# 大数据框架Flink、Blink、SparkStreaming、StructuredStreaming和Storm之间的区别
在 1.2 节中已经跟大家详细介绍了 Flink,那么在本节就主要 Blink、Spark Streaming、Structured Streaming 和Storm 的区别。
# Flink
Flink 是一个针对流数据和批数据分布式处理的引擎,在某些对实时性要求非常高的场景,基本上都是采用 Flink来作为计算引擎,它不仅可以处理有界的批数据,还可以处理无界的流数据,在 Flink 的设计愿想就是将批处理当成是流处理的一种特例。
在 Flink 的母公司 [Data Artisans 被阿里收购](https://www.eu- startups.com/2019/01/alibaba-takes-over-berlin-based-streaming-analytics- startup-data-artisans/)之后,阿里也在开始逐步将内部的 Blink 代码开源出来并合并在 Flink 主分支上。
而 Blink 一个很强大的特点就是它的 SQL API 很强大,社区也在 Flink 1.9 版本将 Blink 开源版本大部分代码合进了 Flink主分支。
# Blink
Blink 是早期阿里在 Flink 的基础上开始修改和完善后在内部创建的分支,然后 Blink目前在阿里服务于阿里集团内部搜索、推荐、广告、菜鸟物流等大量核心实时业务。
 Blink 在阿里内部错综复杂的业务场景中锻炼成长着,经历了内部这么多用户的反馈(各种性能、资源使用率、易用性等诸多方面的问题),Blink都做了针对性的改进。在 Flink Forward China 峰会上,阿里巴巴集团副总裁周靖人宣布 Blink 在 2019 年 1月正式开源,同时阿里也希望 Blink 开源后能进一步加深与 Flink 社区的联动,
Blink 在阿里内部错综复杂的业务场景中锻炼成长着,经历了内部这么多用户的反馈(各种性能、资源使用率、易用性等诸多方面的问题),Blink都做了针对性的改进。在 Flink Forward China 峰会上,阿里巴巴集团副总裁周靖人宣布 Blink 在 2019 年 1月正式开源,同时阿里也希望 Blink 开源后能进一步加深与 Flink 社区的联动,
Blink 开源地址:https://github.com/apache/flink/tree/blink
开源版本 Blink 的主要功能和优化点:
1、Runtime 层引入 Pluggable Shuffle Architecture,开发者可以根据不同的计算模型或者新硬件的需要实现不同的shuffle 策略进行适配;为了性能优化,Blink 可以让算子更加灵活的 chain 在一起,避免了不必要的数据传输开销;在 BroadCastShuffle 模式中,Blink 优化掉了大量的不必要的序列化和反序列化开销;Blink 提供了全新的 JM FailOver 机制,JM发生错误之后,新的 JM 会重新接管整个 JOB 而不是重启 JOB,从而大大减少了 JM FailOver 对 JOB 的影响;Blink 支持运行在 Kubernetes 上。
2、SQL/Table API 架构上的重构和性能的优化是 Blink 开源版本的一个重大贡献。
3、Hive 的兼容性,可以直接用 Flink SQL 去查询 Hive 的数据,Blink 重构了 Flink catalog 的实现,并且增加了两种catalog,一个是基于内存存储的 FlinkInMemoryCatalog,另外一个是能够桥接 Hive metaStore 的HiveCatalog。
4、Zeppelin for Flink
5、Flink Web,更美观的 UI 界面,查看日志和监控 Job 都变得更加方便
对于开源那会看到一个对话让笔者感到很震撼:
Blink 开源后,两个开源项目之间的关系会是怎样的?未来 Flink 和 Blink 也会由不同的团队各自维护吗?
Blink 永远不会成为另外一个项目,如果后续进入 Apache 一定是成为 Flink 的一部分
 在 Blink 开源那会,笔者就将源码自己编译了一份,然后自己在本地一直运行着,感兴趣的可以看看文章 阿里巴巴开源的 Blink实时计算框架真香 (opens new window) ,你会发现 Blink 的 UI还是比较美观和实用的。
在 Blink 开源那会,笔者就将源码自己编译了一份,然后自己在本地一直运行着,感兴趣的可以看看文章 阿里巴巴开源的 Blink实时计算框架真香 (opens new window) ,你会发现 Blink 的 UI还是比较美观和实用的。
如果你还对 Blink 有什么疑问,可以看看下面两篇文章:
阿里重磅开源 Blink:为什么我们等了这么久? (opens new window)
重磅!阿里巴巴 Blink 正式开源,重要优化点解读 (opens new window)
# 1.3.3 Spark
Apache Spark 是一种包含流处理能力的下一代批处理框架。与 Hadoop 的 MapReduce 引擎基于各种相同原则开发而来的 Spark主要侧重于通过完善的内存计算和处理优化机制加快批处理工作负载的运行速度。
