# 如何统计网站各页面一天内的PV和UV?
大数据开发最常统计的需求可能就是 PV、UV。PV 全拼 PageView,即页面访问量,用户每次对网站的访问均被记录,按照访问量进行累计,假如用户对同一页面访问了 5 次,那该页面的 PV 就应该加 5。UV 全拼为 UniqueVisitor,即独立访问用户数,访问该页面的一台电脑客户端为一个访客,假如用户对同一页面访问了 5 次,那么该页面的 UV 只应该加 1,因为 UV 计算的是去重后的用户数而不是访问次数。当然如果是按天统计,那么当天 0 点到 24 点相同的客户端只被计算一次,如果过了今天 24 点,第二天该用户又访问了该页面,那么第二天该页面的 UV 应该加 1。 概念明白了那如何使用 Flink 来统计网站各页面的 PV 和 UV 呢?通过本节来详细描述。
# 统计网站各页面一天内的 PV
在 9.5.2 节端对端如何保证 Exactly Once 中的幂等性写入如何保证端对端 Exactly Once 部分已经用案例讲述了如何通过 Flink 的状态来计算 app 的 PV,并能够保证 Exactly Once。如果在工作中需要计算网站各页面一天内的 PV,只需要将案例中的 app 替换成各页面的 id 或者各页面的 url 进行统计即可,按照各页面 id 和日期组合做为 key 进行 keyBy,相同页面、相同日期的数据发送到相同的实例中进行 PV 值的累加,每个 key 对应一个 ValueState,将 PV 值维护在 ValueState 即可。如果一些页面属于爆款页面,例如首页或者活动页面访问特别频繁就可能出现某些 subtask 上的数据量特别大,导致各个 subtask 之前出现数据倾斜的问题,关于数据倾斜的解决方案请参考 9.6 节。
# 统计网站各页面一天内的 UV
PV 统计相对来说比较简单,每来一条用户的访问日志只需要从日志中提取出相应的页面 id 和日期,将其对应的 PV 值加一即可。相对而言统计 UV 就有难度了,同一个用户一天内多次访问同一个页面,只能计数一次。所以每来一条日志,日志中对应页面的 UV 值是否需要加一呢?存在两种情况:如果该用户今天第一次访问该页面,那么 UV 应该加一。如果该用户今天不是第一次访问该页面,表示 UV 中已经记录了该用户,UV 要基于用户去重,所以此时 UV 值不应该加一。难点就在于如何判断该用户今天是不是第一次访问该页面呢?
把问题简单化,先不考虑日期,现在统计网站各页面的累积 UV,可以为每个页面维护一个 Set 集合,假如网站有 10 个页面,那么就维护 10 个 Set 集合,集合中存放着所有访问过该页面用户的 user_id。每来一条用户的访问日志,我们都需要从日志中解析出相应的页面 id 和用户 user_id,去该页面 id 对应的 Set 中查找该 user_id 之前有没有访问过该页面,如果 Set 中包含该 user_id 表示该用户之前访问过该页面,所以该页面的 UV 值不应该加一,如果 Set 中不包含该 user_id 表示该用户之前没有访问过该页面,所以该页面的 UV 值应该加一,并且将该 user_id 插入到该页面对应的 Set 中,表示该用户访问过该页面了。要按天去统计各页面 UV,只需要将日期和页面 id 看做一个整体 key,每个 key 对应一个 Set,其他流程与上述类似。具体的程序流程图如下图所示:
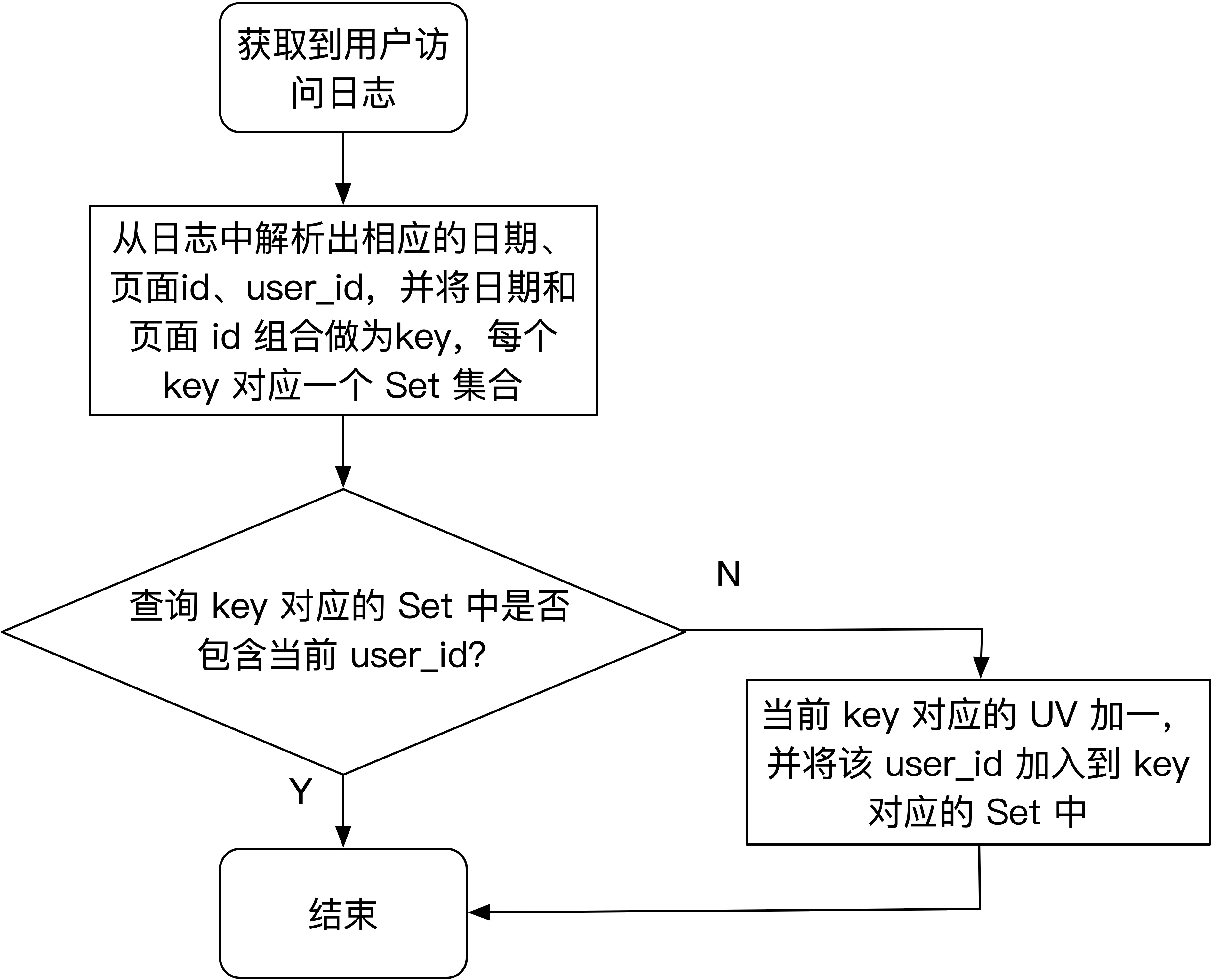
# 使用 Redis 的 set 来维护用户集合
每个 key 都需要维护一个 Set,这个 Set 存放在哪里呢?这里每条日志都需要访问一次 Set,对 Set 访问比较频繁,对存储介质的延迟要求比较高,所以可以使用 Redis 的 set 数据结构,Redis 的 set 数据结构也会对数据进行去重。可以将页面 id 和日期拼接做为 Redis 的 key,通过 Redis 的 sadd 命令将 user_id 放到 key 对应的 set 中即可。Redis 的 set 中存放着今天访问过该页面所有用户的 user_id。
