# 基于Flink的海量日志实时处理系统的实践
# 海量日志实时处理需求分析
在 11.5 节中讲解了 Flink 如何实时处理异常的日志,在那节中对比分析了几种常用的日志采集工具。我们也知道通常在排查线上异常故障的时候,查询日志总是必不可缺的一部分,但是现在微服务架构下日志都被分散到不同的机器上,日志查询就会比较困难,所以统一的日志收集几乎也是每家公司必不可少的。据笔者调研,不少公司现在是有日志统一的收集,也会去做日志的实时 ETL,利用一些主流的技术比如 ELK 去做日志的展示、搜索和分析,但是却缺少了日志的实时告警。在本节中,笔者将为大家做一个全方位的日志链路讲解,包含了日志的实时采集、日志的 ETL、日志的实时监控告警、日志的存储、日志的可视化图表展示与搜索分析等。
# 海量日志实时处理架构设计
分析完我们这个案例的需求后,接下来对整个项目的架构做一个合理的设计。
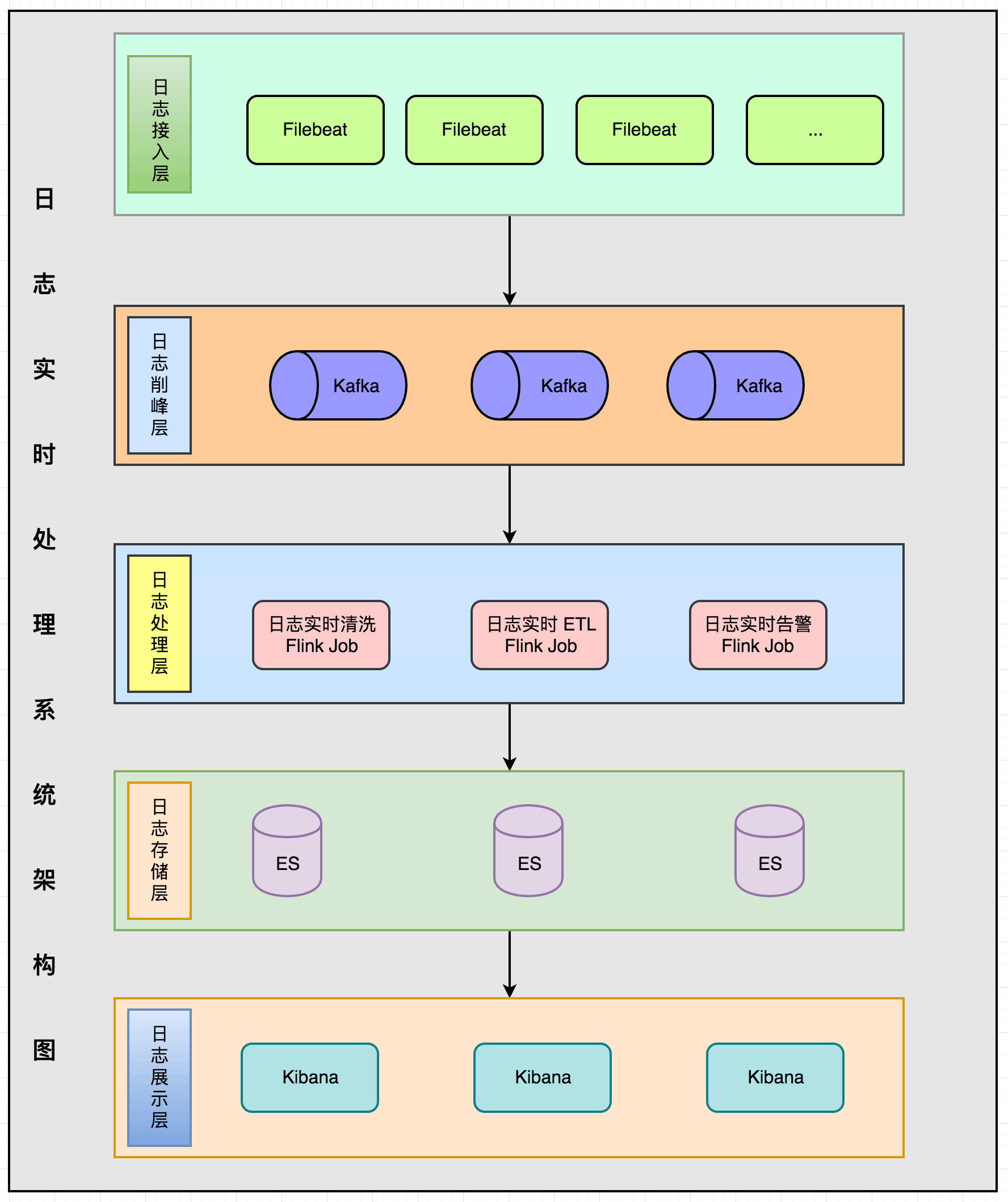 整个架构分为五层:日志接入层、日志削峰层、日志处理层、日志存储层、日志展示层。
整个架构分为五层:日志接入层、日志削峰层、日志处理层、日志存储层、日志展示层。
- 日志接入层:日志采集的话使用的是 Filebeat 组件,需要在每台机器上部署一个 Filebeat。
- 日志削峰层:防止日志流量高峰,使用 Kafka 消息队列做削峰。
- 日志处理层:Flink 作业同时消费 Kafka 数据做日志清洗、ETL、实时告警。
- 日志存储层:使用 ElasticSearch 做日志的存储。
- 日志展示层:使用 Kibana 做日志的展示与搜索查询界面。
# 日志实时采集
在 11.5.1 中对比了这几种比较流行的日志采集工具(Logstash、Filebeat、Fluentd、Logagent),从功能完整性、性能、成本、使用难度等方面综合考虑后,这里演示使用的是 Filebeat。
# 安装 Filebeat
在服务器上下载 Fliebeat 6.3.2 (opens new window) 安装包(请根据自己服务器和所需要的版本进行下载),下载后进行解压。
tar xzf filebeat-6.3.2-linux-x86_64.tar.gz
# 配置 Filebeat
配置 Filebeat 需要编辑 Filebeat 的配置文件(filebeat.yml),不同安装方式配置文件的存放路径有一些不同,对于解压包安装的方式,配置文件存在解压目录下面;对于 rpm 和 deb 的方式, 配置文件路径的是 /etc/filebeat/filebeat.yml 下。
因为 Filebeat 是要实时采集日志的,所以得让 Filebeat 知道日志的路径是在哪里,下面在配置文件中定义一下日志文件的路径。通常建议在服务器上固定存放日志的路径,然后应用的日志都打在这个固定的路径中,这样 Filebeat 的日志路径配置只需要填写一次,其他机器上可以拷贝同样的配置就能将 Filebeat 运行起来,配置如下。
- type: log
# 配置为 true 表示开启
enabled: true
# 日志的路径
paths:
- /var/logs/*.log
上面的配置表示将对 /var/logs 目录下所有以 .log 结尾的文件进行采集,接下来配置日志输出的方式,这里使用的是 Kafka,配置如下。
output.kafka:
# 填写 Kafka 地址信息
hosts: ["localhost:9092"]
# 数据发到哪个 topic
topic: zhisheng-log
partition.round_robin:
reachable_only: false
required_acks: 1
上面讲解的两个配置,笔者这里将它们写在一个新建的配置文件中 kafka.yml,然后启动 Filebeat 的时候使用该配置。
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/logs/*.log
output.kafka:
hosts: ["localhost:9092"]
topic: zhisheng_log
partition.round_robin:
reachable_only: false
required_acks: 1
