# Flink扩展库——MachineLearning
# Flink-ML 介绍
ML 是 Machine Learning 的简称,Flink-ML 是 Flink 的机器学习类库。在 Flink 1.9 之前该类库是存在
flink-libraries 模块下的,但是在 Flink 1.9 版本中,为了支持
FLIP-39 (opens new window)
,所以该类库被移除了。
建立 FLIP-39 的目的主要是增强 Flink-ML 的可伸缩性和易用性。通常使用机器学习的有两类人,一类是机器学习算法库的开发者,他们需要一套标准的
API 来实现算法,每个机器学习算法会在这些 API
的基础上实现;另一类用户是直接利用这些现有的机器学习算法库去训练数据模型,整个训练是要通过很多转换或者算法才能完成的,所以如果能够提供 ML
Pipeline,那么对于后一类用户来说绝对是一种福音。虽然在 1.9 中移除了之前的 Flink-ML 模块,但是在 Flink 项目下出现了一个
flink-ml-parent 的模块,该模块有两个子模块 flink-ml-api 和 flink-ml-lib。
flink-ml-api 模块增加了 ML Pipeline 和 MLLib 的接口,它的类结构图如下:
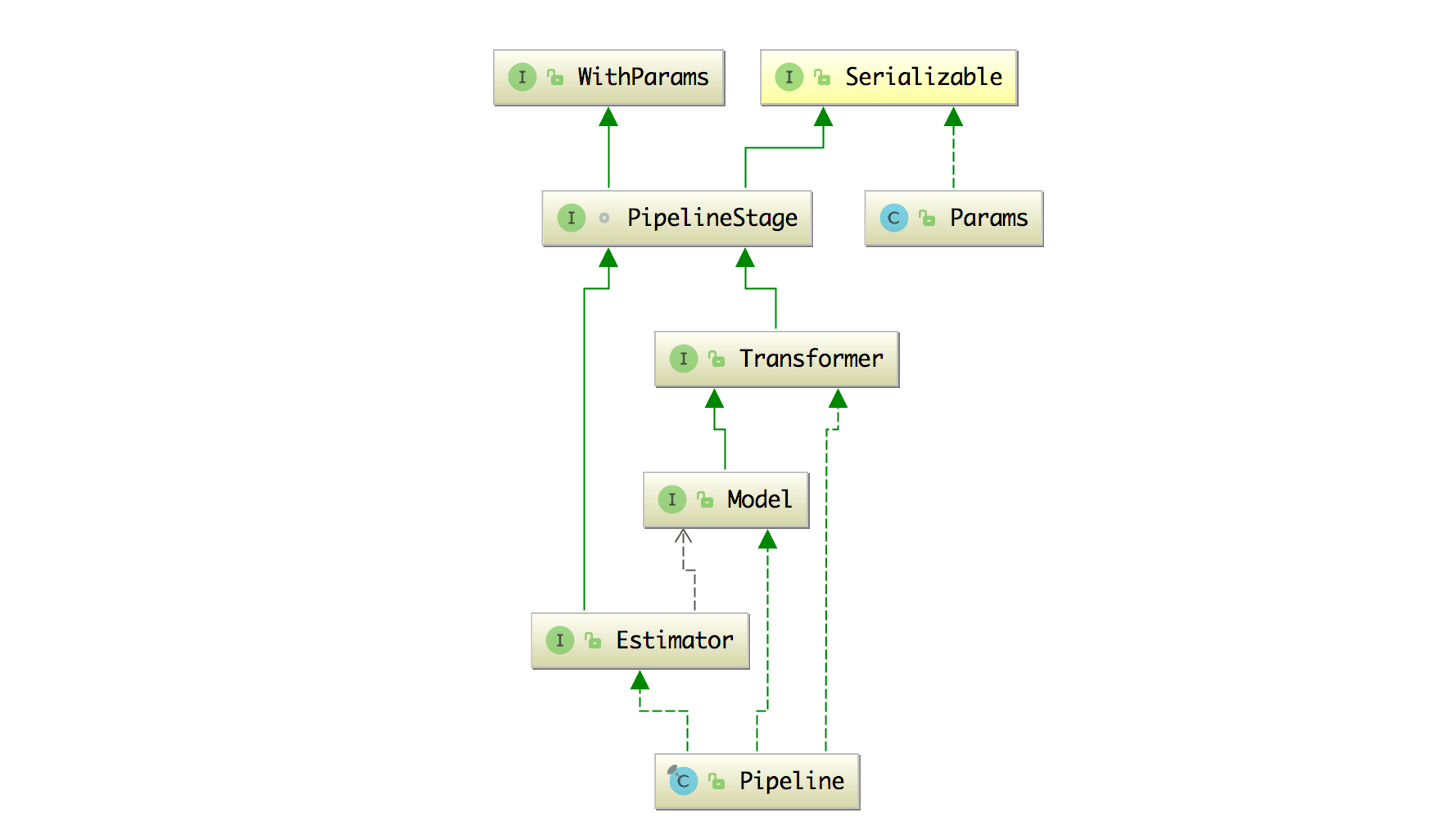
Transformer: Transformer 是一种可以将一个表转换成另一个表的算法
Model: Model 是一种特别的 Transformer,它继承自 Transformer。它通常是由 Estimator 生成,Model 用于推断,输入一个数据表会生成结果表。
Estimator: Estimator 是一个可以根据一个数据表生成一个模型的算法。
Pipeline: Pipeline 描述的是机器学习的工作流,它将很多 Transformer 和 Estimator 连接在一起成一个工作流。
PipelineStage: PipelineStage 是 Pipeline 的基础节点,Transformer 和 Estimator 两个都继承自 PipelineStage 接口。
Params: Params 是一个参数容器。