在真实的工作中,Flink 任务可能不需要维护一个 UV 值,Flink 任务承担的角色是实时计算,而查询 UV 可能是一个 Java Web 项目。Web 项目只需要去 Redis 查询相应 key 对应的 set 中元素的个数即可,Redis 的 set 数据结构有 scard 命令可以查询 set 中元素个数,这里的元素个数就是我们所要统计的网站各页面每天的 UV 值。所以使用 Redis set 数据结构的方案 Flink 任务的代码很简单,只需要从日志中解析出相应的日期、页面id 和 user_id,将日期和页面 id 组合做为 Redis 的 key,最后将 user_id 通过 sadd 命令添加到 set 中,Flink 任务的工作就结束了,之后 Web 项目就能从 Redis 中查询到实时增加的 UV 了。下面来看详细的代码实现。
用户访问网站页面的日志实体类:
public class UserVisitWebEvent {
// 日志的唯一 id
private String id;
// 日期,如:20191025
private String date;
// 页面 id
private Integer pageId;
// 用户的唯一标识,用户 id
private String userId;
// 页面的 url
private String url;
}
生成测试数据的核心代码如下:
String yyyyMMdd = new DateTime(System.currentTimeMillis()).toString("yyyyMMdd");
int pageId = random.nextInt(10); // 随机生成页面 id
int userId = random.nextInt(100); // 随机生成用户 id
UserVisitWebEvent userVisitWebEvent = UserVisitWebEvent.builder()
.id(UUID.randomUUID().toString()) // 日志的唯一 id
.date(yyyyMMdd) // 日期
.pageId(pageId) // 页面 id
.userId(Integer.toString(userId)) // 用户 id
.url("url/" + pageId) // 页面的 url
.build();
// 对象序列化为 JSON 发送到 Kafka
ProducerRecord record = new ProducerRecord<String, String>(topic,
null, null, GsonUtil.toJson(userVisitWebEvent));
producer.send(record);
统计 UV 的核心代码如下,对 Redis Connector 不熟悉的请参阅 3.11 节如何使用 Flink Connectors —— Redis:
public class RedisSetUvExample {
public static void main(String[] args) throws Exception {
// 省略了 env初始化及 checkpoint 相关配置
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, UvExampleUtil.broker_list);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "app-uv-stat");
FlinkKafkaConsumerBase<String> kafkaConsumer = new FlinkKafkaConsumer011<>(
UvExampleUtil.topic, new SimpleStringSchema(), props)
