# FlinkWaterMark详解及结合WaterMark处理延迟数据
在 3.1 节中讲解了 Flink 中的三种 Time 和其对应的使用场景,然后在 3.2 节中深入的讲解了 Flink 中窗口的机制以及 Flink中自带的 Window 的实现原理和使用方法。如果在进行 Window 计算操作的时候,如果使用的时间是 Processing Time,那么在 Flink消费数据的时候,它完全不需要关心的数据本身的时间,意思也就是说不需要关心数据到底是延迟数据还是乱序数据。因为 Processing Time 只是代表数据在Flink 被处理时的时间,这个时间是顺序的。但是如果你使用的是 Event Time 的话,那么你就不得不面临着这么个问题:事件乱序 & 事件延迟。
下图表示选择 Event Time 与 Process Time 的实际效果图:
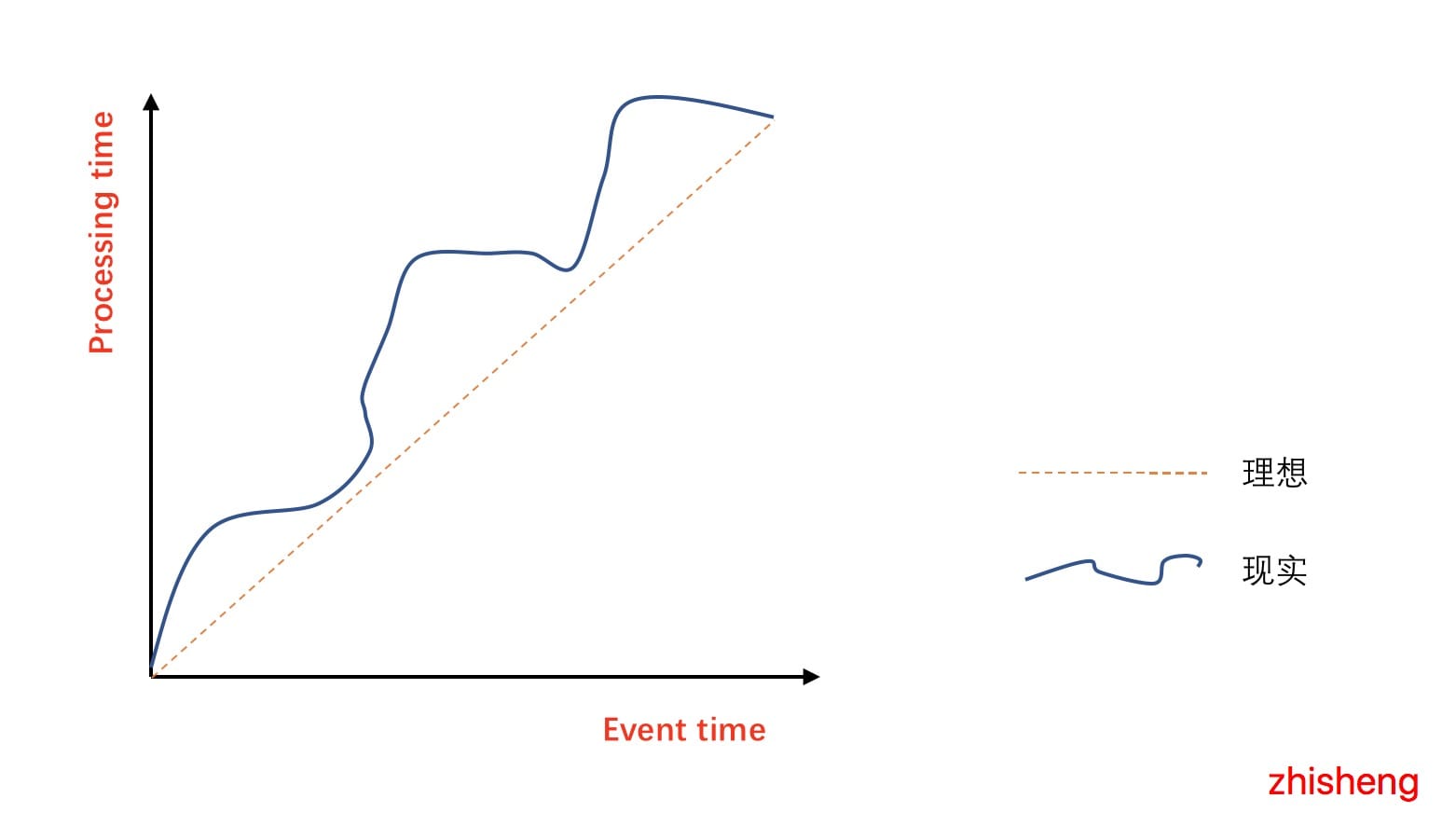
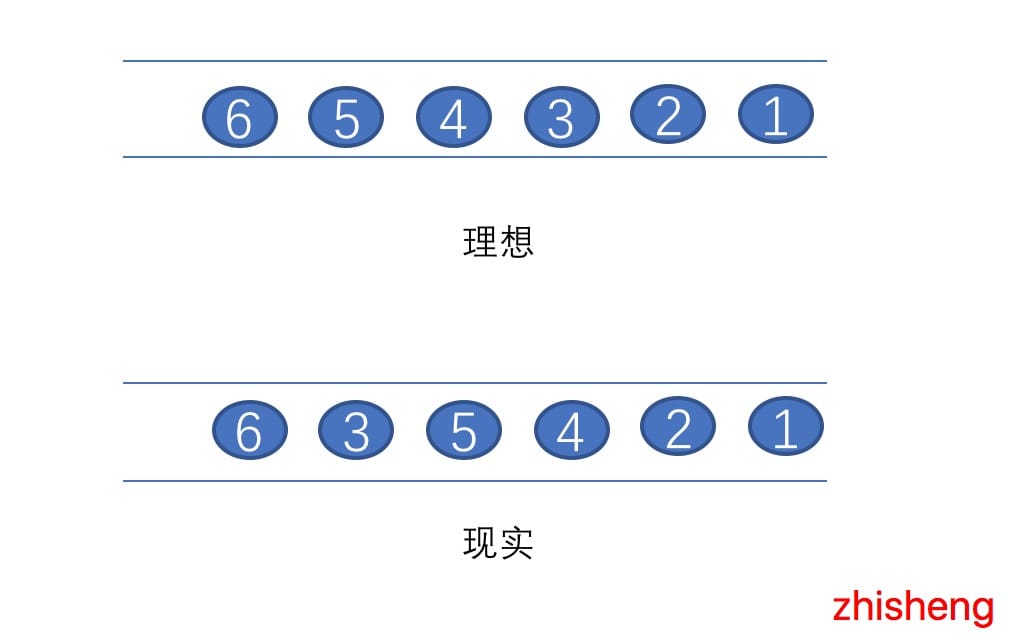
