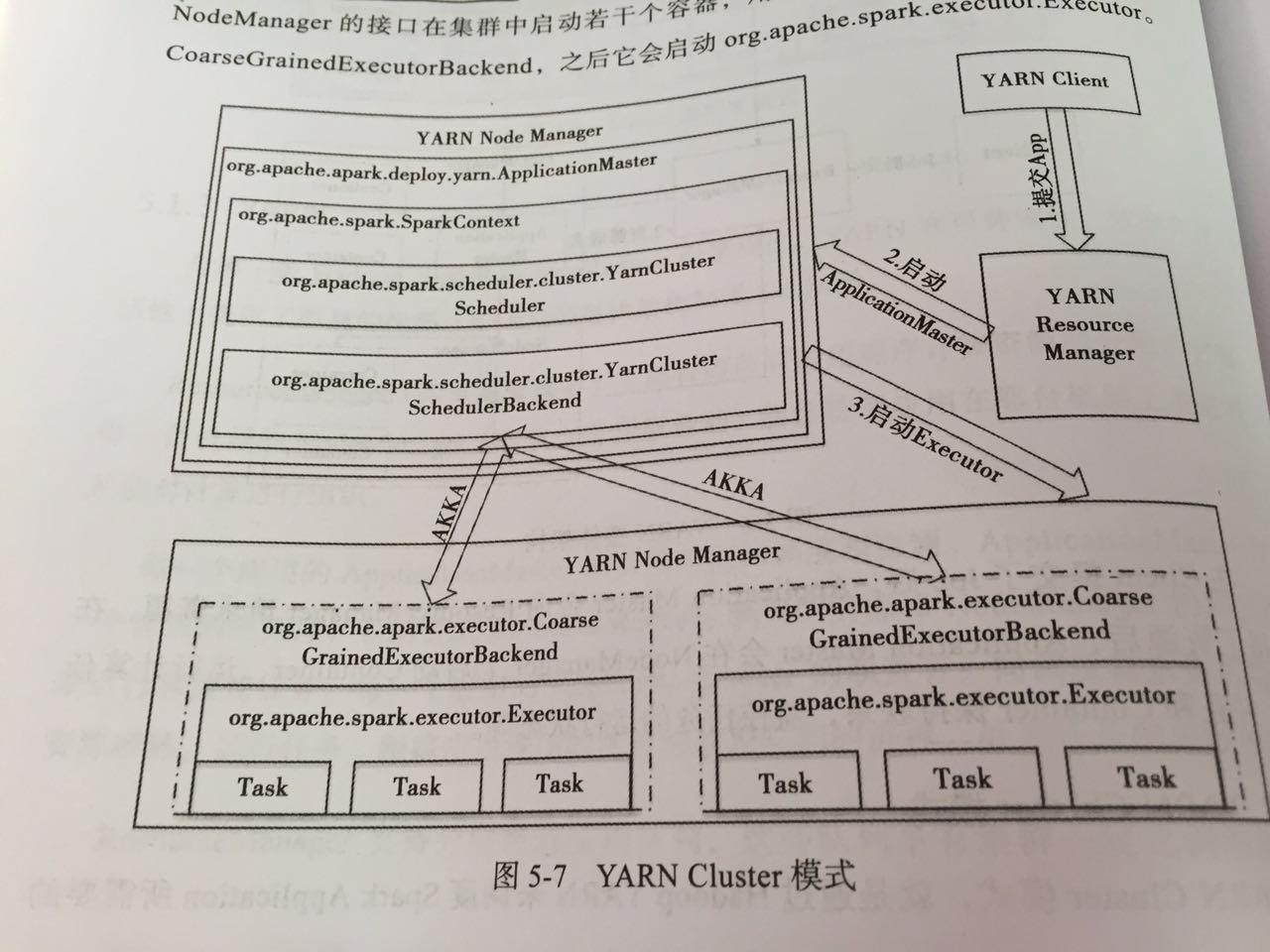
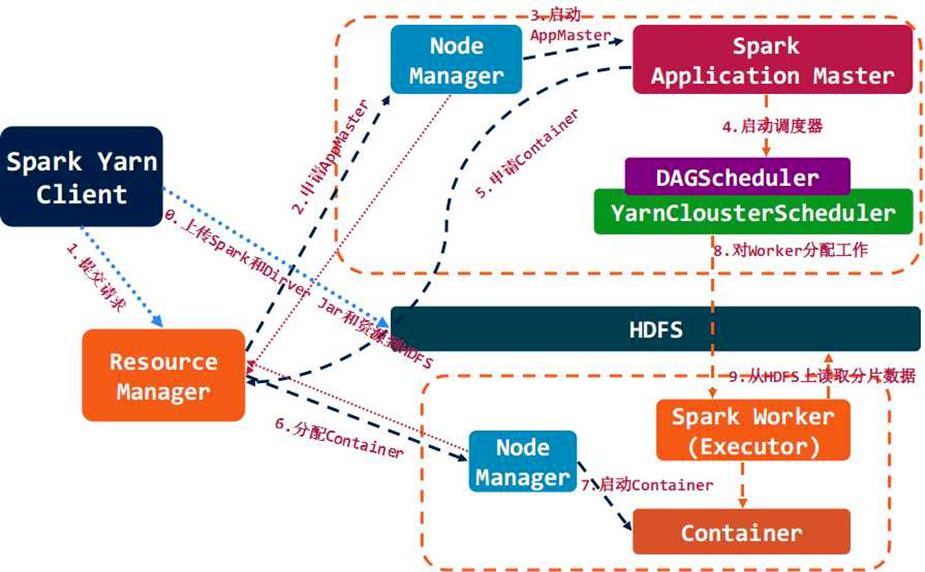
# Yarn-Cluster
步骤一:Client类提交应用到YARN ResourceManager,向RM申请资源作为AM 步骤二:在申请到的机器中启动driver,注册成为AM,并调用用户代码,然后创建SparkContext。(driver是一个逻辑概念,并不实际存在,通过抽象出driver这一层,所有的运行模式都可以说是在driver中调用用户代码了) 