# 启动 Filebeat
日志路径的配置和 Kafka 的配置都写好后,则接下来通过下面命令将 Filebeat 启动:
bin/filebeat -e -c kafka.yml
执行完命令后出现的日志如下则表示启动成功了,另外还可以看得到会在终端打印出 metrics 数据出来。
# 验证 Filebeat 是否将日志数据发到 Kafka
那么此时就得去查看是否真正就将这些日志数据发到 Kafka 了呢,你可以通过 Kafka 的自带命令去消费这个 Topic 看是否不断有数据发出来,命令如下:
bin/kafka-console-consumer.sh --zookeeper 106.54.248.27:2181 --topic zhisheng_log --from-beginning
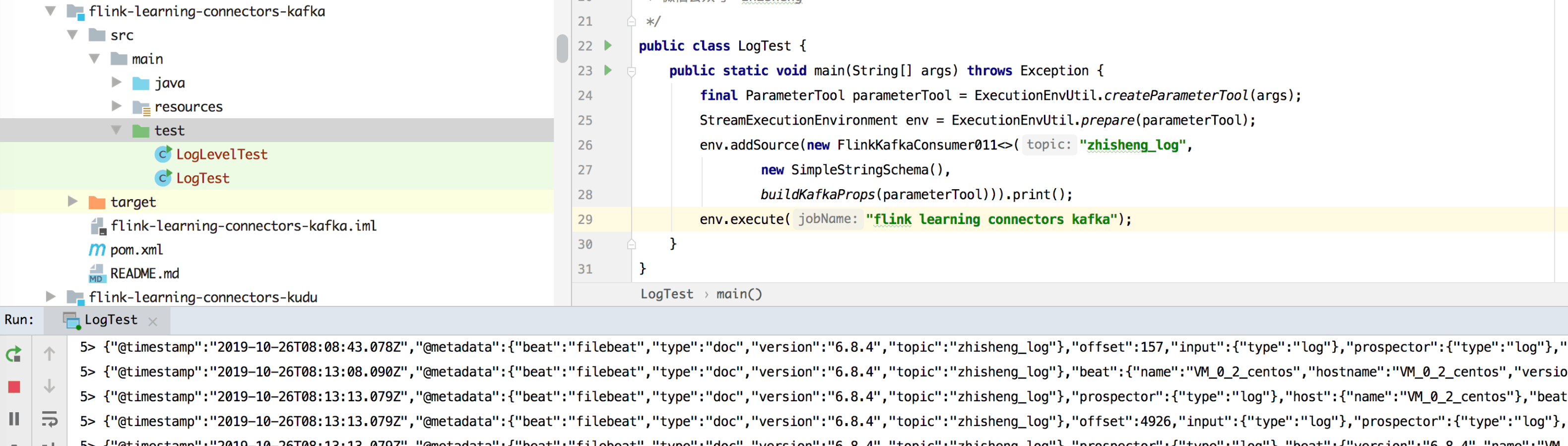
如果出现数据则代表是已经有数据发到 Kafka 了,如果你不喜欢使用这种方式验证,可以自己写个 Flink Job 去读取 Kafka 该 Topic 的数据,比如写了个作业运行结果如下就代表着日志数据已经成功发送到 Kafka。
# 发到 Kafka 的日志结构
既然数据都已经发到 Kafka 了,通过消费 Kafka 该 Topic 的数据我们可以发现这些数据的格式否是 JSON,结构如下:
{
"@timestamp": "2019-10-26T08:18:18.087Z",
"@metadata": {
"beat": "filebeat",
"type": "doc",
"version": "6.8.4",
"topic": "zhisheng_log"
},
"prospector": {
"type": "log"
},
"input": {
"type": "log"
},
"beat": {
"name": "VM_0_2_centos",
"hostname": "VM_0_2_centos",
"version": "6.8.4"
},
"host": {
"name": "VM_0_2_centos"
},
"source": "/var/logs/middleware/kafka.log",
"offset": 9460,
"log": {
"file": {
"path": "/var/logs/middleware/kafka.log"
}
},
"message": "2019-10-26 16:18:11 TRACE [Controller id=0] Leader imbalance ratio for broker 0 is 0.0 (kafka.controller.KafkaController)"
}
这个日志结构里面包含了很多字段,比如 timestamp、metadata、host、source、message 等,但是其中某些字段我们其实根本不需要的,你可以根据公司的需求丢弃一些字段,把要丢弃的字段也配置在 kafka.yml 中,如下所示。
processors:
- drop_fields:
fields: ["prospector","input","beat","log","offset","@metadata"]
然后再次启动 Filebeat ,发现上面配置的字段在新的数据中没有了(除 @metadata 之外),另外经笔者验证:不仅 @metadata
字段不能丢弃,如果 @timestamp 这个字段在 drop_fields
中配置了,也是不起作用的,它们两不允许丢弃。通常来说一行日志已经够长了,再加上这么多我们不需要的字段,就会增加数据的大小,对于生产环境的话,日志数据量非常大,那无疑会对后面所有的链路都会造成一定的影响,所以一定要在底层数据源头做好精简。另外还可以在发送
Kafka 的时候对数据进行压缩,可以在配置文件中配置一个 compression: gzip。精简后的日志数据结构如下:
{
"@timestamp": "2019-10-26T09:23:16.848Z",
"@metadata": {
"beat": "filebeat",
"type": "doc",
"version": "6.8.4",
"topic": "zhisheng_log"
},
