# Flink
# Flink 容错机制
# 介绍
【译】Apache Flink 容错机制 - 苏州谷歌开发者社区 - SegmentFault 思否 (opens new window)
- Apache Flink 提供了可以恢复数据流应用到一致状态的容错机制
- 发生故障时,程序的每条记录只会作用于状态一次(exactly-once)
- 容错机制通过持续创建分布式数据流的快照来实现
- 轻量
- 可配置
- 性能影响小
- 为了容错机制生效,数据源(例如 queue 或者 broker)需要能重放数据流
# Checkpointing
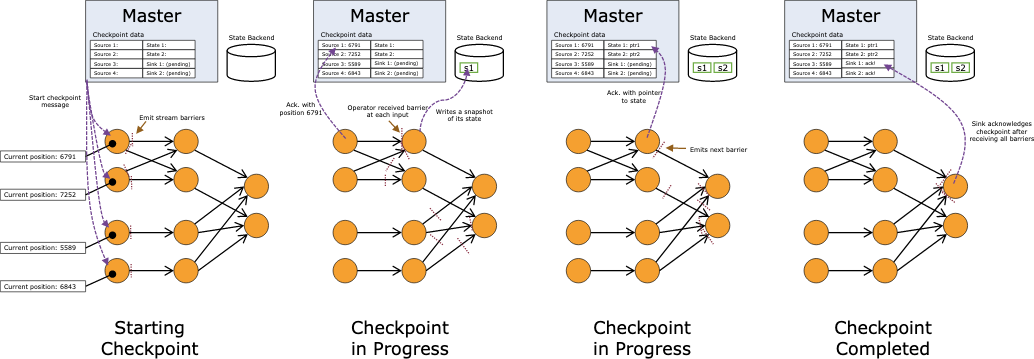
- Flink 容错机制的核心就是持续创建分布式数据流及其状态的一致快照
- 遇到故障,充当可以回退的一致性检查点(checkpoint)
- 受分布式快照算法 Chandy-Lamport (opens new window) 启发
# CopyOnWriteStateTable
# Barriers
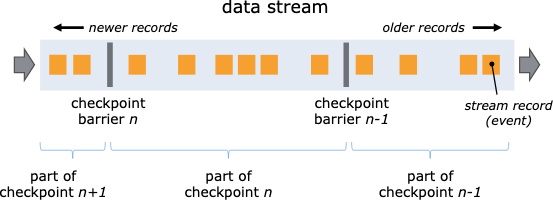
快照核心概念- 数据栅栏
插入到数据流中,同数据流动
Barrier 分割数据流, 前面一部分进入到当前快照,另一部分进入到下一次,每个Barrier有快照ID,并且之前的数据进入了此快照。

# State
# 扩缩容
Flink状态的缩放(rescale)与键组(Key Group)设计_LittleMagic's Blog-CSDN博客_flink keygroup (opens new window)
# 参考博客
- Apache-Flink深度解析-State - 掘金 (opens new window)
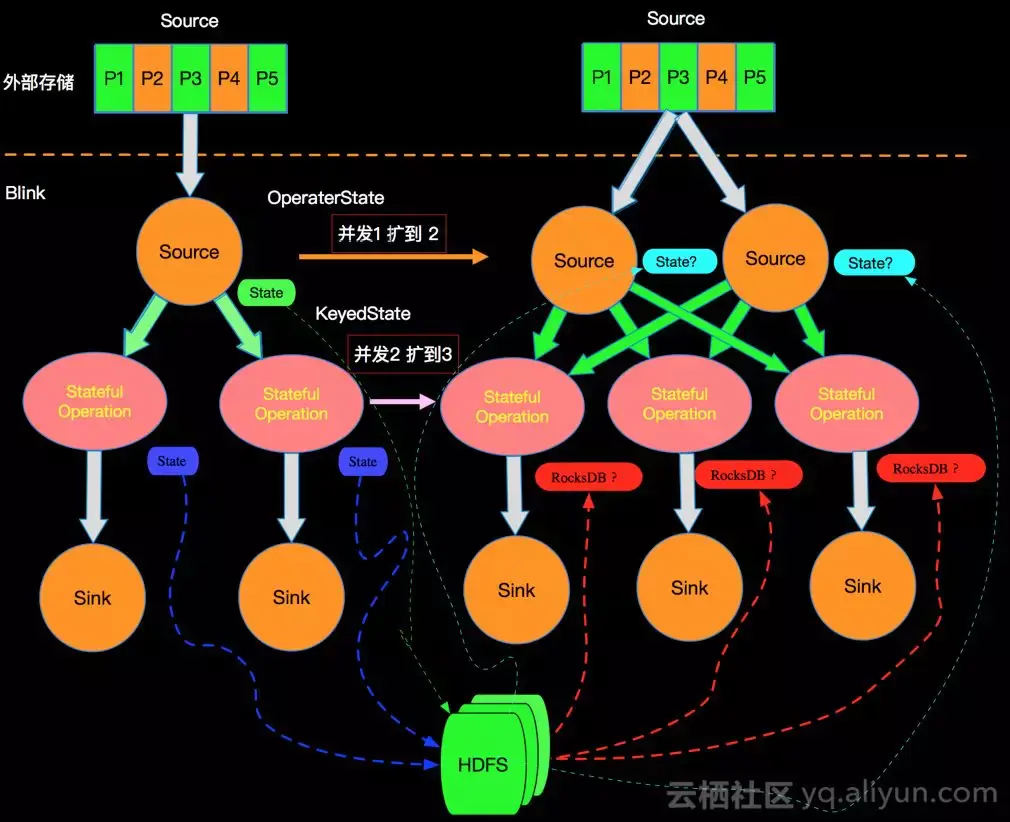
- Apache Flink的DAG图中只有边相连的节点有网络通信 也就是整个DAG在垂直方向有网络IO,在水平方向如下图的stateful节点之间没有网络通信
- 这种模型也保证了每个operator实例维护一份自己的state,并且保存在本地磁盘
- 扩容
 +
+- Keystone 扩容
- hash(key) mod parallelism(operator) 这种分配方式大多数情况是恢复的state不是本地已有的state 需要一次网络拷贝 OperatorState采用这种简单的方式进行处理是因为OperatorState的state一般都比较小,网络拉取的成本很小
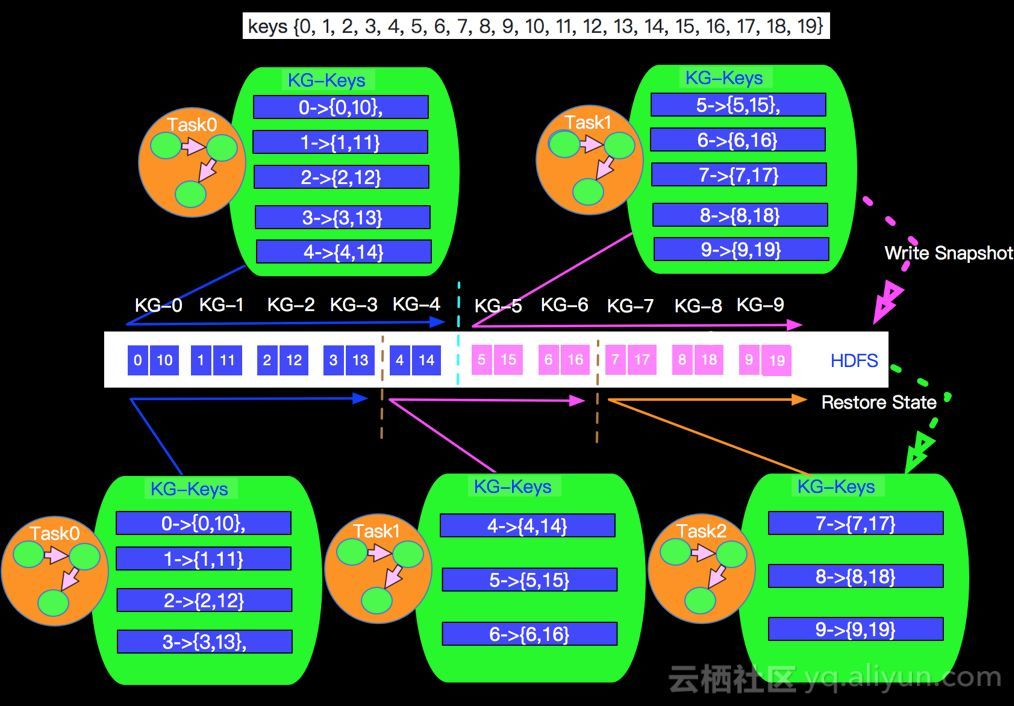
- 在Apache Flink中采用的是Key-Groups方式进行分配。
- 什么决定Key-Groups的个数
- key-group的数量在job启动前必须是确定的且运行中不能改变。由于key-group是state分配的原子单位,而每个operator并行实例至少包含一个key-group
- 如何决定每个Key属于哪个Key-Group呢?我们采取的是取mod的方式,在KeyGroupRangeAssignment中的assignToKeyGroup方法会将key划分到指定的key-group中