Spark 可作为独立集群部署(需要相应存储层的配合),或可与 Hadoop 集成并取代 MapReduce 引擎。
# Spark Streaming
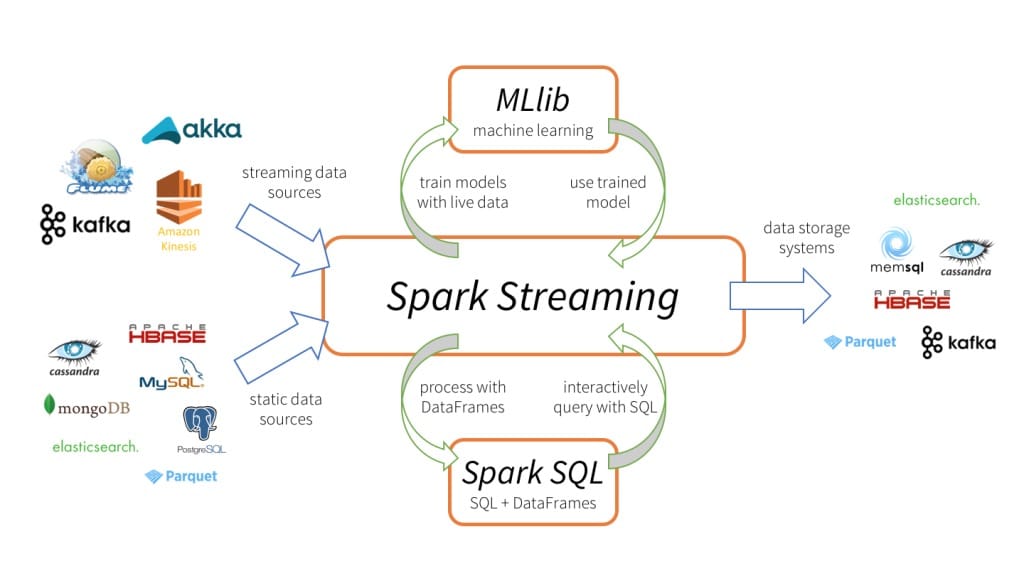 [Spark Streaming](https://spark.apache.org/docs/latest/streaming-programming-
guide.html) 是 Spark API 核心的扩展,可实现实时数据的快速扩展,高吞吐量,容错处理。数据可以从很多来源(如Kafka、Flume、Kinesis 等)中提取,并且可以通过很多函数来处理这些数据,处理完后的数据可以直接存入数据库或者 Dashbard 等。
[Spark Streaming](https://spark.apache.org/docs/latest/streaming-programming-
guide.html) 是 Spark API 核心的扩展,可实现实时数据的快速扩展,高吞吐量,容错处理。数据可以从很多来源(如Kafka、Flume、Kinesis 等)中提取,并且可以通过很多函数来处理这些数据,处理完后的数据可以直接存入数据库或者 Dashbard 等。
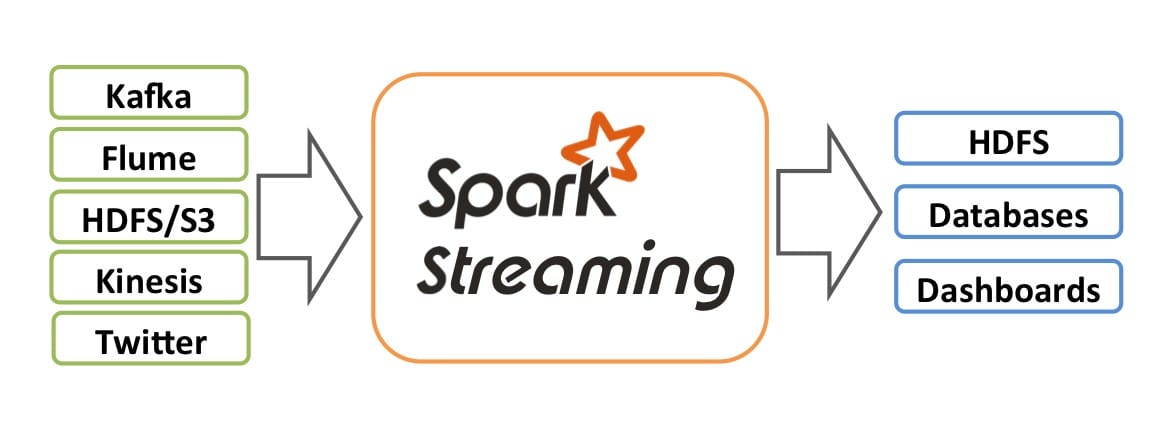 Spark Streaming 的内部实现原理 是接收实时输入数据流并将数据分成批处理,然后由 Spark引擎处理以批量生成最终结果流,也就是常说的 micro-batch 模式。
Spark Streaming 的内部实现原理 是接收实时输入数据流并将数据分成批处理,然后由 Spark引擎处理以批量生成最终结果流,也就是常说的 micro-batch 模式。
 Spark DStreams
Spark DStreams
DStreams 是 Spark Streaming 提供的基本的抽象,它代表一个连续的数据流。。它要么是从源中获取的输入流,要么是输入流通过转换算子生成的处理后的数据流。在内部实现上,DStream 由连续的序列化 RDD 来表示,每个 RDD 含有一段时间间隔内的数据:
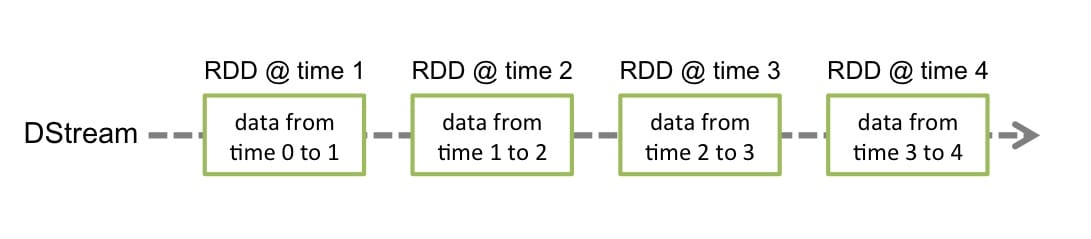 任何对 DStreams 的操作都转换成了对 DStreams 隐含的 RDD 的操作。例如 flatMap 操作应用于 lines 这个 DStreams的每个 RDD,生成 words 这个 DStreams 的 RDD 过程如下图所示:
任何对 DStreams 的操作都转换成了对 DStreams 隐含的 RDD 的操作。例如 flatMap 操作应用于 lines 这个 DStreams的每个 RDD,生成 words 这个 DStreams 的 RDD 过程如下图所示:
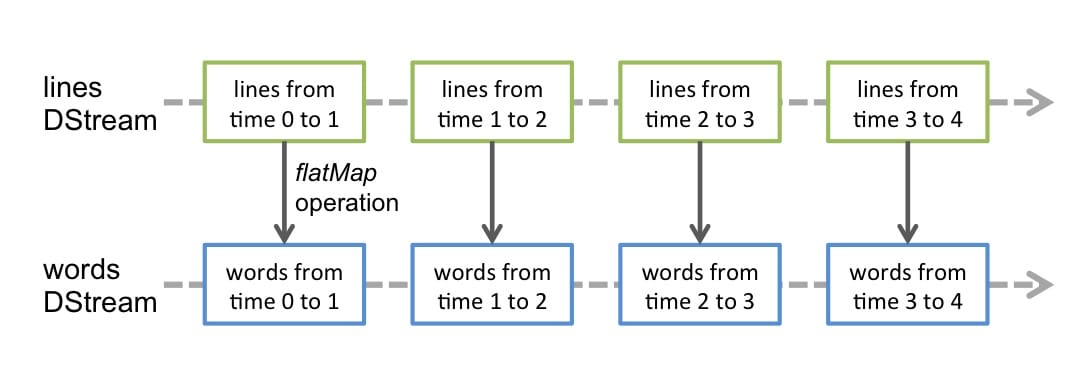 通过 Spark 引擎计算这些隐含 RDD 的转换算子。DStreams 操作隐藏了大部分的细节,并且为了更便捷,为开发者提供了更高层的 API。
通过 Spark 引擎计算这些隐含 RDD 的转换算子。DStreams 操作隐藏了大部分的细节,并且为了更便捷,为开发者提供了更高层的 API。
Spark 支持的滑动窗口
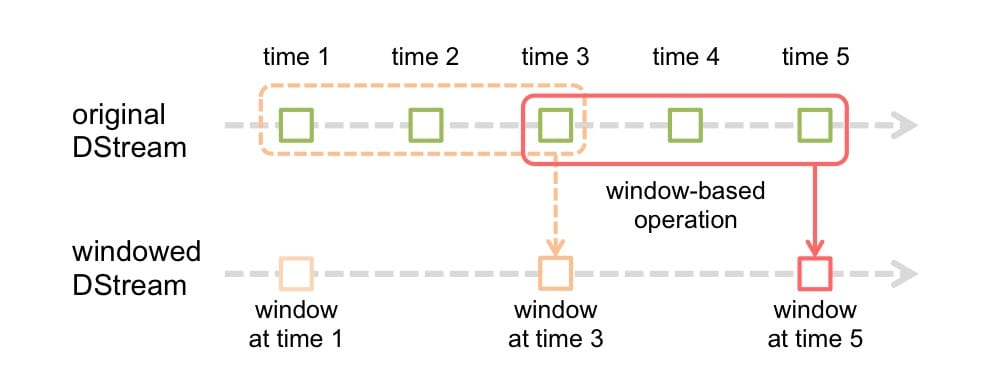 它和 Flink 的滑动窗口类似,支持传入两个参数,一个代表窗口长度,一个代表滑动间隔。
它和 Flink 的滑动窗口类似,支持传入两个参数,一个代表窗口长度,一个代表滑动间隔。
Spark 支持更多的 API
因为 Spark 是使用 Scala 开发的居多,所以从官方文档就可以看得到对 Scala 的 API 支持的很好,而 Flink 源码实现主要以 Java为主,因此也对 Java API 更友好,从两者目前支持的 API 友好程度,应该是 Spark 更好,它目前也支持 Python API,但是 Flink新版本也在不断的支持 Python API。
Spark 支持更多的 Machine Learning Lib
你可以很轻松的使用 Spark MLlib 提供的机器学习算法,然后将这些这些机器学习算法模型应用在流数据中,目前 Flink MachineLearning 这块的内容还较少,不过阿里宣称会开源些 Flink Machine Learning 算法,保持和 Spark目前已有的算法一致,我自己在 GitHub 上看到一个阿里开源的仓库,感兴趣的可以看看 flink-ai- extended (opens new window)。
Spark Checkpoint
Spark 和 Flink 一样都支持 Checkpoint,但是 Flink 还支持 Savepoint,你可以在停止 Flink 作业的时候使用Savepoint 将作业的状态保存下来,当作业重启的时候再从 Savepoint 中将停止作业那个时刻的状态恢复起来,保持作业的状态和之前一致。
Spark SQL
Spark 除了 DataFrames 和 Datasets 外,也还有 SQL API,这样你就可以通过 SQL 查询数据,另外 Spark SQL还可以用于从 Hive 中读取数据。