.setStartFromLatest();
FlinkJedisPoolConfig conf = new FlinkJedisPoolConfig
.Builder().setHost("192.168.30.244").build();
env.addSource(kafkaConsumer)
.map(string -> {
// 反序列化 JSON
UserVisitWebEvent userVisitWebEvent = GsonUtil.fromJson(
string, UserVisitWebEvent.class);
// 生成 Redis key,格式为 日期_pageId,如: 20191026_0
String redisKey = userVisitWebEvent.getDate() + "_"
+ userVisitWebEvent.getPageId();
return Tuple2.of(redisKey, userVisitWebEvent.getUserId());
})
.returns(new TypeHint<Tuple2<String, String>>(){})
.addSink(new RedisSink<>(conf, new RedisSaddSinkMapper()));
env.execute("Redis Set UV Stat");
}
// 数据与 Redis key 的映射关系
public static class RedisSaddSinkMapper
implements RedisMapper<Tuple2<String, String>> {
@Override
public RedisCommandDescription getCommandDescription() {
// 这里必须是 sadd 操作
return new RedisCommandDescription(RedisCommand.SADD);
}
@Override
public String getKeyFromData(Tuple2<String, String> data) {
return data.f0;
}
@Override
public String getValueFromData(Tuple2<String, String> data) {
return data.f1;
}
}
}
Redis 中统计结果如下图所示,左侧展示的 Redis key,20191026_1 表示 2019 年 10 月 26 日浏览过 pageId 为 1 的页面对应的 key,右侧展示 key 对应的 set 集合,表示 userId 为 [0,6,27,30,66,67,79,88] 的用户在 2019 年 10 月 26 日浏览过 pageId 为 1 的页面。
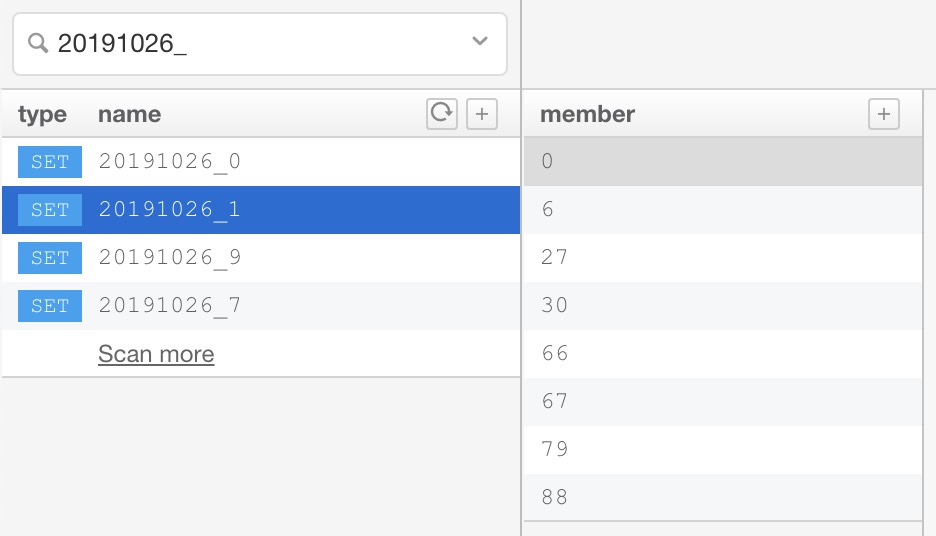 要想获取 20191026_1 对应的 UV 值,可通过 scard 命令获取 set 中 user_id 的数量,具体操作如下所示:
要想获取 20191026_1 对应的 UV 值,可通过 scard 命令获取 set 中 user_id 的数量,具体操作如下所示:
redis> scard 20191026_1
8
通过上述代码即可通过 Redis 的 set 数据结构来统计网站各页面的 UV。具体代码实现请参阅:
<https://github.com/zhisheng17/flink-learning/blob/master/flink-learning- monitor/flink-learning-monitor- pvuv/src/main/java/com/zhisheng/monitor/pvuv/RedisSetUvExample.java>