"host": {
"name": "VM_0_2_centos"
},
"source": "/var/logs/middleware/kafka.log",
"message": "2019-10-26 17:23:11 TRACE [Controller id=0] Leader imbalance ratio for broker 0 is 0.0 (kafka.controller.KafkaController)"
}
# 日志格式统一
因为 Filebeat 是在机器上采集的日志,这些日志的种类比较多,常见的有应用程序的运行日志、作业构建编译打包的日志、中间件服务运行的日志等。通常在公司是可以给开发约定日志打印的规则,但是像中间件这类服务的日志是不固定的,如果将 Kafka 中的消息直接存储到 ElasticSearch 的话,后面如果要做区分筛选的话可能会有问题。为了避免这个问题,我们得在日志存入 ElasticSearch 之前做一个数据格式化和清洗的工作,因为 Flink 处理数据的速度比较好,而且可以做到实时,所以选择在 Flink Job 中完成该工作。
在该作业中的要将 message 解析,一般该行日志信息会包含很多信息,比如日志打印时间、日志级别、应用名、唯一性 ID(用来关联各个请求)、请求上下文。那么我们就需要一个新的日志结构对象来统一日志的格式,定义如下:
public class LogEvent {
//日志的类型
private String type;
//日志的时间戳
private Long timestamp;
//日志的级别
private String level;
//日志的内容
private String message;
//日志的一些标签,需要解析原数据中的 message 字段获取。例如日志所在的机器、日志文件名、应用名、应用 id 等
private Map<String, String> tags = new HashMap<>();
}
# 日志实时清洗
日志数据已经可以通过 Filebeat 实时发送到 Kafka 了,在 Flink
中也可以消费到日志数据,接下来要做的就是将日志数据做实时的清洗,将其原始结构转换成 LogEvent,那么其主要的工作在于解析原始数据中的 message
字段,将时间、日志级别、应用信息等存放在 tags 里面。比如下面这条日志,它的格式就是 date(时间) log-level(日志级别) log- message(日志内容)。
2019-10-26 19:53:05 INFO [GroupMetadataManager brokerId=0] Removed 0 expired offsets in 0 milliseconds. (kafka.coordinator.group.GroupMetadataManager)
通常使用正则表达式解析日志比较多,这里我们使用 grok(基于正则表达式)来解析这种日志内容,像上面这条日志的正则表达式结构如下:
%{TIMESTAMP_ISO8601:timestamp} %{LOGLEVEL:level} %{JAVALOGMESSAGE:logmessage}
要在 Java 项目中使用 grok,需要先引入依赖,关于使用哪种依赖可以先去 GitHub 查阅一下,这里我们使用的是 java-grok。
<dependency>
<groupId>io.krakens</groupId>
<artifactId>java-grok</artifactId>
<version>0.1.9</version>
</dependency>
在测试之前需要先在配置文件中加入相关的正则表达式 pattern 文件,这个文件可以在 GitHub 下载,如果不满足我们现在日志的格式,那么得需要自己再额外在文件中定义一个我们日志的正则表达式,笔者这里定义的如下:
# 2019-10-26 19:53:05 INFO [GroupMetadataManager brokerId=0] Removed 0 expired offsets in 0 milliseconds. (kafka.coordinator.group.GroupMetadataManager)
KAFKALOG %{TIMESTAMP_ISO8601:timestamp} %{LOGLEVEL:level} %{JAVALOGMESSAGE:logmessage}