从 Spark 官网也可以看到很多比较好的特性,这里就不一一介绍了,如果对 Spark感兴趣的话也可以去官网 (opens new window)了解一下具体的使用方法和实现原理。
Spark Streaming 优缺点
1、优点
- Spark Streaming 内部的实现和调度方式高度依赖 Spark 的 DAG 调度器和 RDD,这就决定了 Spark Streaming 的设计初衷必须是粗粒度方式的,也就无法做到真正的实时处理
- Spark Streaming 的粗粒度执行方式使其确保“处理且仅处理一次”的特性,同时也可以更方便地实现容错恢复机制。
- 由于 Spark Streaming 的 DStream 本质是 RDD 在流式数据上的抽象,因此基于 RDD 的各种操作也有相应的基于 DStream 的版本,这样就大大降低了用户对于新框架的学习成本,在了解 Spark 的情况下用户将很容易使用 Spark Streaming。
2、缺点
- Spark Streaming 的粗粒度处理方式也造成了不可避免的数据延迟。在细粒度处理方式下,理想情况下每一条记录都会被实时处理,而在 Spark Streaming 中,数据需要汇总到一定的量后再一次性处理,这就增加了数据处理的延迟,这种延迟是由框架的设计引入的,并不是由网络或其他情况造成的。
- 使用的是 Processing Time 而不是 Event Time
# Structured Streaming
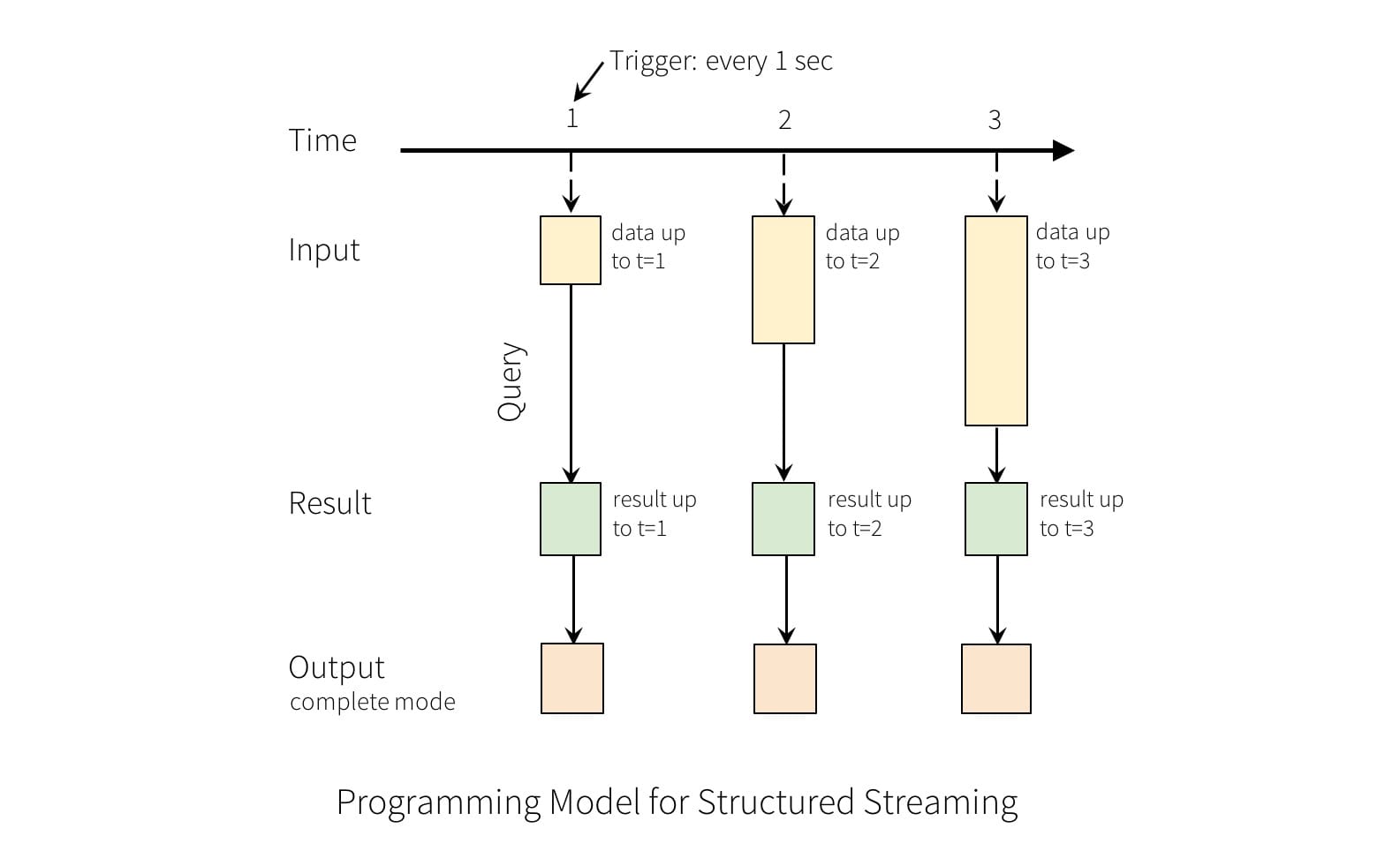
[Structured Streaming](https://spark.apache.org/docs/latest/structured- streaming-programming-guide.html) 是一种基于 Spark SQL 引擎的可扩展且容错的流处理引擎,它最关键的思想是将实时数据流视为一个不断增加的表,从而就可以像操作批的静态数据一样来操作流数据了。
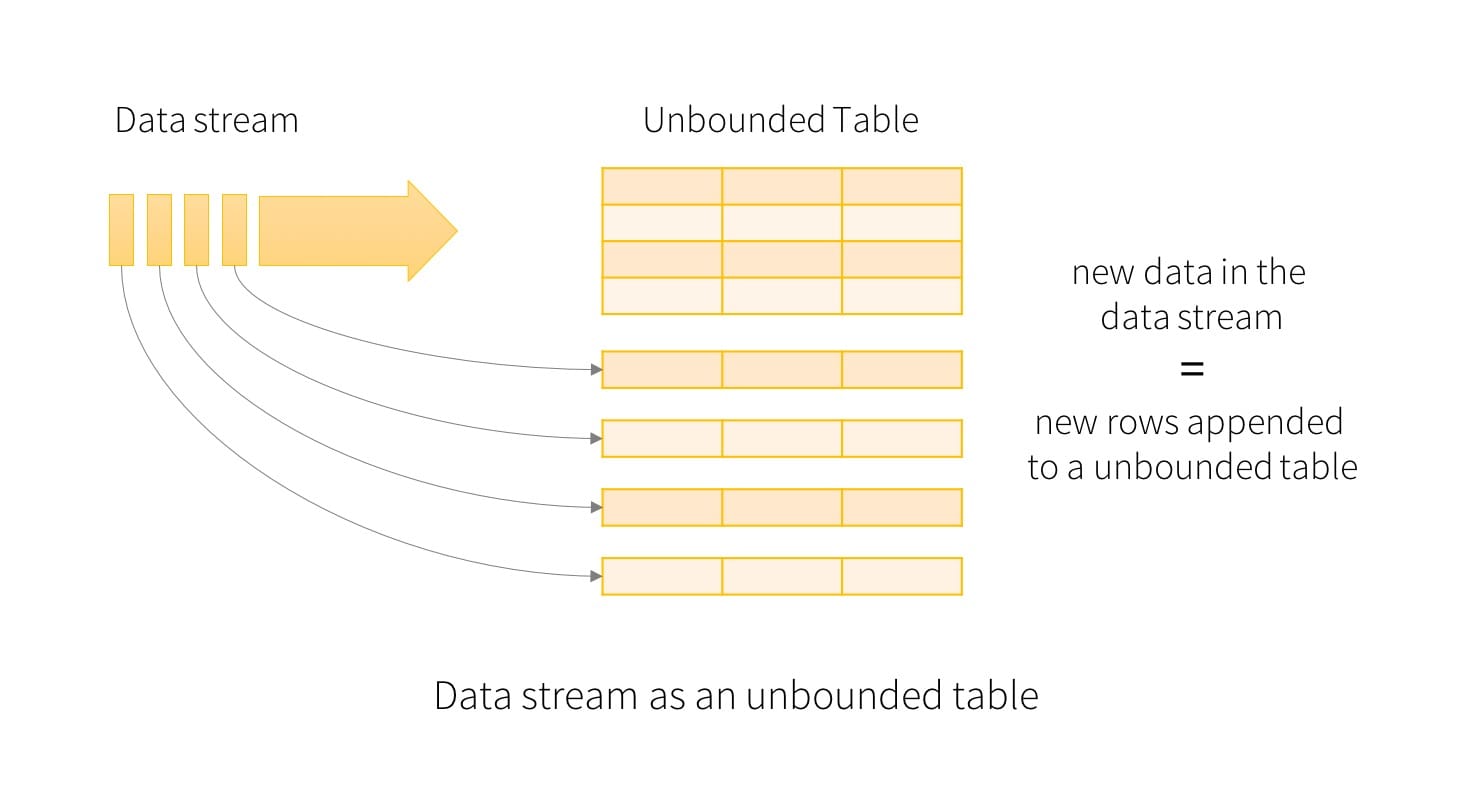 会对输入的查询生成“结果表”,每个触发间隔(例如,每 1
秒)新行将附加到输入表,最终更新结果表,每当结果表更新时,我们希望能够将更改后的结果写入外部接收器去。
会对输入的查询生成“结果表”,每个触发间隔(例如,每 1
秒)新行将附加到输入表,最终更新结果表,每当结果表更新时,我们希望能够将更改后的结果写入外部接收器去。
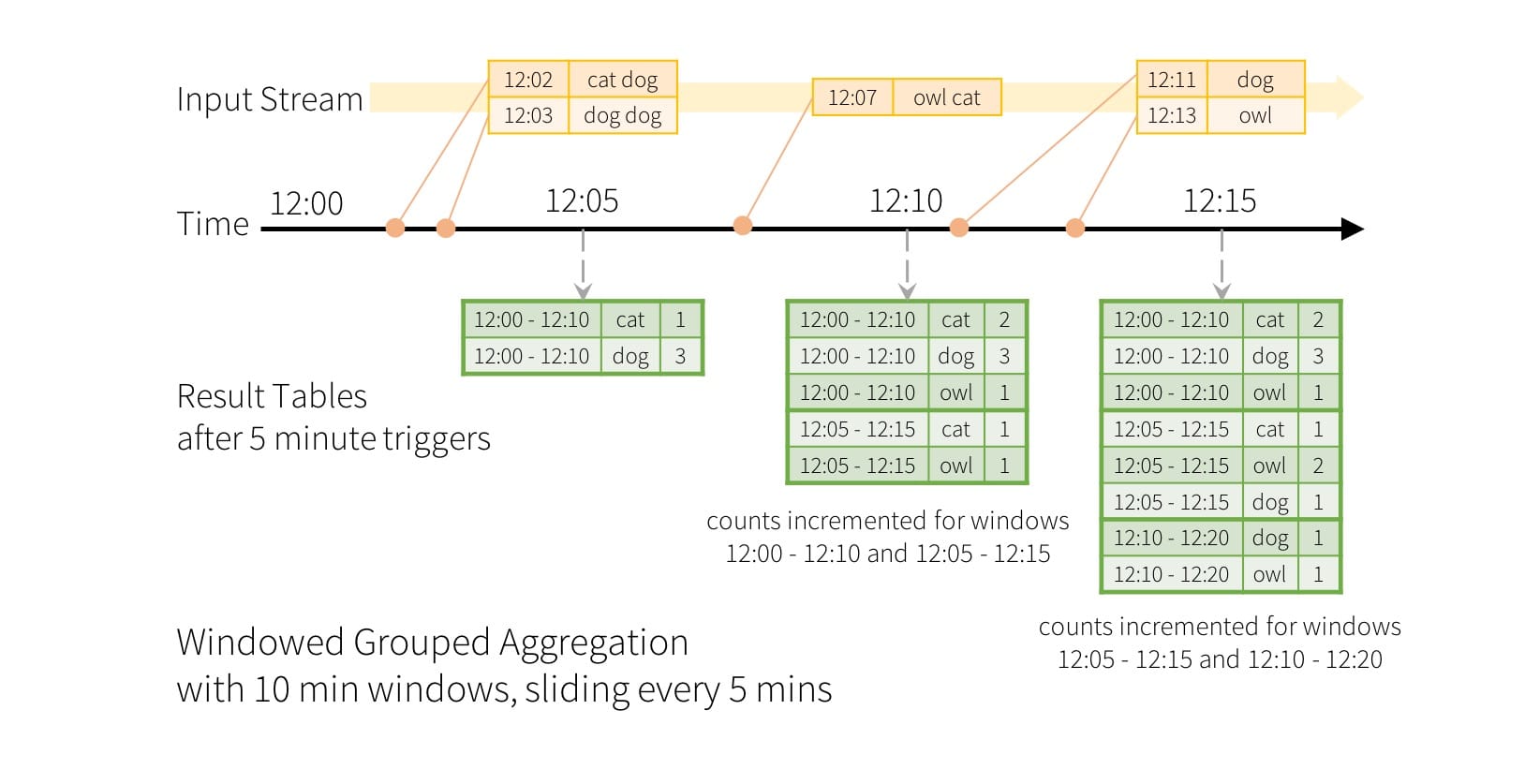
 终于支持事件时间的窗口操作:
终于支持事件时间的窗口操作:
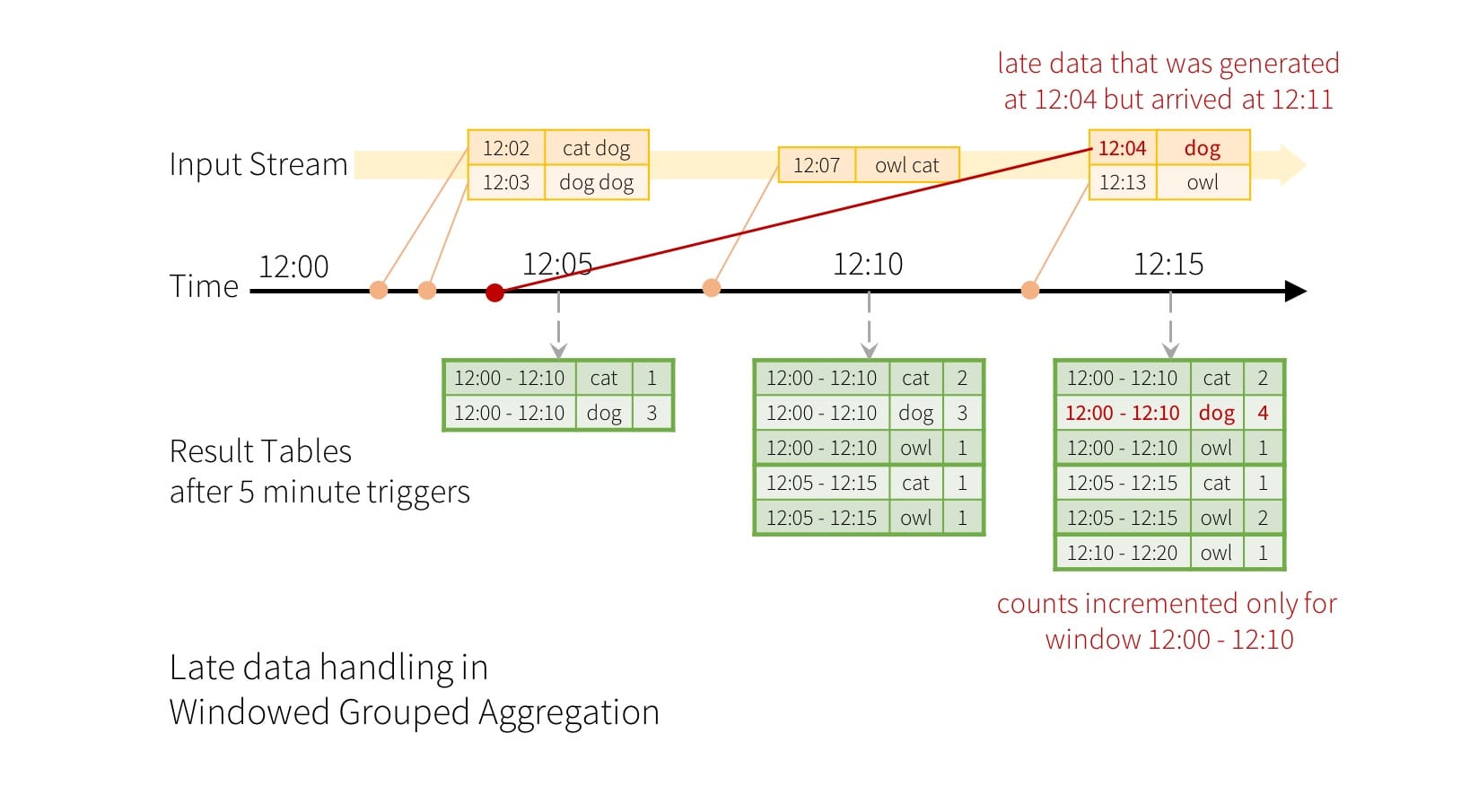
 通过结合水印来处理延迟数据:
通过结合水印来处理延迟数据:
 对比你会发现这个 Structured Streaming 怎么和 Flink这么像,哈哈哈哈,不过这确实是未来的正确之路,两者的功能也会越来越相像的,期待它们出现更加令人兴奋的功能。
对比你会发现这个 Structured Streaming 怎么和 Flink这么像,哈哈哈哈,不过这确实是未来的正确之路,两者的功能也会越来越相像的,期待它们出现更加令人兴奋的功能。
如果你对 Structured Streaming感兴趣的话,可以去[官网](https://spark.apache.org/docs/latest/structured-streaming- programming-guide.html)做更深一步的了解,顺带附上 StructuredStreaming (opens new window) 的 Paper,同时也附上一位阿里小哥的 PPT —— From Spark Streaming to StructuredStreaming (opens new window)。
# Flink VS Spark
 通过上面你应该可以了解到 Flink 对比 Spark Streaming 的微批处理来说是有一定的优势,并且 Flink还有一些特别的优点,比如灵活的时间语义、多种时间窗口、结合水印处理延迟数据等,但是 Spark 也有自己的一些优势,功能在早期来说是很完善的,并且新版本的Spark 还添加了 Structured Streaming,它和 Flink 的功能很相近,两个还是值得更深入的对比,期待后面官方的测试对比报告。
通过上面你应该可以了解到 Flink 对比 Spark Streaming 的微批处理来说是有一定的优势,并且 Flink还有一些特别的优点,比如灵活的时间语义、多种时间窗口、结合水印处理延迟数据等,但是 Spark 也有自己的一些优势,功能在早期来说是很完善的,并且新版本的Spark 还添加了 Structured Streaming,它和 Flink 的功能很相近,两个还是值得更深入的对比,期待后面官方的测试对比报告。
# Storm
Storm 是一个开源的分布式实时计算系统,可以简单、可靠的处理大量的数据流。Storm 支持水平扩展,具有高容错性,保证每个消息都会得到处理,Strom本身是无状态的,通过 ZooKeeper 管理分布式集群环境和集群状态。