形式
- 用户自定义状态
- 系统状态,缓存数据,windows buffer
存储
- 默认存储在JobManager内存之中
- 生产一部分配置在可靠的分布式存储系统(HDFS)
包含
- 对于并行输入数据源:快照创建时数据流中的位置偏移
- 对于 operator:存储在快照中的状态指针
# Exactly Once vs. At Least Once
- 对齐操作可能会对流程序增加延迟
- Flink 提供了在 checkpoint 时关闭对齐的方法。当 operator 接收到一个 barrier 时,就会打一个快照,而不会等待其他 barrier,会继续处理数据,而当异常恢复的时候,就会有数据被重复输入,也就是At least once
- 对齐操作只会发生在拥有多输入运算(join)或者多个输出的 operator(重分区、分流)的场景下. Map filter严格仅一次
# Asynchronous State Snapshots
- 存储快照的时候,operator继续处理数据
- 使用rocksdb使用写时复制(copy on write) 类型数据结构
# Recovery
一旦遇到故障,Flink 选择最近一个完成的 checkpoint k。系统重新部署整个分布式数据流,重置所有 operator 的状态到 checkpoint k。数据源被置为从 Sk 位置读取
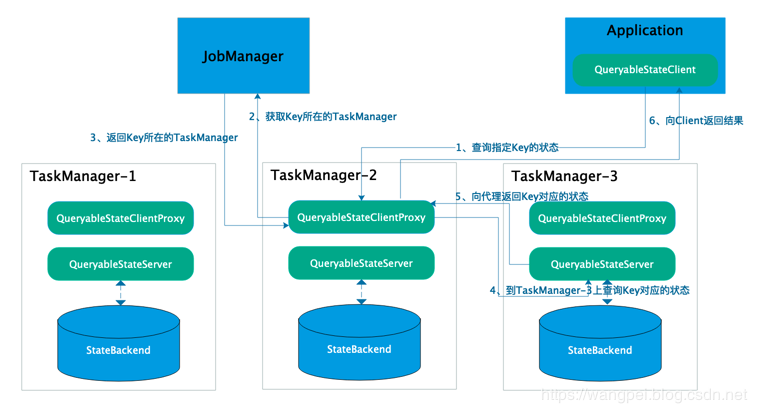
# 可查询状态
# 定时器(Timer)
TimerService 在内部维护两种类型的定时器(处理时间和事件时间定时器)并排队执行。
TimerService 会删除每个键和时间戳重复的定时器,即每个键在每个时间戳上最多有一个定时器。如果为同一时间戳注册了多个定时器,则只会调用一次 onTimer() 方法。
Flink 同步调用 onTimer() 和 processElement() 方法。因此,不必担心状态的并发修改。
ProcessFunction:Flink最底层API使用教程 - 掘金 (opens new window)
# StreamingFileSink 和 BucketingSink
# 参考
Flink1.9系列-StreamingFileSink vs BucketingSink篇_枫叶的落寞的博客-CSDN博客_streamingfilesink (opens new window)
- StreamingFileSink在写hdfs时候,要求hadoop版本必须大于2.7,但是目前市面开源的稳定版本包含cloudera cdh在内,都是支持hadoop2.6,
- 所以如果你使用hadoop版本<2.7,那建议你还是使用BucketingSink
Flink实战之StreamingFileSink如何写数据到其它HA的Hadoop集群_苏苏爱自由-CSDN博客_streamingfilesink flink (opens new window)