步骤三:SparkContext中创建DAGScheduler与YarnClusterScheduler与YarnClusterSchedulerBackend。当在用户代码中遇到action时,即会调用DAGScheduler的runJob,任务开始调度执行。 步骤四:YarnClusterSchedulerBackend在NodeManager上启动Executor 步骤五:Executor启动Task,开始执行任务
# Yarn-Client
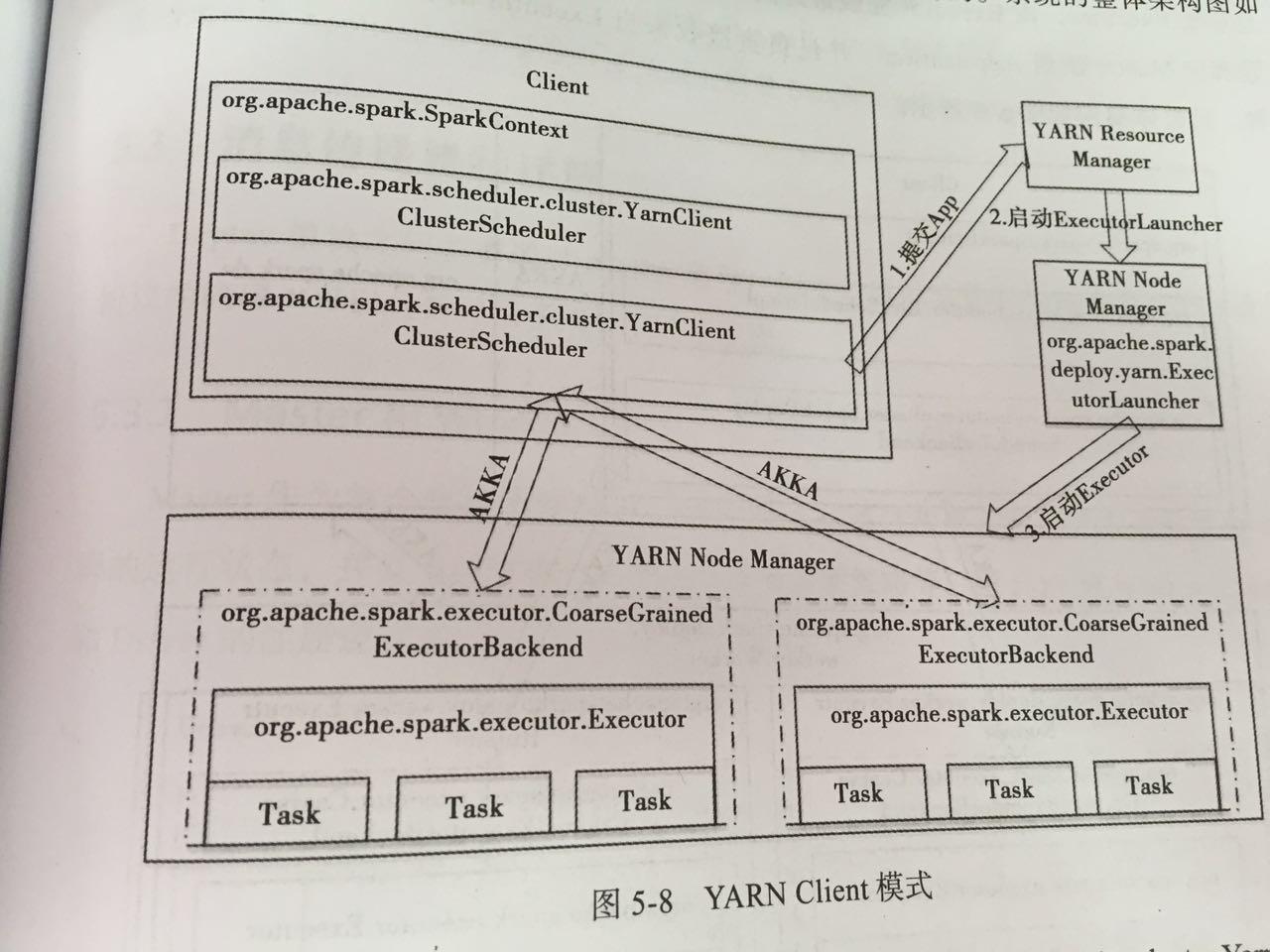
参考 spark提交应用的全流程分析 - CSDN博客 (opens new window)