通常在一家公司的日志格式虽然可以尽量的统一,但难免还是会有开发不会按照规定来打印日志,所以这种情况得根据实际场景去匹配不同的正则表达式,然后来解析这些日志。本节因测试,我们就暂定日志格式如上面这种,接下来笔者写了个
GrokUtil 工具类,它提供了一个 toMap 方法将日志 message 根据定义的 pattern 来解析数据成一个 Map<String, Object> 对象,这样后面就可以直接利用该方法解析日志的 message。
public static final GrokCompiler compiler = GrokCompiler.newInstance();
public static Grok grok = null;
public static Map<String, Object> toMap(String pattern, String message) {
compiler.registerPatternFromClasspath("/patterns/patterns");//配置文件的正则表达式
grok = compiler.compile(pattern);
if (grok != null) {
Match match = grok.match(message);
return match.capture();
} else {
return new HashMap<>();
}
}
前面提供的那条日志通过上面的方法解析后的 Map<String, Object> 对象如下。
{YEAR=2019, MONTHNUM=10, HOUR=[19, null], level=INFO, logmessage=[GroupMetadataManager brokerId=0] Removed 0 expired offsets in 0 milliseconds. (kafka.coordinator.group.GroupMetadataManager), MINUTE=[53, null], SECOND=05.929, ISO8601_TIMEZONE=null, KAFKALOG=2019-10-26 19:53:05.929 INFO [GroupMetadataManager brokerId=0] Removed 0 expired offsets in 0 milliseconds. (kafka.coordinator.group.GroupMetadataManager), MONTHDAY=26, timestamp=2019-10-26 19:53:05}
可以发现 level、timestamp 等信息我们可以获取到了,接下来就是将原始的日志结构类型转换成 LogEvent 的格式,代码如下:
public class OriLog2LogEventFlatMapFunction extends RichFlatMapFunction<OriginalLogEvent, LogEvent> {
@Override
public void flatMap(OriginalLogEvent originalLogEvent, Collector<LogEvent> collector) throws Exception {
if (originalLogEvent == null) {
return;
}
LogEvent logEvent = new LogEvent();
String source = originalLogEvent.getSource();
if (source.contains("middleware")) {
logEvent.setType("MIDDLEWARE");
} else if (source.contains("app")){
logEvent.setType("APP");
} else if (source.contains("docker")) {
logEvent.setType("DOCKER");
} else {
logEvent.setType("MACHINE");