WithParams: WithParams 有一个保存参数的 Params 容器。通常会使用在 PipelineStage 里面,因为几乎所有的算法都需要参数。
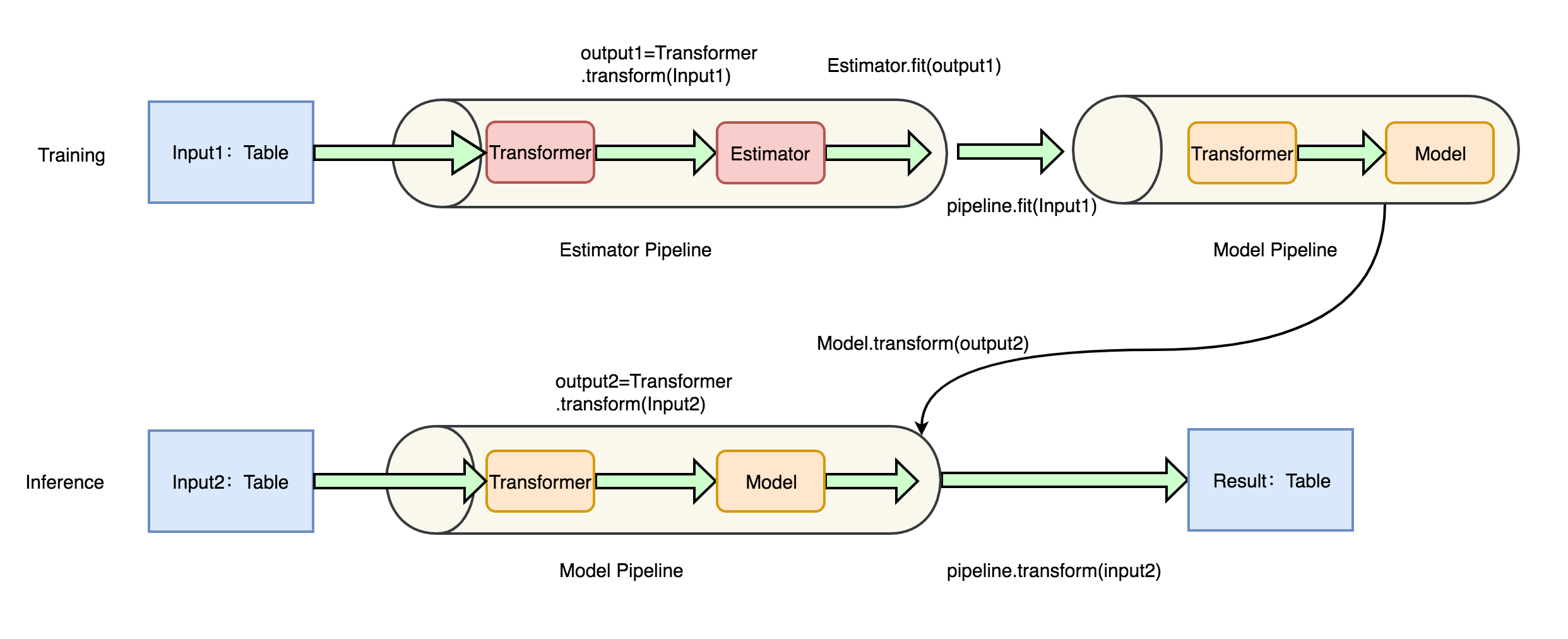
Flink-ML 的 pipeline 流程如下:
flink-ml-lib 模块包括了 DenseMatrix、DenseVector、SparseVector 等类的基本操作。这两个模块是
Flink-ML 的基础模块,相信社区在后面的稳定版本一定会带来更加完善的 Flink-ML 库。
# 如何使用 Flink-ML?
虽然在 Flink 1.9 中已经移除了 Flink-ML 模块,但是在之前的版本还是支持的,如果你们公司使用的是低于 1.9 的版本,那么还是可以使用的,在使用之前引入依赖(假设使用的是 Flink 1.8 版本):
另外如果是要运行的话还是要将 opt 目录下的 flink-ml_2.11-1.8.0.jar 移到 lib 目录下。下面演示下如何训练多元线性回归模型:
//带标签的特征向量
val trainingData: DataSet[LabeledVector] = ...
val testingData: DataSet[Vector] = ...
val dataSet: DataSet[LabeledVector] = ...
//使用 Splitter 将数据集拆分成训练数据和测试数据
val trainTestData: DataSet[TrainTestDataSet] = Splitter.trainTestSplit(dataSet)
val trainingData: DataSet[LabeledVector] = trainTestData.training
val testingData: DataSet[Vector] = trainTestData.testing.map(lv => lv.vector)
val mlr = MultipleLinearRegression()
.setStepsize(1.0)
.setIterations(100)