# spark的stage划分是怎么实现的?拓扑排序?怎么实现?还有什么算法实现?
宽依赖就是stage划分的依据
# spark rpc,spark2.0为啥舍弃了akka,而用netty
# spark的各种shuffle,与mapreduce的对比;
# spark的各种ha,master的ha,worker的ha,executor的ha,driver的ha,task的ha,在容错的时候对集群或是task有什么影响?
# spark的内存管理机制,spark1.6前后对比分析
# spark2.0做出了哪些优化?tungsten引擎?cpu与内存两个方面分别说明
# spark rdd、dataframe、dataset区别
# HashPartitioner与RangePartitioner的实现,以及水塘抽样;
# spark有哪几种join,使用场景,以及实现原理
# dagschedule、taskschedule、schedulebankend实现原理;


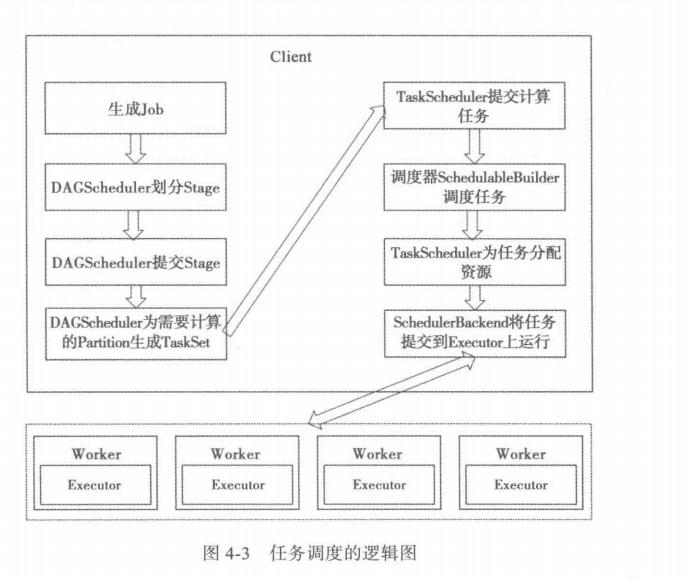

stage 划分

宽依赖就是认为是Dagd的分界线,或者说根据宽依赖将job分为不同的阶段(stage)

# 宽依赖、窄依赖的概念?宽依赖、窄依赖的例子?以下图中所指的是何种依赖
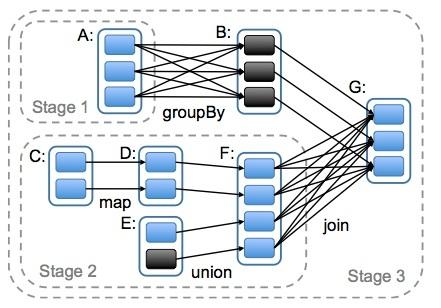
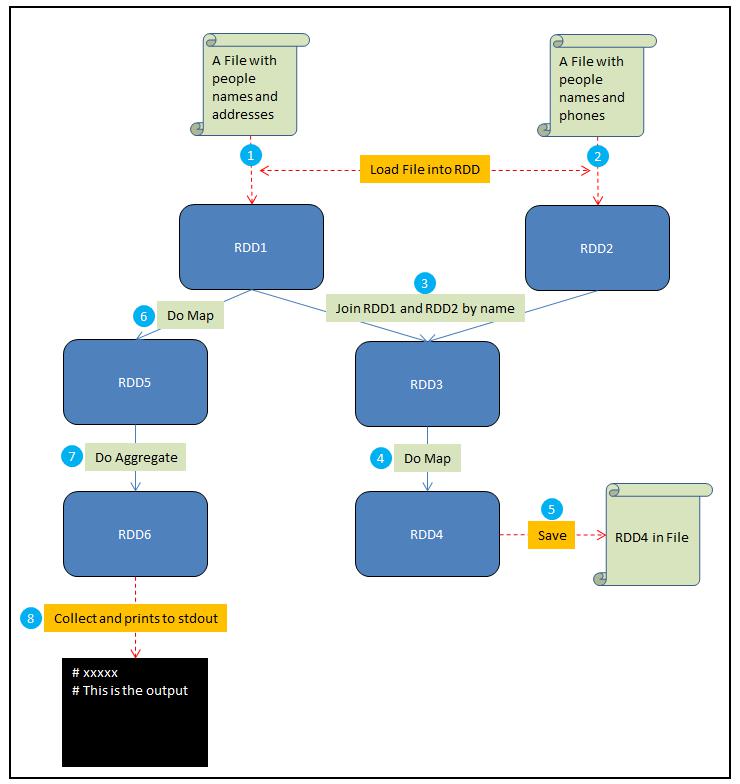

# Spark数据倾斜,怎么定位、怎么解决(阿里);
spark提交应用的全流程分析 - CSDN博客 (opens new window)
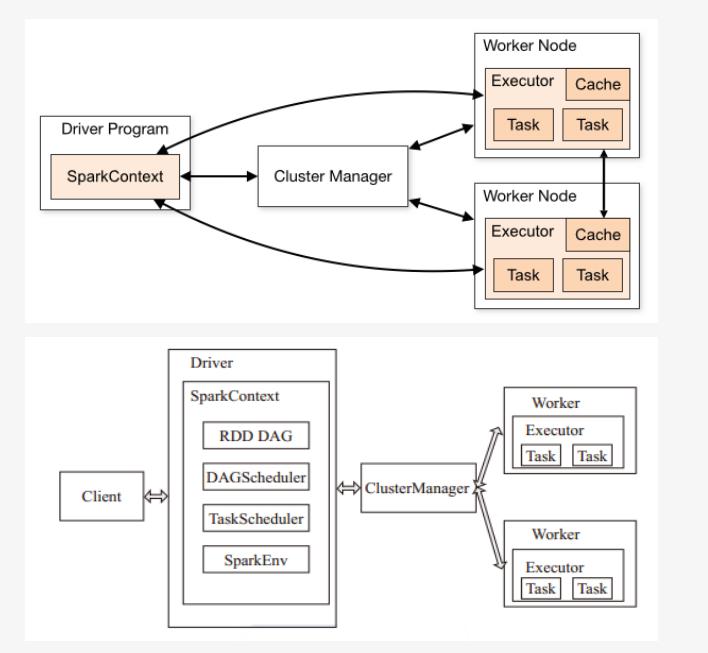
# spark有哪些组件?
- master:管理集群和节点,不参与计算。
- worker:计算节点,进程本身不参与计算,和master汇报。
- Driver:运行程序的main方法,创建spark context对象。
- spark context:控制整个application的生命周期,包括dagsheduler和task scheduler等组件。
- client:用户提交程序的入口。
# Spark的适用场景
- 复杂的批量处理(Batch Data Processing),偏重点在于处理海量数据的能力,至于处理速度可忍受,通常的时间可能是在数十分钟到数小时;