# Storm 核心组件
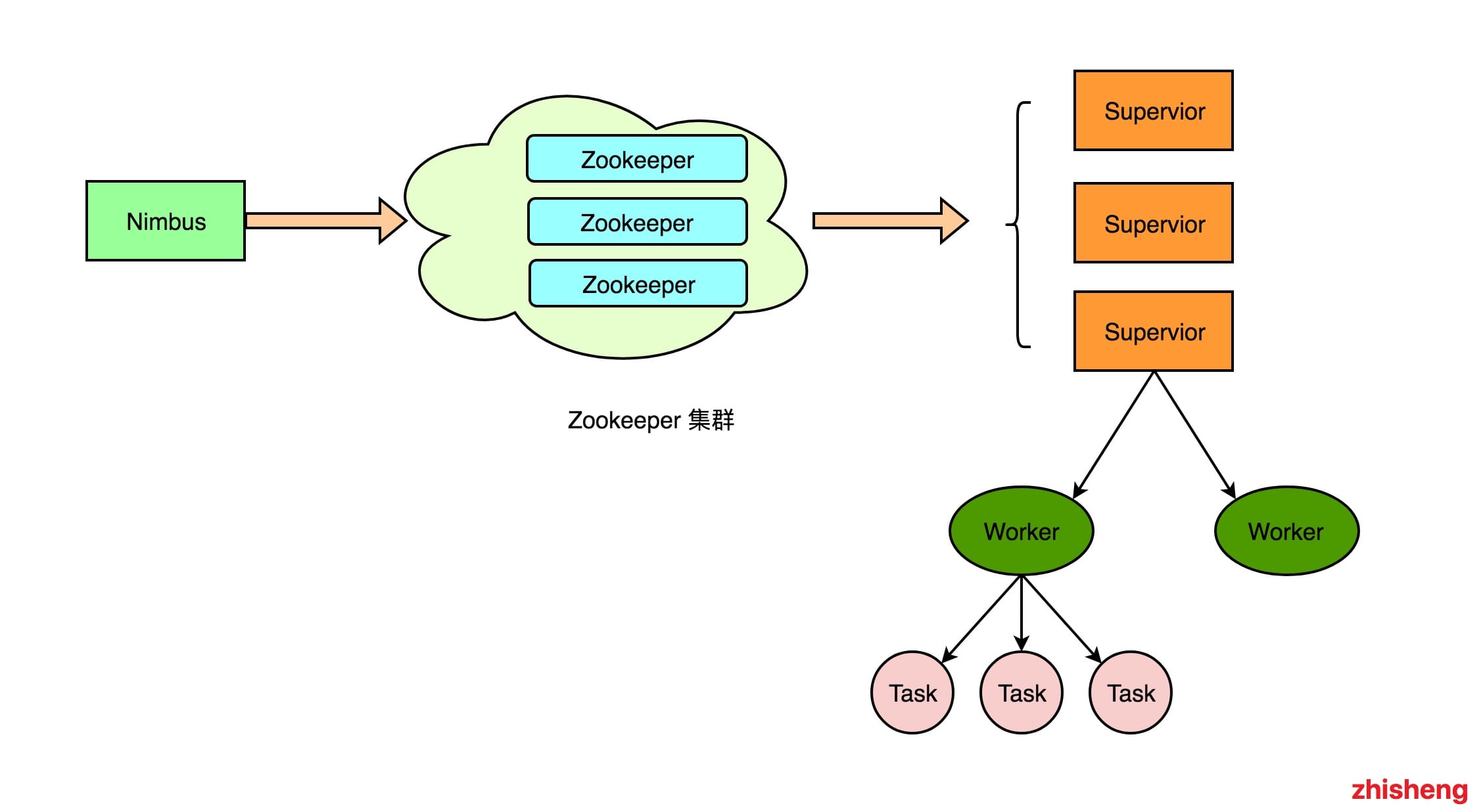 Nimbus:负责资源分配和任务调度,Nimbus 对任务的分配信息会存储在 Zookeeper 上面的目录下。
Nimbus:负责资源分配和任务调度,Nimbus 对任务的分配信息会存储在 Zookeeper 上面的目录下。
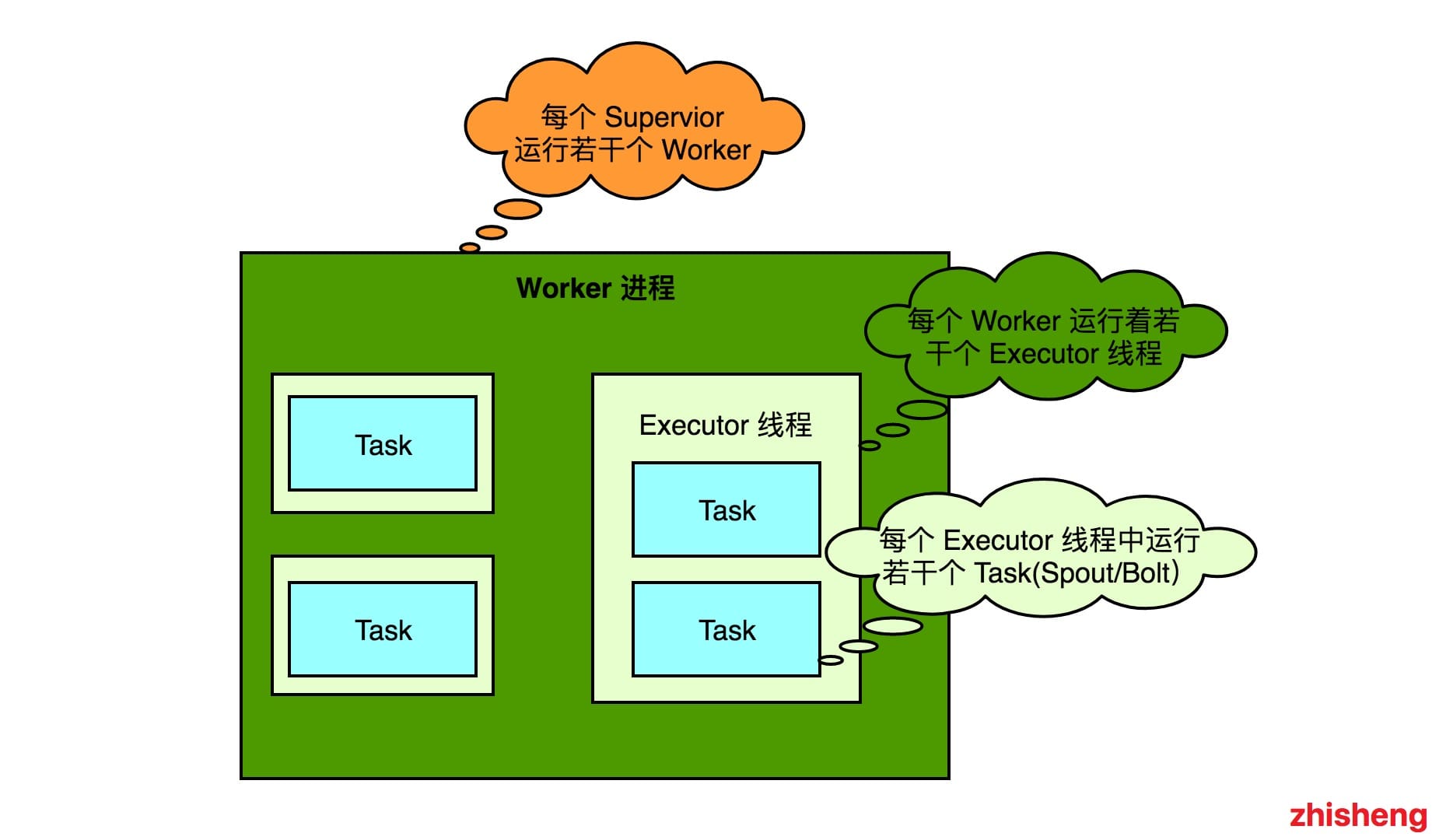
Supervisor:负责去 Zookeeper 上的指定目录接受 Nimbus 分配的任务,启动和停止属于自己管理的 Worker进程。它是当前物理机器上的管理者 —— 通过配置文件设置当前 Supervisor 上启动多少个 Worker。
Worker:运行具体处理组件逻辑的进程,Worker 运行的任务类型只有两种,一种是 Spout 任务,一种是 Bolt 任务。
Task:Worker 中每一个 Spout/Bolt 的线程称为一个 Task. 在 Storm0.8 之后,Task 不再与物理线程对应,不同Spout/Bolt 的 Task 可能会共享一个物理线程,该线程称为 Executor。
Worker、Task、Executor 三者之间的关系:
# Storm 核心概念
- Nimbus:Storm 集群主节点,负责资源分配和任务调度,任务的提交和停止都是在 Nimbus 上操作的,一个 Storm 集群只有一个 Nimbus 节点。
- Supervisor:Storm 集群工作节点,接受 Nimbus 分配任务,管理所有 Worker。
- Worker:工作进程,每个工作进程中都有多个 Task。
- Executor:产生于 Worker 进程内部的线程,会执行同一个组件的一个或者多个 Task。
- Task:任务,每个 Spout 和 Bolt 都是一个任务,每个任务都是一个线程。
- Topology:计算拓扑,包含了应用程序的逻辑。
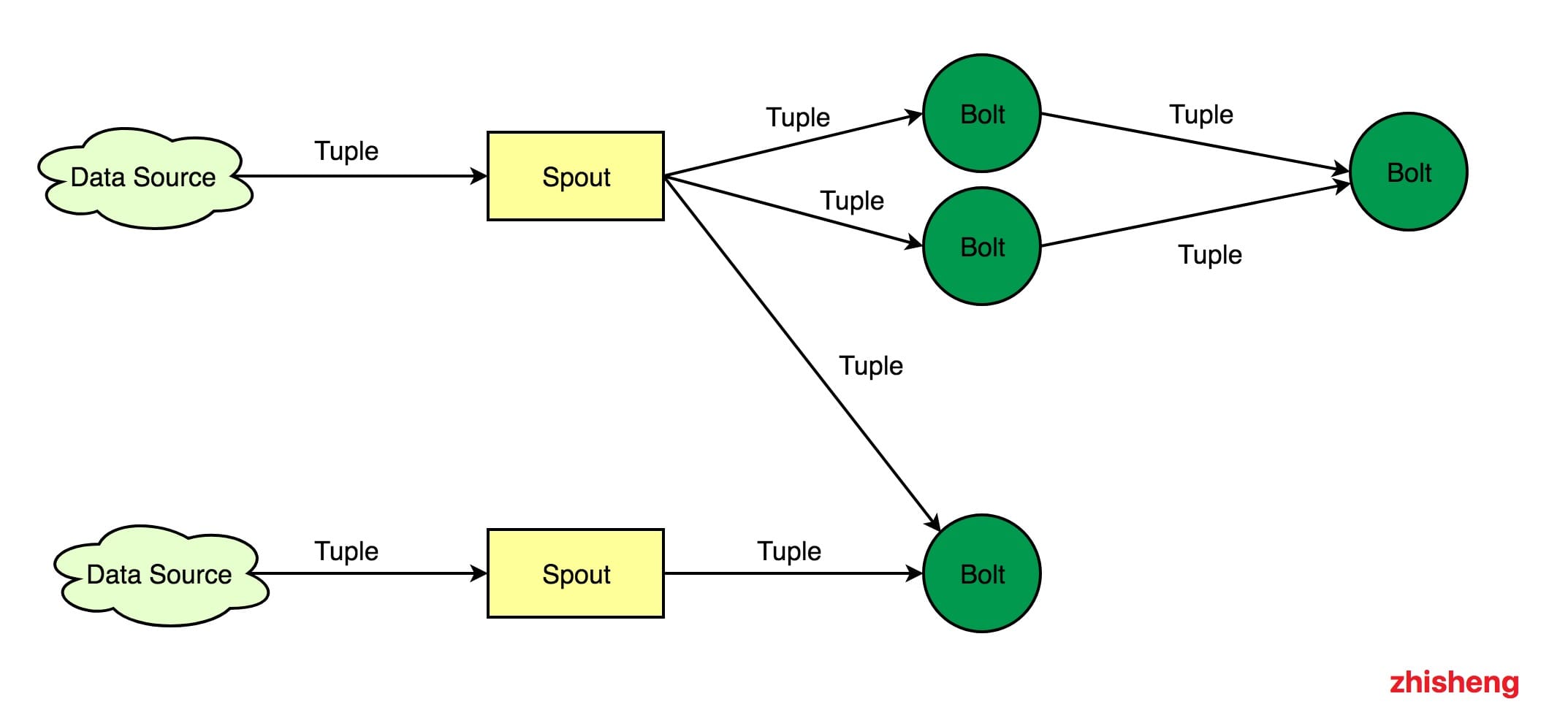
- Stream:消息流,关键抽象,是没有边界的 Tuple 序列。
- Spout:消息流的源头,Topology 的消息生产者。
- Bolt:消息处理单元,可以过滤、聚合、查询数据库。
- Tuple:数据单元,数据流中就是一个个 Tuple。
- Stream grouping:消息分发策略,一共 6 种,控制 Tuple 的路由,定义 Tuple 在 Topology 中如何流动。
- Reliability:可靠性,Storm 保证每个 Tuple 都会被处理。
# Storm 数据处理流程图
Storm 处理数据的特点:数据源源不断,不断处理,数据都是 Tuple。