Flink HDFS Sink 如何保证 exactly-once 语义_Just for Fun LA-CSDN博客_flink hdfs sink (opens new window)
# Flink Hive 集成
# 参考
- Flink x Zeppelin ,Hive Streaming 实战解析-阿里云开发者社区 (opens new window)
- Hive Streaming 的意义
- Lambda架构 流批分离。离线和实时各自独一份
- 数据口径问题
- 离线计算产出延迟大
- 数据冗余存储
- Kappa架构,完全使用实时计算产出数据,历史数据通过回溯消息的消费位点计算,同样也有很多的问题,毕竟没有一劳永逸的架构。
- 消息中间件无法保留全部历史数据,同样数据都是行式存储,占用空间大
- 实时计算历史数据力不从心
- 无法进行Adhoc的分析
- Hive Streaming 的意义
- 深度解读 Flink 1.11:流批一体 Hive 数仓-阿里云开发者社区 (opens new window)
- 传统离线数仓是由 Hive 加上 HDFS 的方案,Hive 数仓有着成熟和稳定的大数据分析能力,结合调度和上下游工具,构建一个完整的数据处理分析平台
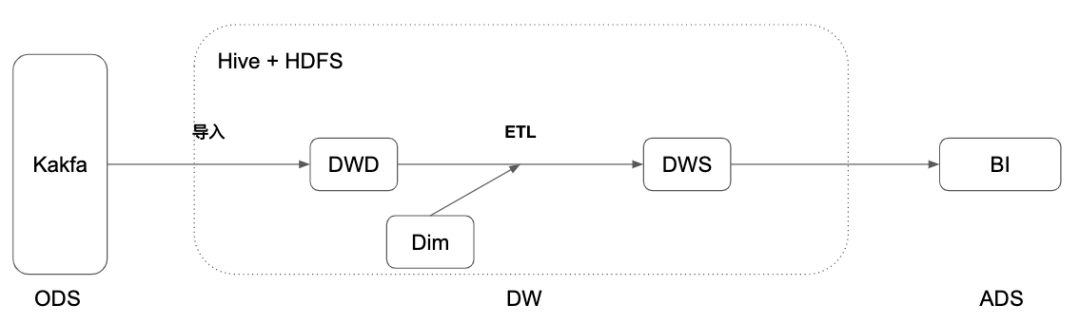
- 离线数仓
- 流程
- Flume 把数据导入 Hive 数仓
- 调度工具,调度 ETL 作业进行数据处理
- 在 Hive 数仓的表上,可以进行灵活的 Ad-hoc 查询
- 调度工具,调度聚合作业输出到BI层的数据库中
- 问题
- 导入过程不够灵活,这应该是一个灵活 SQL 流计算的过程
- 基于调度作业的级联计算,实时性太差
- ETL 不能有流式的增量计算
- 流程
- 实时数仓
- 实时数仓,实时数仓基于 Kafka + Flink streaming,定义全流程的流计算作业,有着秒级甚至毫秒的实时性。
- 问题 : 是历史数据只有 3-15 天,无法在其上做 Ad-hoc 的查询。如果搭建 Lambda 的离线+实时的架构,维护成本、计算存储成本、一致性保证、重复的开发会带来很大的负担。
- Hive streaming sink
- 带来 Flink streaming 的实时/准实时的能力
- 支持 Filesystem connector 的全部 formats(csv,json,avro,parquet,orc)
- 支持 Hive table 的所有 formats
- 继承 Datastream StreamingFileSink 的所有特性:Exactly-once、支持HDFS, S3
- Partition commit。
- Trigger 什么时候提交
- Policy 提交策略
- Hive streaming source
- 传统Hive ETL 弊端
- 实时性不强,往往调度最小是小时级。
- 流程复杂,组件多,容易出现问题。
- 传统Hive ETL 弊端
- Flink 1.11 为此开发了实时化的 Hive 流读
- Partition 表,监控 Partition 的生成,增量读取新的 Partition。