在理想的情况下,Event Time 和 Process Time是相等的,数据发生的时间与数据处理的时间没有延迟,但是现实却仍然这么骨感,会因为各种各样的问题(网络的抖动、设备的故障、应用的异常等原因)从而导致如图中曲线一样,ProcessTime 总是会与 Event Time 有一些延迟。所谓乱序,其实是指 Flink 接收到的事件的先后顺序并不是严格的按照事件的 Event Time顺序排列的。比如下图:
然而在有些场景下,其实是特别依赖于事件时间而不是处理时间,比如:
- 错误日志的时间戳,代表着发生的错误的具体时间,开发们只有知道了这个时间戳,才能去还原那个时间点系统到底发生了什么问题,或者根据那个时间戳去关联其他的事件,找出导致问题触发的罪魁祸首
- 设备传感器或者监控系统实时上传对应时间点的设备周围的监控情况,通过监控大屏可以实时查看,不错漏重要或者可疑的事件
这种情况下,最有意义的事件发生的顺序,而不是事件到达 Flink 后被处理的顺序。庆幸的是 Flink支持用户以事件时间来定义窗口(也支持以处理时间来定义窗口),那么这样就要去解决上面所说的两个问题。针对上面的问题(事件乱序 & 事件延迟),Flink引入了 Watermark 机制来解决。