# 使用 Flink 的 KeyedState 来维护用户集合
如果不想依赖第三方存储来维护每个页面所访问用户的集合,可以使用 Flink 的 KeyedState 来存储用户集合,将用户集合保存到 Flink 内置的状态后端。按照日期和 pageId 进行 keyBy,相同页面的用户访问日志都会发送到同一个 Operator 实例去处理,每个页面会对应一个 KeyedState。
该案例状态中需要存储访问过该页面用户的 userId 集合,所以可以选择 ListState 或 MapState 存储 userId 集合。但计算 UV
需要对 userId 进行去重,所以在这里选用 MapState 更合理,MapState 类似于 Java 中的 Map,存储着 kv 键值对,并且
key 不能重复。日期和 pageId 组合起来做为 Flink 中 keyBy 算子的 key,每个日期和页面的组合对应一个
MapState,MapState 的 key 存储 userId,MapState 的 value 不需要存储数据默认补 null 即可。MapState
中 userId 的个数就是要统计的各页面的 UV,但 Flink 不支持获取 MapState 中 key 的个数,所以为了统计
UV,需要使用单独状态来维护,这里使用 ValueState<Long> 来维护 UV 值,相当于每个日期和页面的组合对应一个 MapState 和
ValueState,MapState 中用来存储 userId 的集合、ValueState 中存储 MapState 中 userId
的个数,也就是要统计的 UV 结果。
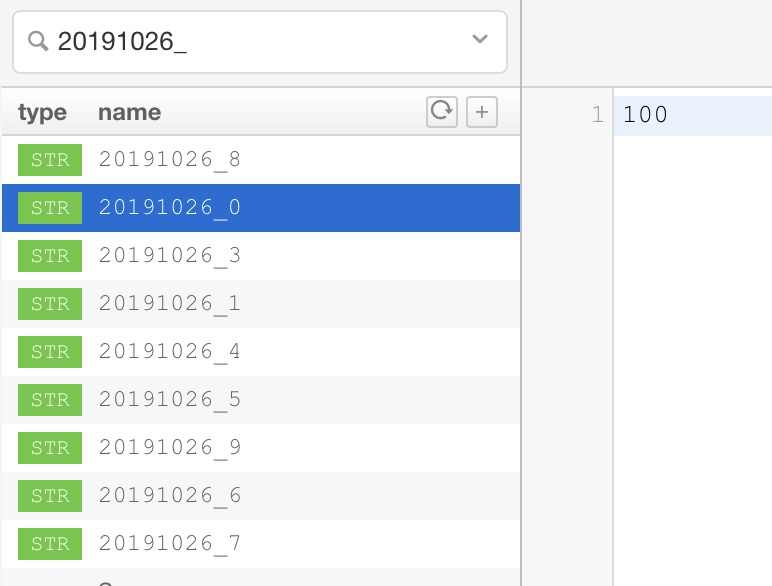
最后将统计的 UV 结果输出到 Redis 中。这次 Redis 中使用的不是 set 数据结构,而是 string 数据结构,Redis 的 key 是日期和页面的组合,格式为 日期_pageId,如: 20191026_0,Redis 的 value 为 key 对应的 UV 结果,如:100。 具体代码如下所示:
public class MapStateUvExample {
public static void main(String[] args) throws Exception {
// 省略了 env初始化及 checkpoint 相关配置
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, UvExampleUtil.broker_list);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "app-uv-stat");
FlinkKafkaConsumerBase<String> kafkaConsumer = new FlinkKafkaConsumer011<>(
UvExampleUtil.topic, new SimpleStringSchema(), props)
.setStartFromGroupOffsets();
FlinkJedisPoolConfig conf = new FlinkJedisPoolConfig
.Builder().setHost("192.168.30.244").build();
env.addSource(kafkaConsumer)
.map(str -> GsonUtil.fromJson(str, UserVisitWebEvent.class)) // 反序列化JSON
.keyBy("date","pageId") // 按照 日期和页面 进行 keyBy
.map(new RichMapFunction<UserVisitWebEvent, Tuple2<String, Long>>() {
// 存储当前 key 对应的 userId 集合
private MapState<String,Boolean> userIdState;
// 存储当前 key 对应的 UV 值