- 非 Partition 表,监控文件夹内新文件的生成,增量读取新的文件。
- 传统离线数仓是由 Hive 加上 HDFS 的方案,Hive 数仓有着成熟和稳定的大数据分析能力,结合调度和上下游工具,构建一个完整的数据处理分析平台
# HiveCatalog
# 两种类型的表
flink 使用 is_generic 属性累区分一个表是hive兼容表还是通用表,默认是通用表,如果要创建hive兼容表,则需要将 is_generic 设置为false
- Hive 兼容表
- 就存储层中的元数据和数据而言,兼容Hive的表是以兼容Hive的方式存储的表。因此,可以从Hive端查询通过Flink创建的Hive兼容表。
- 通用表
- 用表特定于Flink。使用HiveCatalog创建通用表时,我们只是使用HMS来保留元数据。虽然这些表格对Hive可见,但Hive不太可能能够理解元数据。因此,在Hive中使用此类表会导致未定义的行为。
# Hive方言
从1.11开始,使用Hive方言的时候,flink允许用户使用hive语法编写sql,通过提供与hive兼容性,改善互操作性,减少切换
# 两种方言
- HIve
- default
# 2. 设置方式
# SQL Client
yaml文件设置
execution: planner: blink type: batch result-mode: table configuration: table.sql-dialect: hive
set 属性
Flink SQL> set table.sql-dialect=hive; -- to use hive dialect [INFO] Session property has been set. Flink SQL> set table.sql-dialect=default; -- to use default dialect [INFO] Session property has been set.
# Table API
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner()...build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
// to use hive dialect
tableEnv.getConfig().setSqlDialect(SqlDialect.HIVE);
// to use default dialect
tableEnv.getConfig().setSqlDialect(SqlDialect.DEFAULT);
# Flink启动与停止
# Flink流式人物何时停止?
Apache Flink User Mailing List archive. - Signal for End of Stream (opens new window)