- 基于历史数据的交互式查询(Interactive Query),通常的时间在数十秒到数十分钟之间
- 基于实时数据流的数据处理(Streaming Data Processing),通常在数百毫秒到数秒之间
# spark 架构
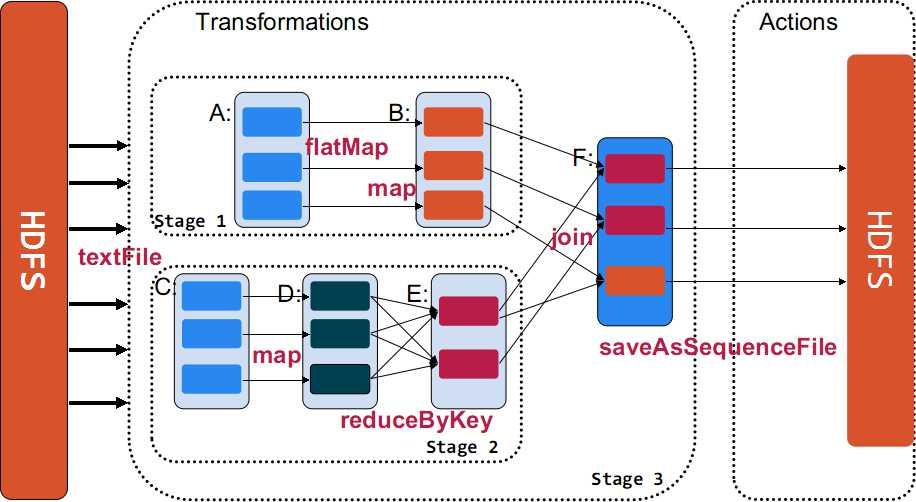
# spark task解析?

# spark 集群 100g内存 有两百g文件,去读取,有什么问题
- 内存有限的情况下 Spark 如何处理 T 级别的数据 - abcde - CSDN博客 (opens new window)
- 只有在用户要求Spark cache该RDD,且storage level要求在内存中cache时,Iterator计算出的结果才会被保留,通过cache manager放入内存池