.setConvergenceThreshold(0.001)
mlr.fit(trainingData)
//已经形成的模型可以用来预测数据了
val predictions: DataSet[LabeledVector] = mlr.predict(testingData)
# Flink-ML Pipeline 使用
之前前面也讲解了 Pipeline 在 Flink-ML 的含义,那么下面演示一下如何通过 Flink-ML 构建一个 Pipeline 作业:
val trainingData: DataSet[LabeledVector] = ...
val testingData: DataSet[Vector] = ...
val scaler = StandardScaler()
val polyFeatures = PolynomialFeatures().setDegree(3)
val mlr = MultipleLinearRegression()
// Construct pipeline of standard scaler, polynomial features and multiple linear regression
//构建标准定标器、多项式特征和多元线性回归的流水线
val pipeline = scaler.chainTransformer(polyFeatures).chainPredictor(mlr)
// Train pipeline
pipeline.fit(trainingData)
// Calculate predictions
val predictions: DataSet[LabeledVector] = pipeline.predict(testingData)
# 小结与反思
本节主要讲了下 Flink-ML 的发展以及为啥在 Flink 1.9 移除该库,并且介绍了其内部的接口和库函数,另外通过两个简短的代码讲解了下如何使用 Flink-ML。如果想了解更多 Flink-ML 的知识可以查看官网。
[Flink-ML](https://ci.apache.org/projects/flink/flink-docs- release-1.8/dev/libs/ml/)