private ValueState<Long> uvState;
@Override
public Tuple2<String, Long> map(UserVisitWebEvent userVisitWebEvent) {
// 初始化 uvState
if(null == uvState.value()){
uvState.update(0L);
}
// userIdState 中不包含当前访问的 userId,说明该用户今天还未访问过该页面
// 则将该 userId put 到 userIdState 中,并把 UV 值 +1
if(!userIdState.contains(userVisitWebEvent.getUserId())){
userIdState.put(userVisitWebEvent.getUserId(),null);
uvState.update(uvState.value() + 1);
}
// 生成 Redis key,格式为 日期_pageId,如: 20191026_0
String redisKey = userVisitWebEvent.getDate() + "_"
+ userVisitWebEvent.getPageId();
System.out.println(redisKey + " ::: " + uvState.value());
return Tuple2.of(redisKey, uvState.value());
}
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
// 从状态中恢复 userIdState
userIdState = getRuntimeContext().getMapState(
new MapStateDescriptor<>("userIdState",
TypeInformation.of(new TypeHint<String>() {}),
TypeInformation.of(new TypeHint<Boolean>() {})));
// 从状态中恢复 uvState
uvState = getRuntimeContext().getState(
new ValueStateDescriptor<>("uvState",
TypeInformation.of(new TypeHint<Long>() {})));
}
})
.addSink(new RedisSink<>(conf, new RedisSetSinkMapper()));
env.execute("Redis Set UV Stat");
}
// 数据与 Redis key 的映射关系,并指定将数据 set 到 Redis
public static class RedisSetSinkMapper
implements RedisMapper<Tuple2<String, Long>> {
@Override
public RedisCommandDescription getCommandDescription() {
// 这里必须是 set 操作,通过 MapState 来维护用户集合,
// 输出到 Redis 仅仅是为了展示结果供其他系统查询统计结果
return new RedisCommandDescription(RedisCommand.SET);
}
@Override
public String getKeyFromData(Tuple2<String, Long> data) {
return data.f0;
}
@Override
public String getValueFromData(Tuple2<String, Long> data) {
return data.f1.toString();
}
}
}