# Spark 优化
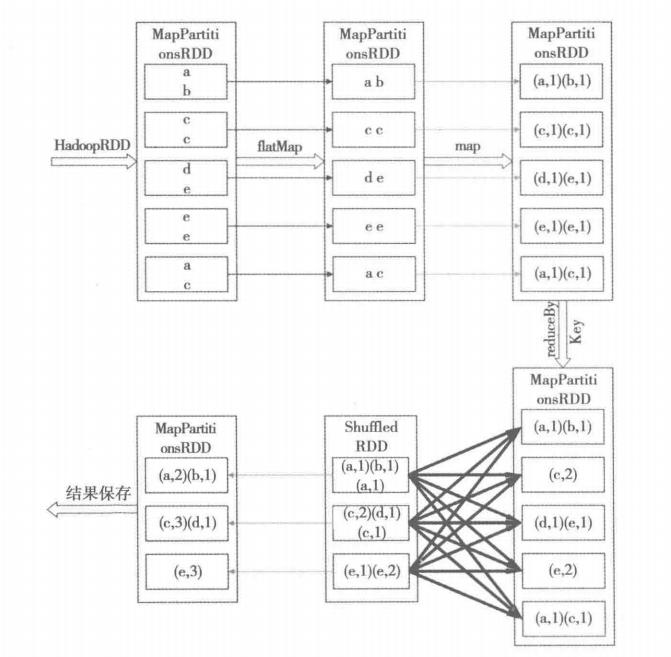
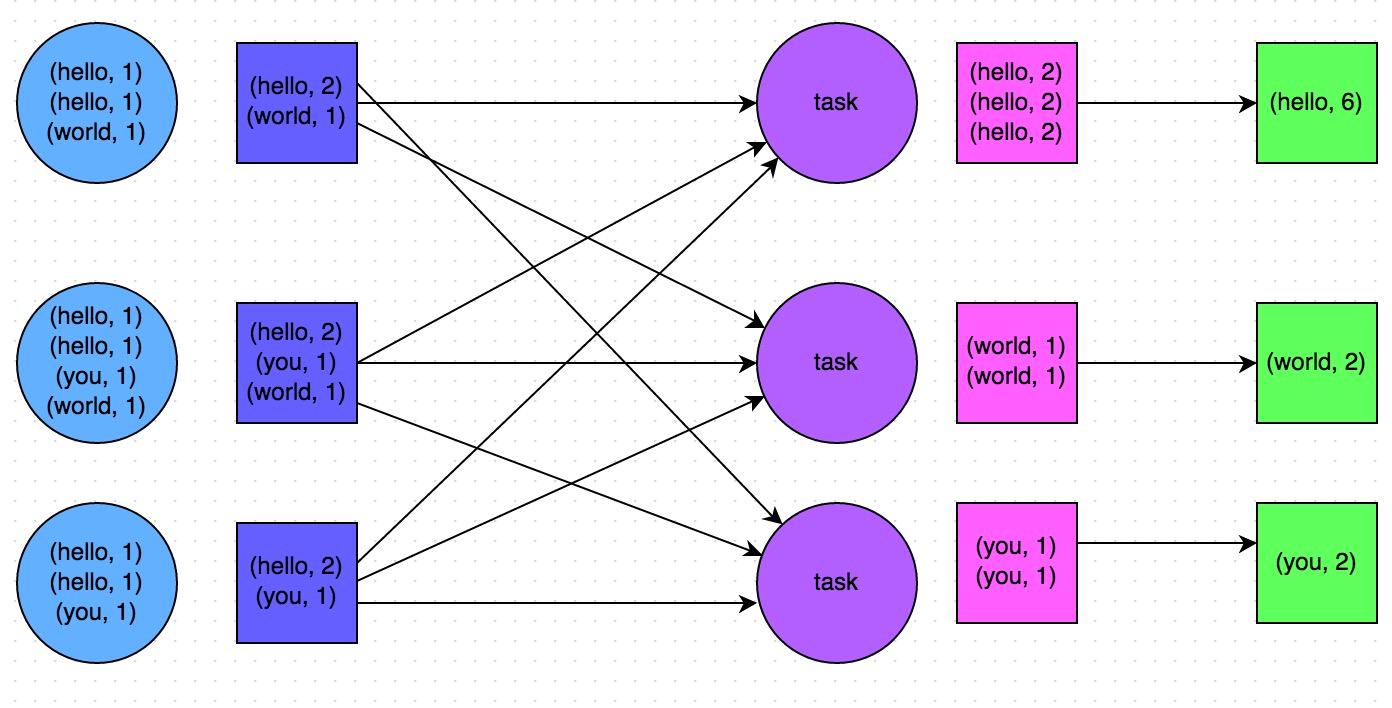
# reduceByKey或者aggregateByKey与groupByKey的区别?
因为reduceByKey和aggregateByKey算子都会使用用户自定义的函数对每个节点本地的相同key进行预聚合。而groupByKey算子是不会进行预聚合的,全量的数据会在集群的各个节点之间分发和传输,性能相对来说比较差。
比如如下两幅图,就是典型的例子,分别基于reduceByKey和groupByKey进行单词计数。其中第一张图是groupByKey的原理图,可以看到,没有进行任何本地聚合时,所有数据都会在集群节点之间传输;第二张图是reduceByKey的原理图,可以看到,每个节点本地的相同key数据,都进行了预聚合,然后才传输到其他节点上进行全局聚合。
# 如何使用高性能的算子?
- 使用reduceByKey/aggregateByKey替代groupByKey
- 使用mapPartitions替代普通map 可能出现OOM 因为可能一个分区数据量太大
- 使用foreachPartitions替代foreach 比如讲分区数据写入到mysql
- 使用filter之后进行coalesce操作 减少分区的数量
- 使用repartitionAndSortWithinPartitions替代repartition与sort类操作