# Watermark 是什么?
举个例子:
统计 8:00 ~ 9:00 这个时间段打开淘宝 App 的用户数量,Flink这边可以开个窗口做聚合操作,但是由于网络的抖动或者应用采集数据发送延迟等问题,于是无法保证在窗口时间结束的那一刻窗口中是否已经收集好了在 8:00 ~9:00 中用户打开 App的事件数据,但又不能无限期的等下去?当基于事件时间的数据流进行窗口计算时,最为困难的一点也就是如何确定对应当前窗口的事件已经全部到达。然而实际上并不能百分百的准确判断,因此业界常用的方法就是基于已经收集的消息来估算是否还有消息未到达,这就是Watermark 的思想。
Watermark 是一种衡量 Event Time 进展的机制,它是数据本身的一个隐藏属性,数据本身携带着对应的 Watermark。Watermark本质来说就是一个时间戳,代表着比这时间戳早的事件已经全部到达窗口,即假设不会再有比这时间戳还小的事件到达,这个假设是触发窗口计算的基础,只有Watermark 大于窗口对应的结束时间,窗口才会关闭和进行计算。按照这个标准去处理数据,那么如果后面还有比这时间戳更小的数据,那么就视为迟到的数据,对于这部分迟到的数据,Flink也有相应的机制(下文会讲)去处理。
下面通过几个图来了解一下 Watermark 是如何工作的!
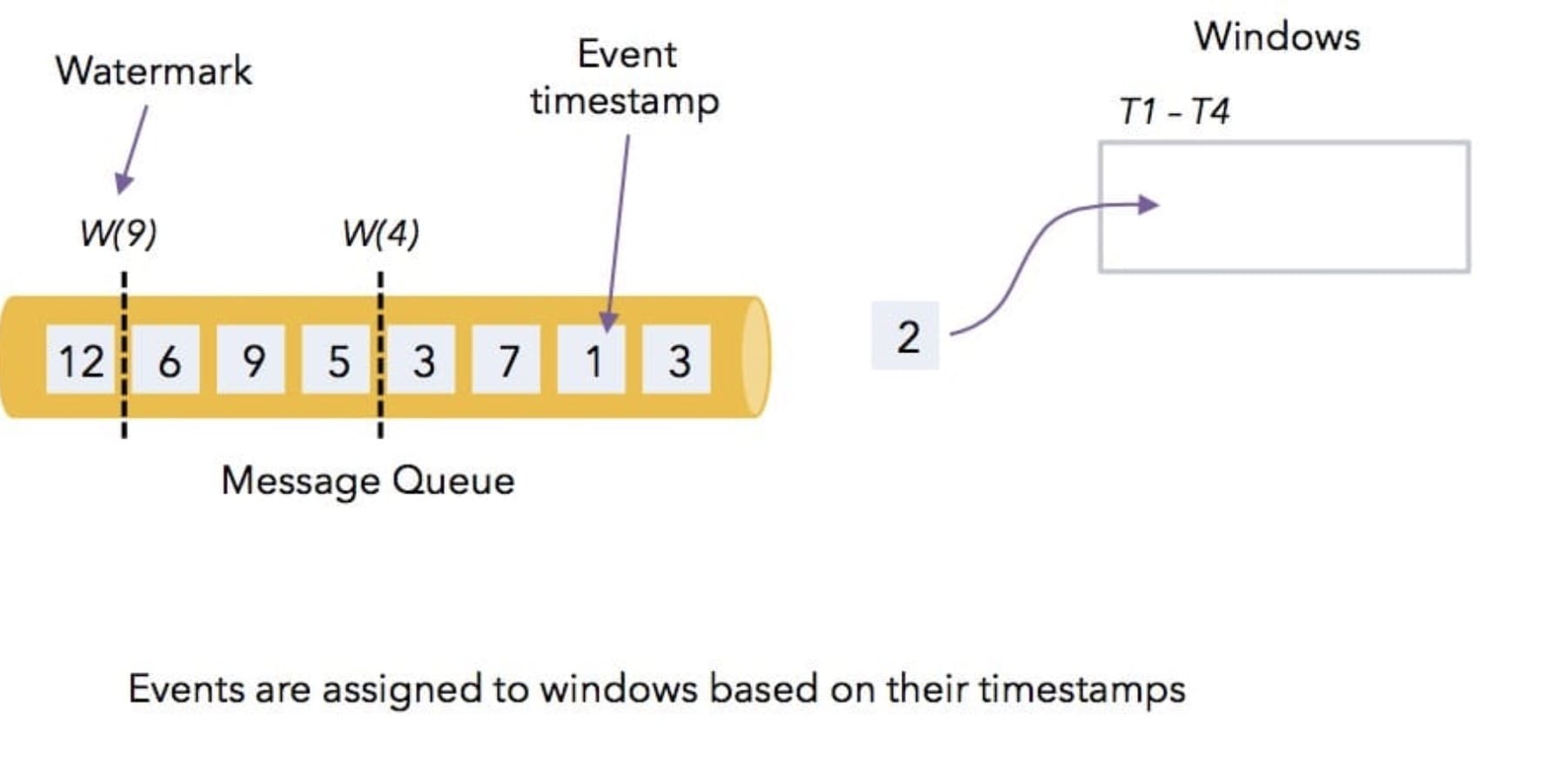
上图中的数据是 Flink 从消息队列中消费的,然后在 Flink 中有个 4s的时间窗口(根据事件时间定义的窗口),消息队列中的数据是乱序过来的,数据上的数字代表着数据本身的 timestamp,W(4) 和 W(9)是水印。
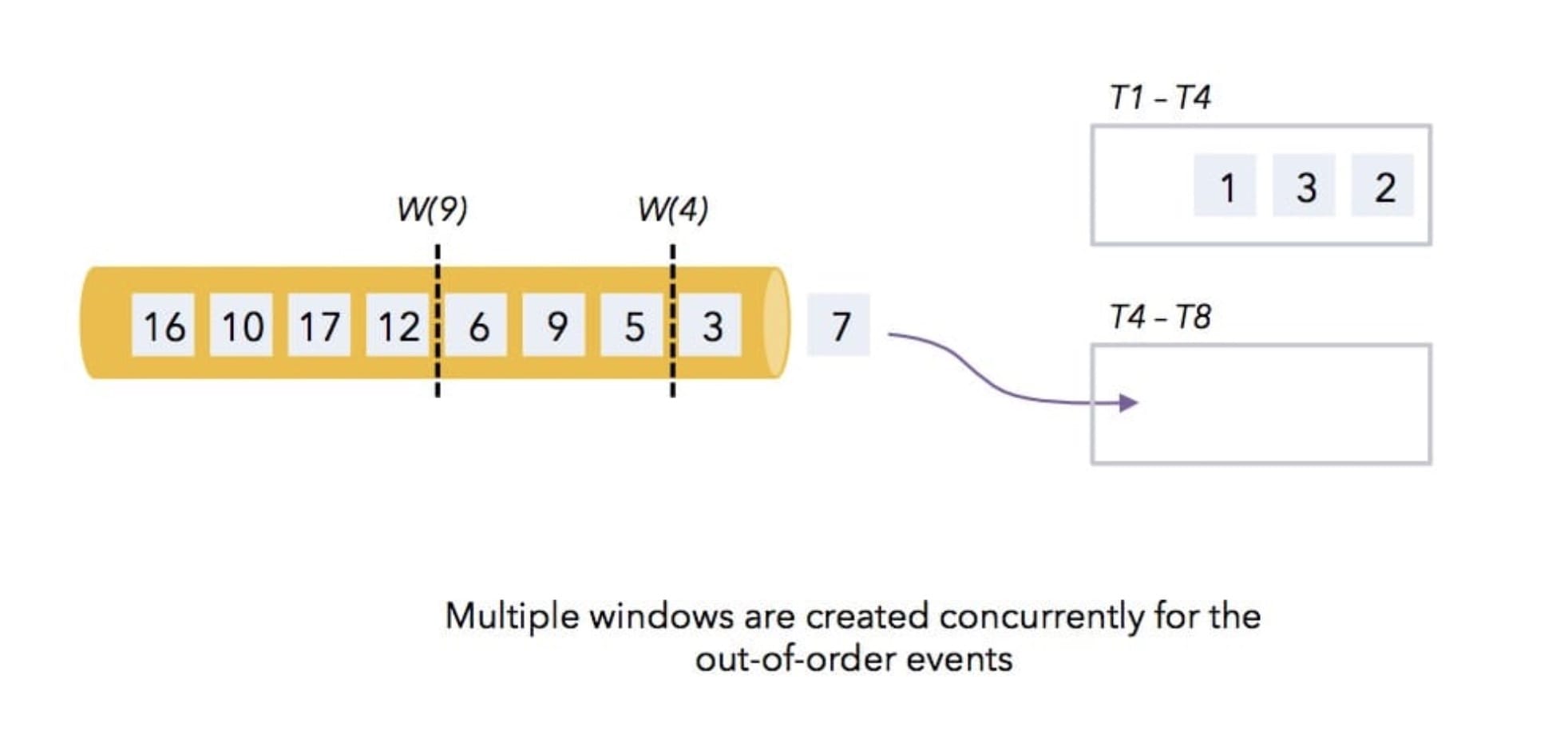