}
logEvent.setMessage(originalLogEvent.getMessage());
Map<String, Object> messageMap = GrokUtil.toMap("%{KAFKALOG}", originalLogEvent.getMessage());
logEvent.setTimestamp(DateUtil.format(messageMap.get("timestamp").toString(), YYYY_MM_DD_HH_MM_SS));
logEvent.setLevel(messageMap.get("level").toString());
Map<String, String> tags = new HashMap<>();
tags.put("host_name", originalLogEvent.getHost().get("name"));
tags.put("kafka_tpoic", originalLogEvent.getMetadata().get("topic"));
tags.put("source", originalLogEvent.getSource());
//可以添加更多 message 解析出来的字段放在该 tags 里面
logEvent.setTags(tags);
collector.collect(logEvent);
}
}
到上面这步的话,差不多就把数据获取和数据的清洗已经完成了,接下来的工作就是要完成日志的实时告警和日志的实时存储了,所以笔者的项目代码搭建如下:
public class LogMain {
public static void main(String[] args) throws Exception {
final ParameterTool parameterTool = ExecutionEnvUtil.createParameterTool(args);
StreamExecutionEnvironment env = ExecutionEnvUtil.prepare(parameterTool);
SingleOutputStreamOperator<LogEvent> logDataStream = env.addSource(new FlinkKafkaConsumer011<>("zhisheng_log",
new OriginalLogEventSchema(),
buildKafkaProps(parameterTool)))
.flatMap(new OriLog2LogEventFlatMapFunction());
//alert
LogAlert.alert(logDataStream);
//sink to es
LogSink2ES.sink2es(logDataStream);
env.execute("flink learning monitor log");
}
}
# 日志实时告警
通常公司的业务会很多,所以应用也会很多,那么在应用这么多的情况下,其实开发是没有很多一直去盯着应用的运行状态,但是应用的运行状态又关系到业务的稳定,所以当应用有问题的时候其实很希望能够立马收到通知,这样就可以及时去处理问题,以免造成更大的影响,这时,告警通知就起作用了。
在 11.5 节中讲过异常日志的告警,并且会在 12.2 节中再次详细讲解告警,所以在本节不再做过多介绍,下面介绍日志的实时存储。
# 日志实时存储
因为日志最终是要在界面上展示的,在页面上不仅要查看实时的日志,可能也想去查看历史的应用日志,所以得有个地方去将这些历史的日志存储下来,然后页面上通过接口去查询日志。至于为什么本节要将日志数据存储在 ElasticSearch 呢?其实建议读者也多从不同的层次去考虑原因,比如:
- 查询的复杂度:对于日志的展示、搜索、分析这些场景查询日志的条件有多复杂?不同的存储是否都能够满足这些查询条件?
- 数据量:得看每天日志数据量,如果每天的数据量很大,存储是否能够支撑这么大数据量的实时写入?历史数据变多后搜索查询的性能会不会骤降?
- 运维成本:团队是否有人熟悉该存储中间件?后期扩容维护等工作的复杂性如何?
- 社区活跃度:该存储中间件社区是否活跃?是否有足够的资料去学习?