该设计方案中,Redis 承担的功能仅仅是为了外部系统查询网站各页面对应的 UV 结果,当然也可以将 Redis 替换成其他存储系统,例如 HBase、MySQL 等。UV 的统计依赖的是 Flink 的 MapState 和 ValueState,所以对 Redis 的使用都是 set 操作,将 UV 结果从 Flink 推到 Redis 中。Redis 中存储的统计结果如下图所示,Redis 中 key 20191026_0 对应的 value 为 100 表示 2019 年 10 月 26 日 100 个用户访问过 0 号页面。
 目前讲述了 2 种方案来统计各页面的 UV,2 种方案的思想类似,都是每个页面维护一个 Set 集合,Set 集合中存放着访问过该页面的所有
userId,Set 集合中元素的个数就是该页面对应的 UV 结果。
目前讲述了 2 种方案来统计各页面的 UV,2 种方案的思想类似,都是每个页面维护一个 Set 集合,Set 集合中存放着访问过该页面的所有
userId,Set 集合中元素的个数就是该页面对应的 UV 结果。
两种方案的不同点是 Redis 完全将 Set 集合维护在内存中,而 Flink 的状态将 Set 集合维护在 Flink 的状态后端,目前 Flink 支持 3 种形式的状态后端,分别是 MemoryStateBackend、FsStateBackend 和 RocksDBStateBackend,3 种状态后端的详细介绍请参考 4.2 节如何选择 Flink 状态后端存储。
假如网站有 100 个页面,那我们的应用程序只需要维护 100 个 set 集合就能统计出这 100 个页面的 UV。如果你是字节跳动的流计算工程师,现在需要统计今日头条信息流中所有文章(资讯)每天实时阅读的 UV 或者统计抖音所有小视频每天实时播放的 UV,如果使用 Redis set 数据结构的方案统计 UV,需要为每个小视频都维护一个 set 集合,set 中存放着所有观看过该小视频的 userId。
为了节省内存,userId 使用 long 类型来保存,每个 userId 占用 8 个字节,每天有很多热门小视频,笔者每天刷到的点赞量 200 万以上的视频很多,所以播放量在千万以上的小视频太多了,一个小视频如果播放量 1 千万,那么它对应的 set 集合占用多大内存呢?1 千万 * 8 字节约为 80MB,所以单个热门小视频就要占用 80 M 的内存空间。由于热门视频较多,因此如果使用该方案统计 UV,显然会占用很大的存储空间。
在真正的工作中,有时候需要看到的数据并不需要很准确,例如该小视频的播放量 100 万和 99.5 万对于数据分析师们并没有影响。所以,有没有一种节省内存但能近似计算 UV 的方案呢?下面让我们来学习一种新的数据结构 HyperLogLog。
# 使用 Redis 的 HyperLogLog 来统计 UV
Redis 中有一种高级数据结构 HyperLogLog,最常用的 2 种操作是 pfadd 和 pfcount。pfadd 表示往 HyperLogLog 中添加元素,pfcount 统计 HyperLogLog 中元素去重后的个数。对于之前使用 set 集合来存放 userId 的方案,完全可以替换成 HyperLogLog 来存储,网站每个页面对应一个 HyperLogLog,使用 pfadd 将 userId 添加到 HyperLogLog 中,通过 pfcount 可以统计出网站各页面的访问用户数。HyperLogLog 是通过概率算法来实现去重计数的,并没有存储真正的 userId 数据,所以占用的内存空间会少一些,下面介绍一下 HyperLogLog 实现原理。
了解 HyperLogLog 实现原理,先从抛硬币开始说起。
- 抛 1 颗硬币,1 个硬币反面的概率为 1/2
- 抛 2 颗硬币,2 个硬币同时为反面的概率为 1/4
- 抛 3 颗硬币,3 个硬币同时为反面的概率为 1/8
- 抛 4 颗硬币,4 个硬币同时为反面的概率为 1/16
- 抛 5 颗硬币,5 个硬币同时为反面的概率为 1/32