经过 Flink 的消费,数据 1、3、2 进入了第一个窗口,然后 7 会进入第二个窗口,接着 3依旧会进入第一个窗口,然后就有水印了,此时水印过来了,就会发现水印的 timestamp 和第一个窗口结束时间是一致的,那么它就表示在后面不会有比 4还小的数据过来了,接着就会触发第一个窗口的计算操作,如下图所示:
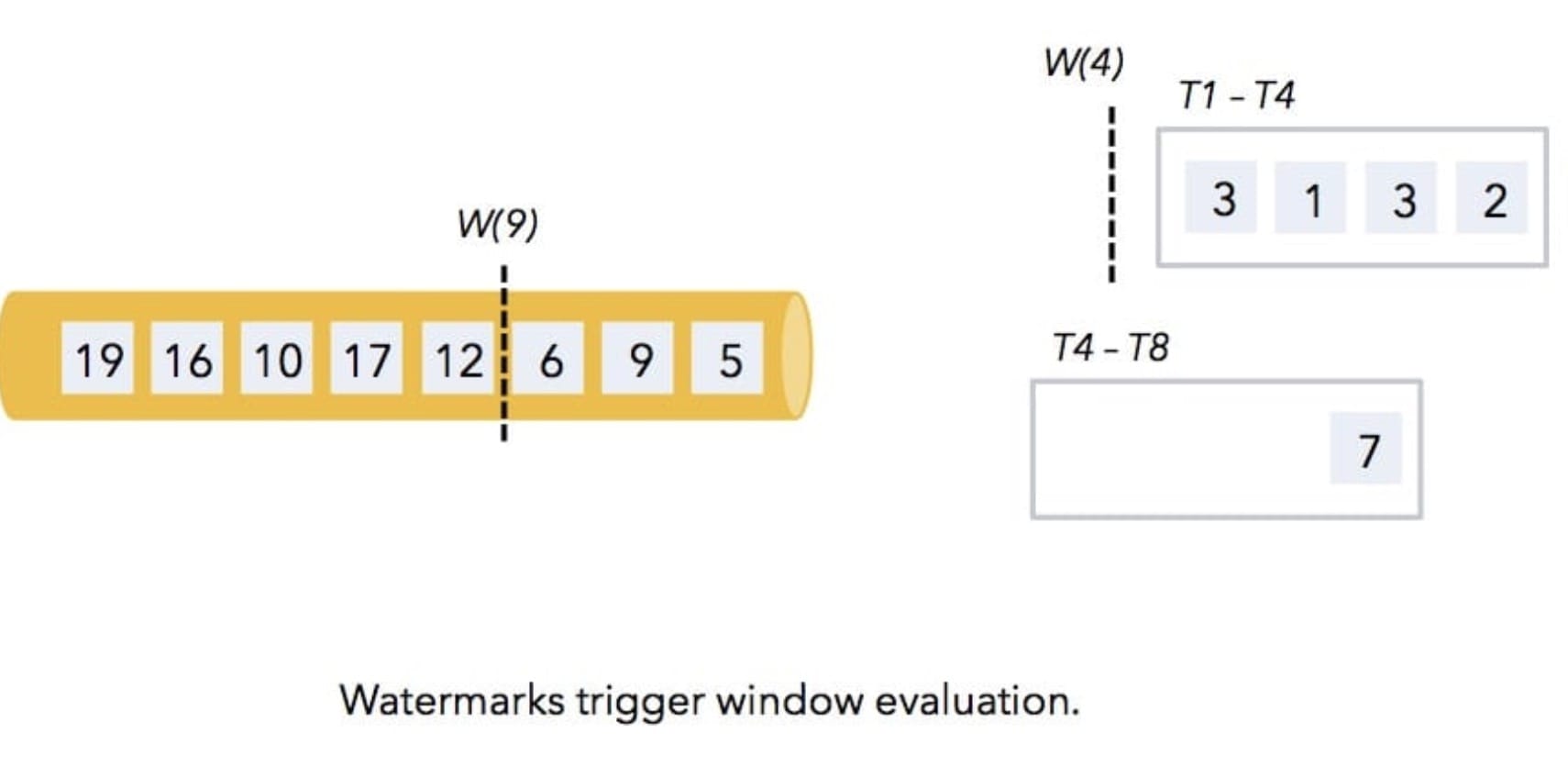 那么接着后面的数据
那么接着后面的数据 5 和 6 会进入到第二个窗口里面,数据 9 会进入在第三个窗口里面。
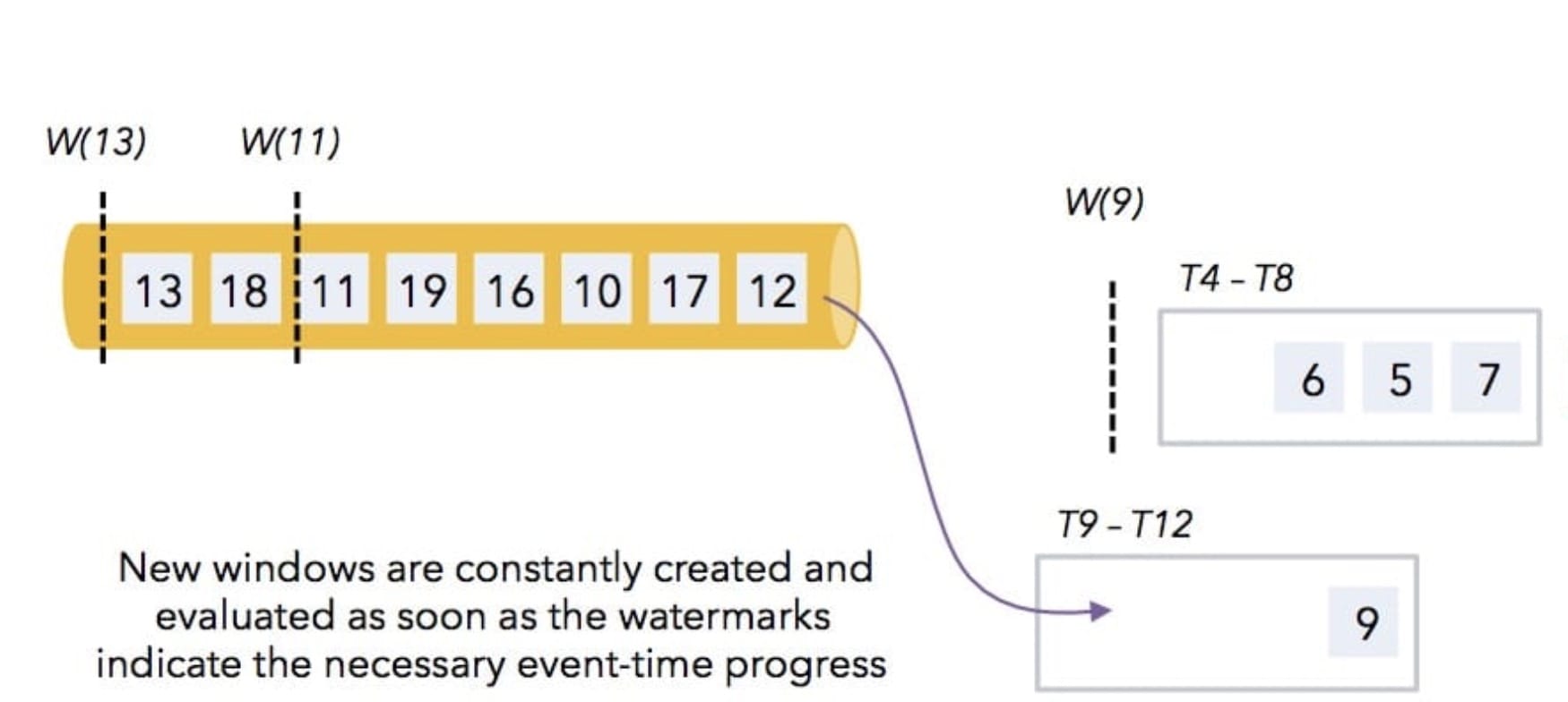
那么当遇到水印 9 时,发现水印比第二个窗口的结束时间 8 还大,所以第二个窗口也会触发进行计算,然后以此继续类推下去。
相信看完上面几个图的讲解,你已经知道了 Watermark 的工作原理是啥了,那么在 Flink 中该如何去配置水印呢,下面一起来看看。
# Flink 中 Watermark 的设置
在 Flink 中,数据处理中需要通过调用 DataStream 中的 assignTimestampsAndWatermarks方法来分配时间和水印,该方法可以传入两种参数,一个是 AssignerWithPeriodicWatermarks,另一个是AssignerWithPunctuatedWatermarks。
public SingleOutputStreamOperator<T> assignTimestampsAndWatermarks(AssignerWithPeriodicWatermarks<T> timestampAndWatermarkAssigner) {
final int inputParallelism = getTransformation().getParallelism();