ElasticSearch 是一款非常强大的开源搜索及分析引擎,除了搜索,它还可以结合 Kibana、Logstash 和 Beats 等组件一起应用在大数据近实时分析领域。在国内,阿里巴巴、腾讯、百度、滴滴、字节跳动等诸多知名公司都在使用 Elasticsearch。
在 3.9 节中讲过 Flink 的 Connector —— ElasticSearch,并且也通过一个样例讲解了如何将 Metrics 数据写入进 ElasticSearch,那么其实和现在将日志数据写入进 ElasticSearch 是一致的,两种情况的数据量都是很大,区别就是两个的结构不一样,可能需要对 Metrics 数据和日志数据索引设置不同的 template。所以这里就简单的提供下代码。
public class LogSink2ES {
public static void sink2es(SingleOutputStreamOperator<LogEvent> logDataStream, ParameterTool parameterTool) {
List<HttpHost> esAddresses = ESSinkUtil.getEsAddresses(parameterTool.get(ELASTICSEARCH_HOSTS));
int bulkSize = parameterTool.getInt(ELASTICSEARCH_BULK_FLUSH_MAX_ACTIONS, 40);
int sinkParallelism = parameterTool.getInt(STREAM_SINK_PARALLELISM, 5);
ESSinkUtil.addSink(esAddresses, bulkSize, sinkParallelism, logDataStream,