- repartitionAndSortWithinPartitions是Spark官网推荐的一个算子,官方建议,如果需要在repartition重分区之后,还要进行排序,建议直接使用repartitionAndSortWithinPartitions算子。因为该算子可以一边进行重分区的shuffle操作,一边进行排序。shuffle与sort两个操作同时进行,比先shuffle再sort来说,性能可能是要高的。
参考 Spark性能优化指南——基础篇 - (opens new window)
# Spark Shuffle 数据倾斜的解决方案
- 解决方案一:使用Hive ETL预处理数据 适用Hive join
- 解决方案二:过滤少数导致倾斜的key
- 解决方案三:提高shuffle操作的并行度 spark.sql.shuffle.partitions reduceByKey(1000)
- 解决方案四:两阶段聚合(局部聚合+全局聚合)打随机数,预聚合,然后去掉随机数,在进行全局聚合 适用于聚合类型,如果是join类的shuffle操作,还得用其他的解决方案。
- 解决方案五:将reduce join转为map join 在对RDD使用join类操作,或者是在Spark SQL中使用join语句时,而且join操作中的一个RDD或表的数据量比较小(比如几百M或者一两G),比较适用此方案。
- 不使用join算子进行连接操作,而使用Broadcast变量与map类算子实现join操作,进而完全规避掉shuffle类的操作,彻底避免数据倾斜的发生和出现。
- 对join操作导致的数据倾斜,效果非常好,因为根本就不会发生shuffle,也就根本不会发生数据倾斜。 适用场景较少,因为这个方案只适用于一个大表和一个小表的情况
- 解决方案六:采样倾斜key并分拆join操作