- 抛 n 颗硬币,n 个硬币同时为反面的概率为 1/2n
例如,张三抛 5 个硬币,抛了很多次后,5 个硬币全是反面,如果让李四去猜张三抛了多少次硬币,根据概率来讲,应该抛了 32 次,因为抛 5 个硬币,5 个硬币同时为反面的概率为 1/32。当然这么猜的话,误差比较大,但是当数据量足够大且足够随机时,可以根据 n 猜大概抛了多少次。把抛硬币的例子换成随机整数,一个随机的整数换算成二进制后,最后一位要么是 0 要么是 1,所以随机生成的整数转换为二进制时:
- 最后一位是 0 的概率是 1/2
- 最后 2 位全是 0 的概率是 1/4
- 最后 3 位全是 0 的概率是 1/8
- 最后 4 位全是 0 的概率是 1/16
- 最后 5 位全是 0 的概率是 1/32
- 最后 n 位全是 0 的概率是 1/2n
如果随机生成了很多整数,整数的数量并不知道,但是记录了整数尾部连续 0 的最大数量 K。假如生成了 4 个数 a、b、c、d,换算成二进制后:
- a 的最后三位是 100,尾部连续 0 的个数为 2
- b 的最后三位为 101,尾部连续 0 的个数为 0
- c 的最后三位为 110,尾部连续 0 的个数为 1
- d 的最后三位为 111,尾部连续 0 的个数为 0
注:大家只需要关注最后两位即可,最后两位转换成二进制后,有四种可能 00、01、10、11,每种情况的概率都为 1/4,所以这里举例四种情况各发生一次。
所以 a、b、c、d 这 4 个整数尾部连续 0 的最大数量为 K = 2。可以通过这个 K = 2 来近似推断出生成的随机整数的数量 2K = 22 = 4。问题来了,随机生成 2K 个整数或者 2K+1、2K-1 个整数,尾部连续 0 的最大数量可能都对应 K,怎么办?换言之,无论生成 7 个整数、8 个整数还是 9 个整数,最后计算发现尾部连续 0 的个数都是 3。或者抛 3 个硬币,可能抛 7 次、8次或者 9次都可能出现 3 个硬币同时为反面,但通过公式只能推出抛了 8 次,而不能推出 7 或者 9。所以导致无论抛 7 次、8 次还是 9 次硬币,估算的抛硬币次数永远是 8,计算的结果永远是 2 的整数次幂,如何解决结果永远是 2 的整数次幂的问题呢?可以使用分桶的策略,根据 n 个桶中的 k1、k2……kn 求平均值 k。例如生成随机整数时,将生成的整数根据 hash 策略分到 4 个桶中,4 个桶中整数尾部连续 0 的最大数量分别是 3、4、5、6,则猜测总共生成整数的数量为 2(3+4+5+6)/4=24.5,通过分桶策略得到的 k 值就不是整数了,所以计算得到生成的整数数量就不全是 2 的整数次幂了。
假如生成的随机整数中恰好有一个整数的尾部连续很多位都是 0,那么这个整数可能会影响计算,会导致我们计算结果偏高。例如 4 个桶中 k 值分别为 3、4、5、104,其中 104 是由一个干扰数据生成的,最后 avg = (3+4+5+104) / 4 = 29,所以认为生成的随机整数的个数为 229。像这种问题如何解决呢?HyperLogLog 使用了调和平均来计算平均数,也就是倒数的平均数,avg = 4/ (1/3+1/4+1/5+1/104) = 5.044,所以生成的随机整数的个数为 25.044,通过调和平均的方式解决了干扰数据的问题。
上述原理,就是 HyperLogLog 的大概思想,使用 pfadd 将 userId 加入到 HyperLogLog 时,HyperLogLog 会将 userId 根据 hash 策略分到各个桶中,每个桶内根据 userId 计算生成一个 k 值,然后求出所有桶中 k 的调和平均数,最后根据求得的平均数估算出 HyperLogLog 中 userId 的用户数。可以发现相同的 userId 根据 hash 策略肯定会分到同一个桶中,而且相同的 userId 对应的 k 值也会相同,所以同一个 userId 往 HyperLogLog 中插入 1000 次也会被去重掉。