(LogEvent logEvent, RuntimeContext runtimeContext, RequestIndexer requestIndexer) -> {
requestIndexer.add(Requests.indexRequest()
.index("zhisheng_log")
.type(ZHISHENG)
.source(GsonUtil.toJSONBytes(logEvent), XContentType.JSON));
},
parameterTool);
}
}
# 日志实时展示
数据已经存储到 ElasticSearch 了,接下来就是日志的展示和分析了,因为 ElasticSearch 和 Kibana 搭配在一起就能够将日志的展示、分析、搜索功能完成,并且这套技术在很多公司也是比较流行的了,所以这里也是选型 Kibana,当然如果你们公司有人力,可以自己提供数据展示的接口和页面。
要完成该日志的展示需要先安装好
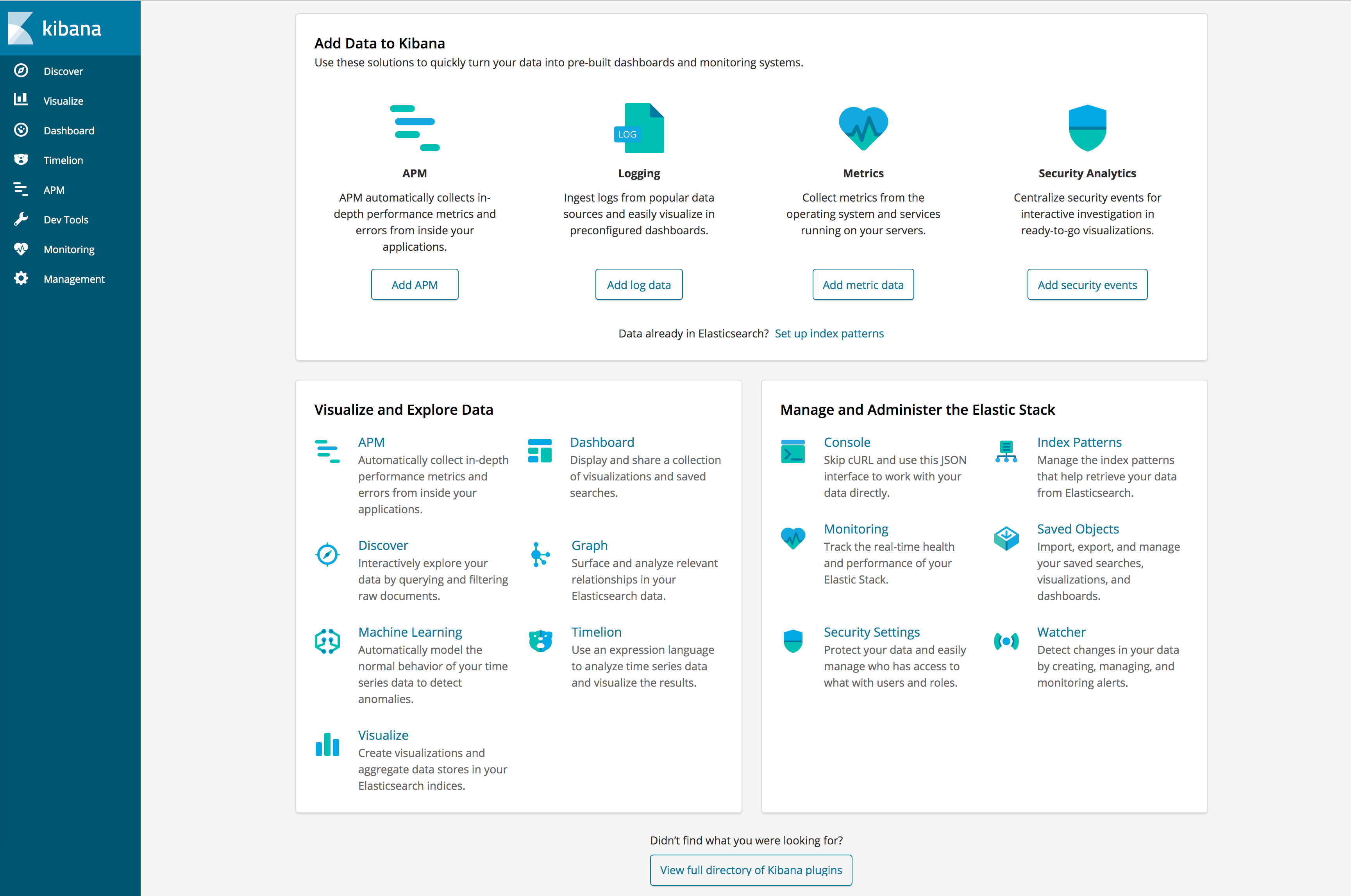
Kibana,关于如何下载和安装本节不做过多介绍,读者可以自行去官网下载安装包并安装。因为所有的日志数据都已经提供了,那么使用 Kibana
做数据展示其实就是要稍加配置一下 Kibana 就行了。下图是启动好 Kibana 之后,打开 http://localhost:5601 页面的效果。
 因为在日志写入进 ElasticSearch 的作业中配置的日志索引是
因为在日志写入进 ElasticSearch 的作业中配置的日志索引是 zhisheng_log,所以得在 Kibana 左侧的 Management