Flink will automatically stop the execution of a DataStream program once all sources have finished to provide data, i.e., when all SourceFunction return from the run() method. The DeserializationSchema.isEndOfStream() method can be used to tell a built-in SourceFunction such as a KafkaConsumer that it should leave the run() method. If you implement your own SourceFunction you can leave run() after you ingested all data. Note, that Flink won't wait for all processing time timers but will immediately shutdown the program after the last in-flight record was processed. Event-time timers will be handled because each source emits a Long.MAX_VALUE watermark after it emitted its last record.
一旦所有源都已完成提供数据,即当所有SourceFunction从run()方法返回时,Flink将自动停止执行DataStream程序。 DeserializationSchema.isEndOfStream()方法可用于告知诸如KafkaConsumer之类的内置SourceFunction应该离开run()方法。 如果实现自己的SourceFunction,则可以在提取所有数据后保留run()。 请注意,Flink不会等待所有处理时间计时器,但是会在处理了最后一个运行中的记录后立即关闭程序。 将处理事件时间计时器,因为每个源在发出最后一条记录后都会发出Long.MAX_VALUE水印。
所以 run方法运行完,这个流就停止了
# Flink应用
# 数据同步
Apache Flink 中文用户邮件列表 - flink mysql cdc + hive streaming疑问 (opens new window)
# 数据去重
谈谈三种海量数据实时去重方案(w/ Flink) - 简书 (opens new window)
# RocketsDB
# LSM-Tree
- 彻底搞懂LSM-Tree (opens new window)
- 24 | RocksDB:不丢数据的高性能KV存储-极客时间 (opens new window)
- https://ranger.uta.edu/~sjiang/pubs/papers/wang14-LSM-SDF.pdf
- 【Paper笔记】The Log structured Merge-Tree(LSM-Tree) · (opens new window)
- Log Structured Merge Trees(LSM) 原理 - LSM - 软件开发 - 深度开源 (opens new window)