一个 HyperLogLog 最多占用是 12k 内存空间,在 Redis 的 HyperLogLog 实现中用的是 16384 个桶,也就是 214 个桶,每个桶最多需要 6 个 bit 来存储,最大可以表示的数据范围 maxbits = 26 - 1 = 63,所以最多占用内存就是 214 * 6 / 8 =12 KB。当 HyperLogLog 中数量比较少时,采用稀疏存储,占用内存远小于 12 KB。所以对于单个热门小视频的 UV 统计,热门视频 userId 占用 80MB 内存的方案已经优化成仅占用 12KB 内存。使用 HyperLogLog 统计 UV 的方案与 Redis set 统计 UV 的方案相比,代码实现改动很小,只是把 Redis 的 sadd 命令替换为 pfadd 命令即可。改动代码如下所示:
// 数据与 Redis key 的映射关系,并指定将数据 pfadd 到 Redis
public static class RedisPfaddSinkMapper
implements RedisMapper<Tuple2<String, String>> {
@Override
public RedisCommandDescription getCommandDescription() {
// 这里是 pfadd 操作
return new RedisCommandDescription(RedisCommand.PFADD);
}
@Override
public String getKeyFromData(Tuple2<String, String> data) {
return data.f0;
}
@Override
public String getValueFromData(Tuple2<String, String> data) {
return data.f1;
}
}
Redis 中存储的统计结果如下图所示,Redis 中 key 20191027_5 对应的 value 为 乱码,是按照 HyperLogLog 的格式进行存储。
 如下所示,可以通过 Redis 的 pfcount 命令查询各页面每天对应的 UV 值:
如下所示,可以通过 Redis 的 pfcount 命令查询各页面每天对应的 UV 值:
redis> pfcount 20191027_5
16
redis> pfcount 20191027_0
11
redis> pfcount 20191027_1
17
HyperLogLog 适用场景:将数据插入到 HyperLogLog 中,HyperLogLog 可以对数据去重后,返回 HyperLogLog 中插入了多少个不重复的元素,但是 HyperLogLog 并不能告诉我们某条数据有没有插入到 HyperLogLog 中。例如,往 HyperLogLog 插入了 3 个元素 a、b、c,当来了第 4 个元素 d 时,HyperLogLog 只能估算出之前插入了 3 条元素,并不能告诉我们之前插入的 3 个元素包不包含元素 d。又来了第 5 个元素 a 时,HyperLogLog 也不能告诉我们之前插入的元素中包不包含元素 a。
# 小结与反思
本节首先描述了 PV、UV 的概念,简单回顾了之前章节中 PV 统计的方式。本节着重讲述 UV 的统计,首先介绍统计 UV 应有的基本流程,分别用 Redis 和 KeyedState 来维护网站各页面访问用户的 set 集合,用代码讲述了计算 UV 的详细过程。后面通过内存占用大的问题引出了 HyperLogLog,并详细介绍了 HyperLogLog 的实现原理、适用场景及如何使用 HyperLogLog 来统计 UV。
本节涉及的代码地址:
<https://github.com/zhisheng17/flink-learning/tree/master/flink-learning- monitor/flink-learning-monitor-pvuv>