页面去配置一个日志索引,这里我们使用的是 *log 的模版,发现只找到一个 zhisheng_log 的索引,接下来就一直点下一步就好了。
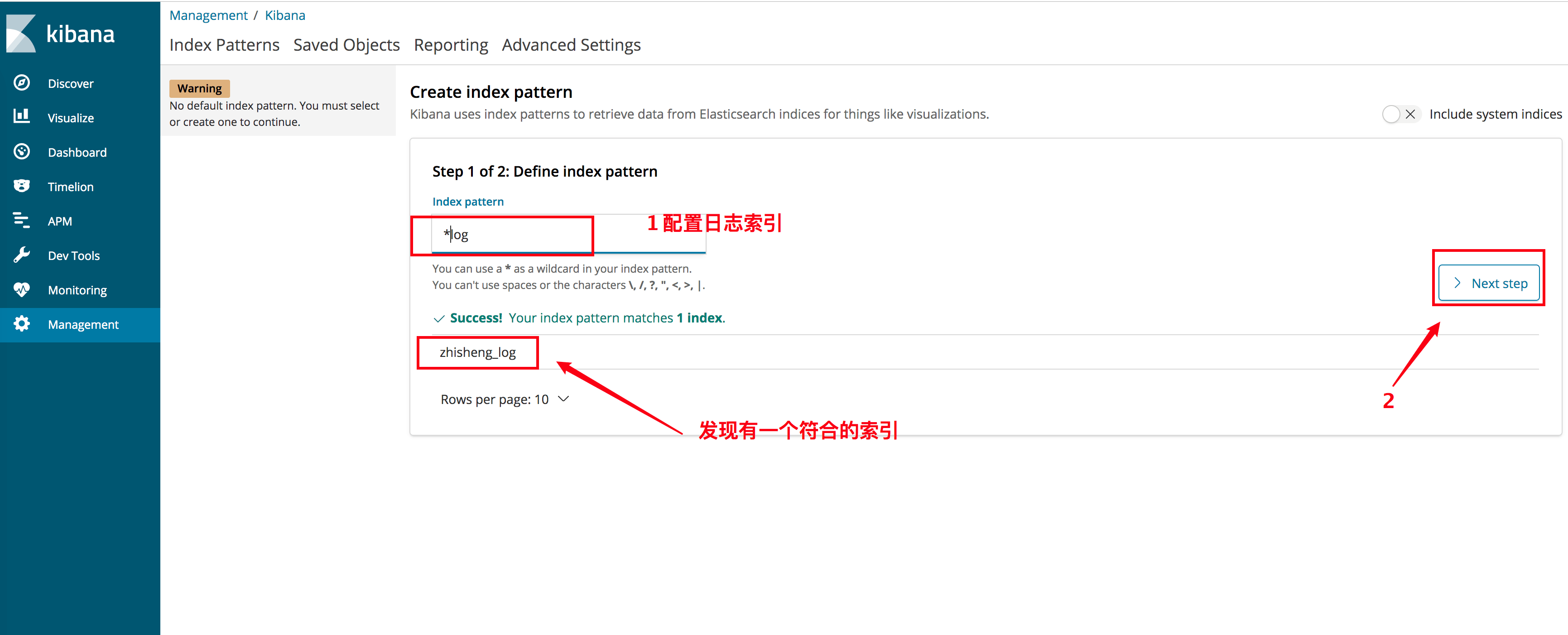 配置好索引后的页面如下图所示。
配置好索引后的页面如下图所示。
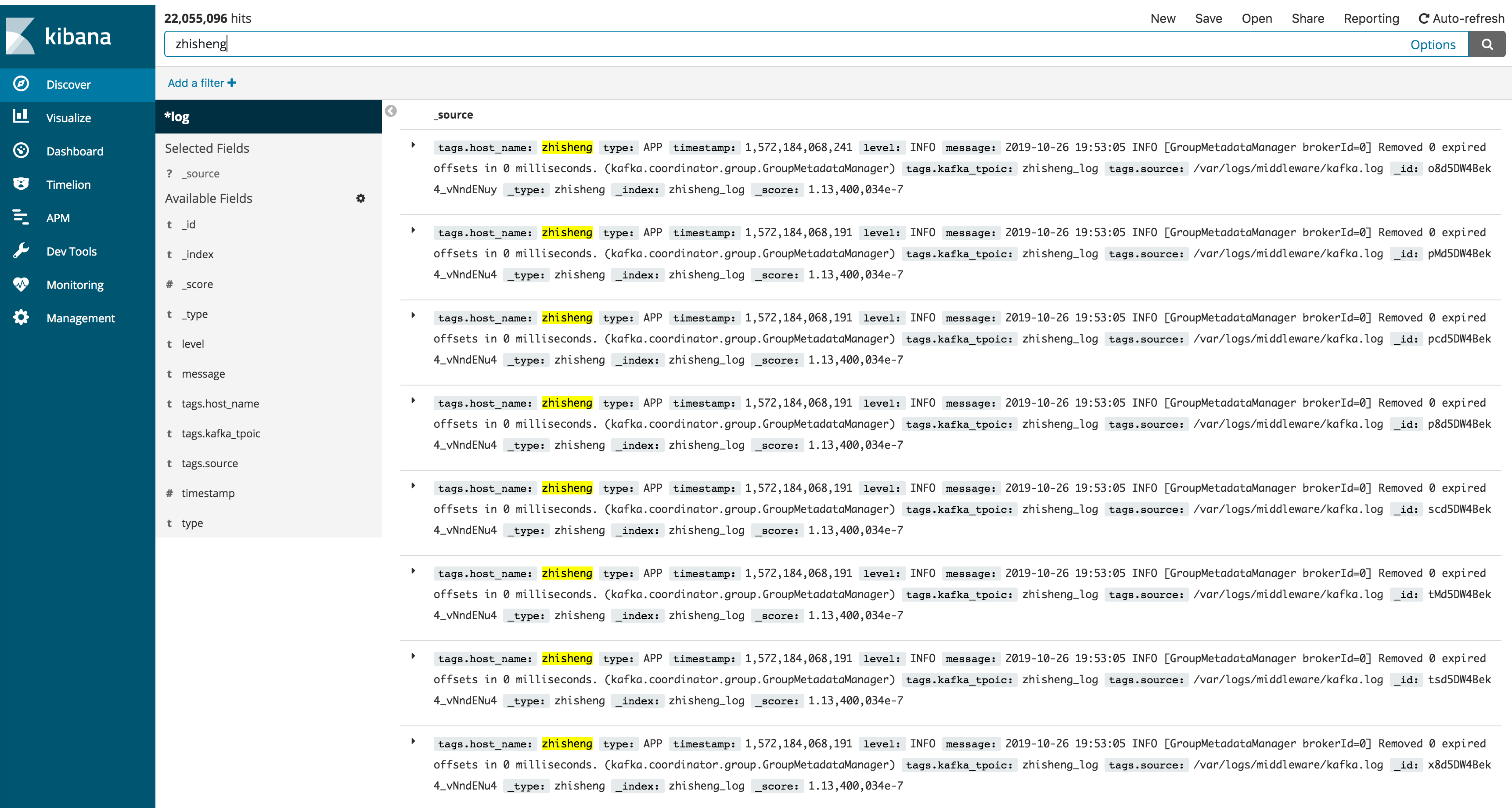
 这时我们要搜索日志的话,可以点击左侧的 Discover,就会出现日志了,另外还提供搜素框,支持搜索关键字,搜索结果中的关键字还会高亮。
这时我们要搜索日志的话,可以点击左侧的 Discover,就会出现日志了,另外还提供搜素框,支持搜索关键字,搜索结果中的关键字还会高亮。
# 小结与反思
本节讲解了一个生产环境中的大型案例 —— 日志的实时处理系统,从需求分析到架构设计,再到日志数据的采集、数据清洗、异常日志的实时告警、数据的存储和数据的可视化展示,通过这个大型案例让你了解到一个项目的全链路,让你对整个项目开发的生命周期有了一定的了解,同时笔者也希望你能从该案例中获得启发,然后将其部分思想应用在你们自己公司的场景中,让你在你们公司起到主干力量的作用。另外,你们公司有日志实时处理的系统吗?其架构又是怎么样的呢?对比本节的内容,你觉得你们的系统有什么地方需要完善和补充的地方呢?
本节涉及的代码地址:https://github.com/zhisheng17/flink-learning/tree/master/flink- learning-monitor/flink-learning-monitor-log
pattern 文件链接:https://github.com/thekrakken/java- grok/blob/master/src/main/resources/patterns/patterns