- 采样倾斜key并分拆join操作
方案适用场景:两个RDD/Hive表进行join的时候,如果数据量都比较大,无法采用“解决方案五”,那么此时可以看一下两个RDD/Hive表中的key分布情况。如果出现数据倾斜,是因为其中某一个RDD/Hive表中的少数几个key的数据量过大,而另一个RDD/Hive表中的所有key都分布比较均匀,那么采用这个解决方案是比较合适的。
方案实现思路:
对包含少数几个数据量过大的key的那个RDD,通过sample算子采样出一份样本来,然后统计一下每个key的数量,计算出来数据量最大的是哪几个key。
然后将这几个key对应的数据从原来的RDD中拆分出来,形成一个单独的RDD,并给每个key都打上n以内的随机数作为前缀,而不会导致倾斜的大部分key形成另外一个RDD。
接着将需要join的另一个RDD,也过滤出来那几个倾斜key对应的数据并形成一个单独的RDD,将每条数据膨胀成n条数据,这n条数据都按顺序附加一个0~n的前缀,不会导致倾斜的大部分key也形成另外一个RDD。
再将附加了随机前缀的独立RDD与另一个膨胀n倍的独立RDD进行join,此时就可以将原先相同的key打散成n份,分散到多个task中去进行join了。
而另外两个普通的RDD就照常join即可。
最后将两次join的结果使用union算子合并起来即可,就是最终的join结果。
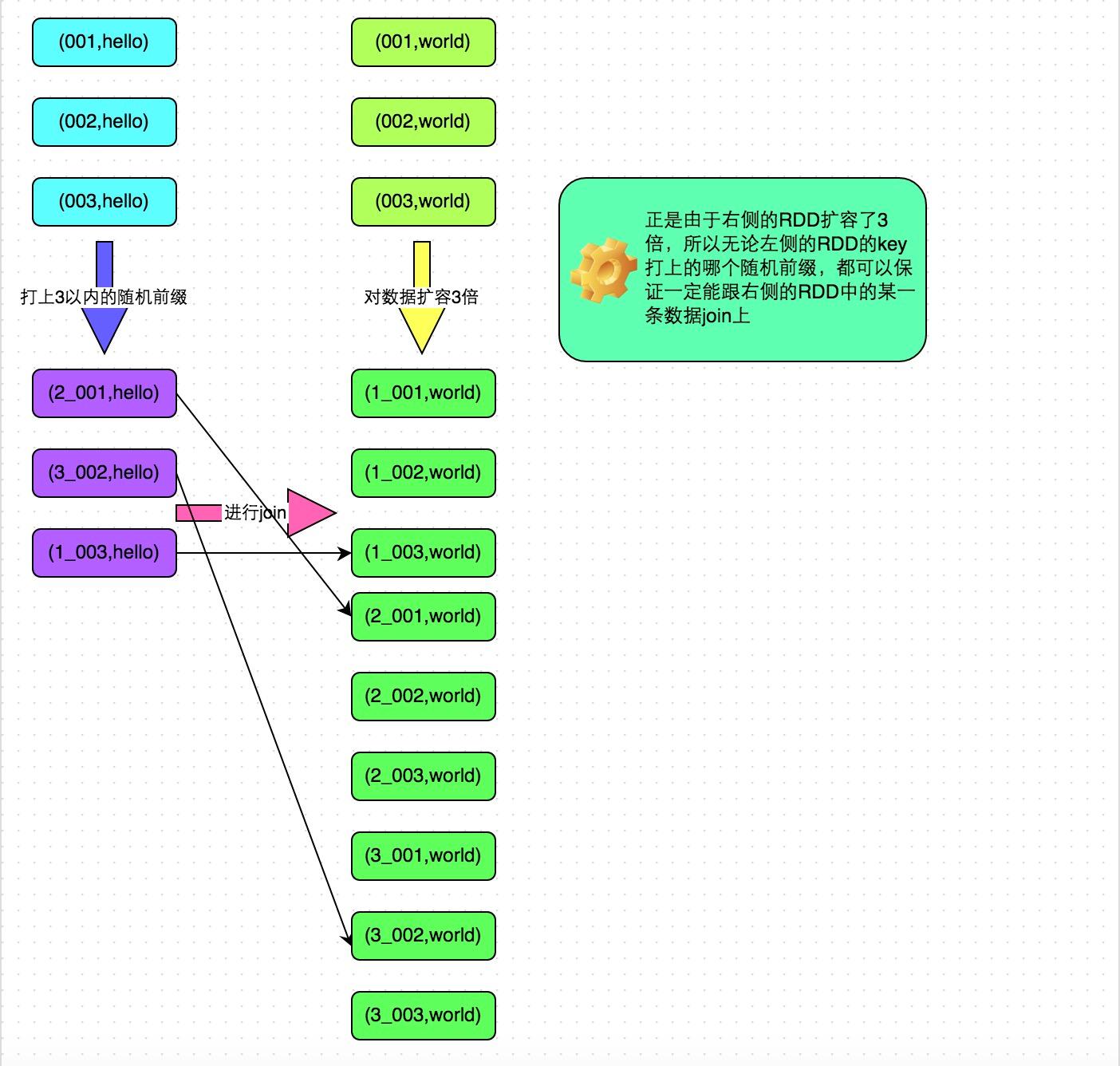
- 采样倾斜key并分拆join操作