# Flink VS Storm
可以参考的文章有:
[流计算框架 Flink 与 Storm 的性能对比](https://tech.meituan.com/2017/11/17/flink- benchmark.html)
360 深度实践:Flink 与 Storm协议级对比 (opens new window)
两篇文章都从不同场景、不同数据压力下对比 Flink 和 Storm 两个实时计算框架的性能表现,最终结果都表明 Flink 比 Storm的吞吐量和性能远超 Storm。
# 全部对比结果
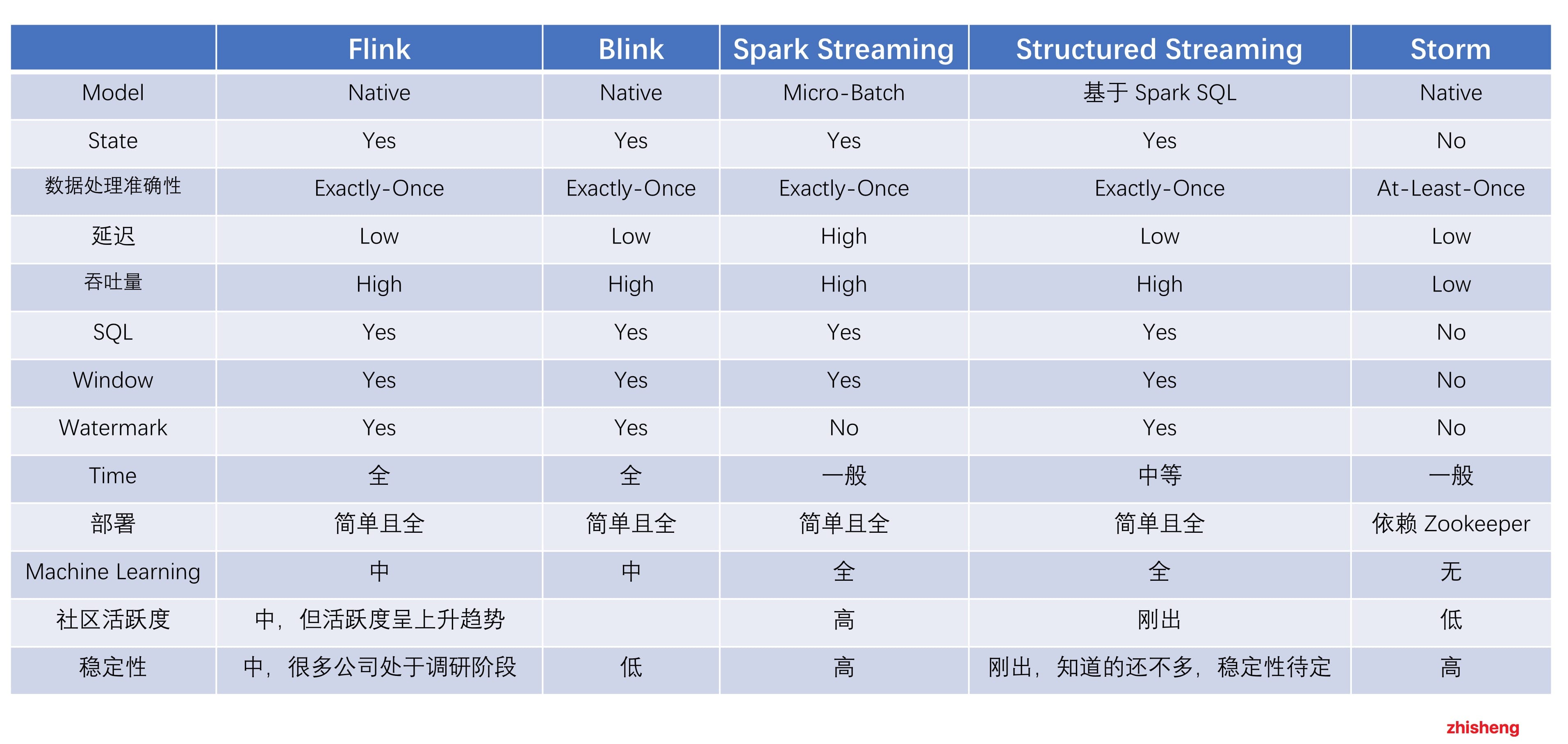 如果对延迟要求不高的情况下,可以使用 Spark Streaming,它拥有丰富的高级 API,使用简单,并且 Spark生态也比较成熟,吞吐量大,部署简单,社区活跃度较高,从 GitHub 的 star 数量也可以看得出来现在公司用 Spark还是居多的,并且在新版本还引入了 Structured Streaming,这也会让 Spark 的体系更加完善。
如果对延迟要求不高的情况下,可以使用 Spark Streaming,它拥有丰富的高级 API,使用简单,并且 Spark生态也比较成熟,吞吐量大,部署简单,社区活跃度较高,从 GitHub 的 star 数量也可以看得出来现在公司用 Spark还是居多的,并且在新版本还引入了 Structured Streaming,这也会让 Spark 的体系更加完善。
如果对延迟性要求非常高的话,可以使用当下最火的流处理框架 Flink,采用原生的流处理系统,保证了低延迟性,在 API和容错性方面做的也比较完善,使用和部署相对来说也是比较简单的,加上国内阿里贡献的 Blink,相信接下来 Flink的功能将会更加完善,发展也会更加好,社区问题的响应速度也是非常快的,另外还有专门的钉钉大群和中文列表供大家提问,每周还会有专家进行直播讲解和答疑。
# 小结与反思
因在 1.2 节中已经对 Flink 的特性做了很详细的讲解,所以本篇主要介绍其他几种计算框架(Blink、Spark、SparkStreaming、StructuredStreaming、Storm),并对比分析了这几种框架的特点与不同。你对这几种计算框架中的哪个最熟悉呢?了解过它们之间的差异吗?你有压测过它们的处理数据的性能吗?
# 分享交流
我们为本专栏付费读者创建了微信交流群,以方便更有针对性地讨论专栏相关的问题。入群方式请添加 GitChat小助手伽利略的微信号:GitChatty6(或扫描以下二维码),然后给小助手发「310」消息,即可拉你进群~