方案适用场景:两个RDD/Hive表进行join的时候,如果数据量都比较大,无法采用“解决方案五”,那么此时可以看一下两个RDD/Hive表中的key分布情况。如果出现数据倾斜,是因为其中某一个RDD/Hive表中的少数几个key的数据量过大,而另一个RDD/Hive表中的所有key都分布比较均匀,那么采用这个解决方案是比较合适的。
方案实现思路:
对包含少数几个数据量过大的key的那个RDD,通过sample算子采样出一份样本来,然后统计一下每个key的数量,计算出来数据量最大的是哪几个key。
然后将这几个key对应的数据从原来的RDD中拆分出来,形成一个单独的RDD,并给每个key都打上n以内的随机数作为前缀,而不会导致倾斜的大部分key形成另外一个RDD。
接着将需要join的另一个RDD,也过滤出来那几个倾斜key对应的数据并形成一个单独的RDD,将每条数据膨胀成n条数据,这n条数据都按顺序附加一个0~n的前缀,不会导致倾斜的大部分key也形成另外一个RDD。
再将附加了随机前缀的独立RDD与另一个膨胀n倍的独立RDD进行join,此时就可以将原先相同的key打散成n份,分散到多个task中去进行join了。
而另外两个普通的RDD就照常join即可。
最后将两次join的结果使用union算子合并起来即可,就是最终的join结果。
- 解决方案七:使用随机前缀和扩容RDD进行join
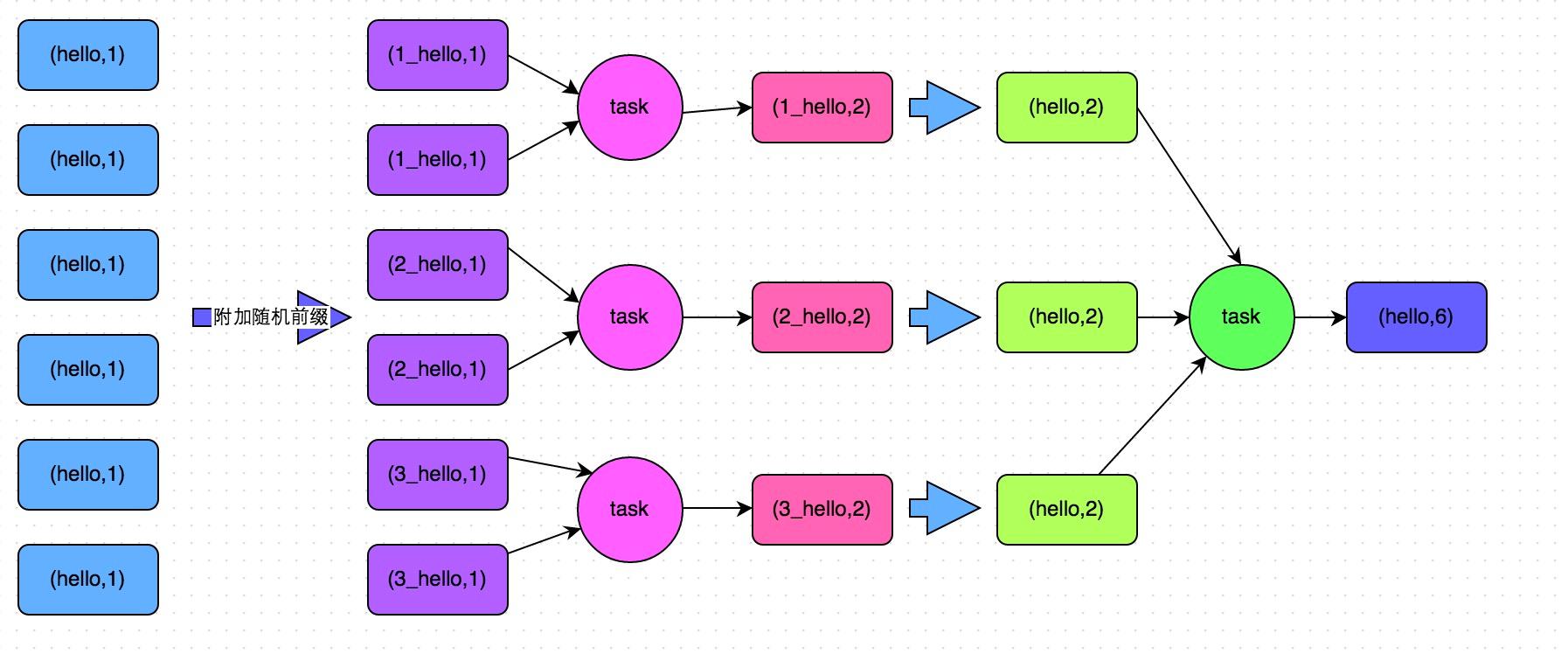
Spark性能优化指南——高级篇 - (opens new window)
# 原理
# Spark的任务提交和执行流程详解
Spark的任务提交和执行流程详解_好学若饥,谦卑若愚-CSDN博客 (opens new window)
← Spark Streaming Flink →