final AssignerWithPeriodicWatermarks<T> cleanedAssigner = clean(timestampAndWatermarkAssigner);
TimestampsAndPeriodicWatermarksOperator<T> operator = new TimestampsAndPeriodicWatermarksOperator<>(cleanedAssigner);
return transform("Timestamps/Watermarks", getTransformation().getOutputType(), operator).setParallelism(inputParallelism);
}
public SingleOutputStreamOperator<T> assignTimestampsAndWatermarks(AssignerWithPunctuatedWatermarks<T> timestampAndWatermarkAssigner) {
final int inputParallelism = getTransformation().getParallelism();
final AssignerWithPunctuatedWatermarks<T> cleanedAssigner = clean(timestampAndWatermarkAssigner);
TimestampsAndPunctuatedWatermarksOperator<T> operator = new TimestampsAndPunctuatedWatermarksOperator<>(cleanedAssigner);
return transform("Timestamps/Watermarks", getTransformation().getOutputType(), operator).setParallelism(inputParallelism);
}
所以设置 Watermark 是有如下两种方式:
- AssignerWithPunctuatedWatermarks:数据流中每一个递增的 EventTime 都会产生一个 Watermark。
在实际的生产环境中,在 TPS 很高的情况下会产生大量的Watermark,可能在一定程度上会对下游算子造成一定的压力,所以只有在实时性要求非常高的场景才会选择这种方式来进行水印的生成。
- AssignerWithPeriodicWatermarks:周期性的(一定时间间隔或者达到一定的记录条数)产生一个 Watermark。
在实际的生产环境中,通常这种使用较多,它会周期性产生 Watermark 的方式,但是必须结合时间或者积累条数两个维度,否则在极端情况下会有很大的延时,所以 Watermark 的生成方式需要根据业务场景的不同进行不同的选择。
下面再分别详细讲下这两种的实现方式。
# Punctuated Watermark
AssignerWithPunctuatedWatermarks 接口中包含了 checkAndGetNextWatermark 方法,这个方法会在每次extractTimestamp() 方法被调用后调用,它可以决定是否要生成一个新的水印,返回的水印只有在不为 null并且时间戳要大于先前返回的水印时间戳的时候才会发送出去,如果返回的水印是 null 或者返回的水印时间戳比之前的小则不会生成新的水印。
那么该怎么利用这个来定义水印生成器呢?
public class WordPunctuatedWatermark implements AssignerWithPunctuatedWatermarks<Word> {
@Nullable
@Override
public Watermark checkAndGetNextWatermark(Word lastElement, long extractedTimestamp) {
return extractedTimestamp % 3 == 0 ? new Watermark(extractedTimestamp) : null;
}
@Override
public long extractTimestamp(Word element, long previousElementTimestamp) {
return element.getTimestamp();
}
}
需要注意的是这种情况下可以为每个事件都生成一个水印,但是因为水印是要在下游参与计算的,所以过多的话会导致整体计算性能下降。
# 3.5.4 Periodic Watermark
通常在生产环境中使用 AssignerWithPeriodicWatermarks 来定期分配时间戳并生成水印比较多,那么先来讲下这个该如何使用。
public class WordWatermark implements AssignerWithPeriodicWatermarks<Word> {
private long currentTimestamp = Long.MIN_VALUE;
@Override
public long extractTimestamp(Word word, long previousElementTimestamp) {
if (word.getTimestamp() > currentTimestamp) {
this.currentTimestamp = word.getTimestamp();
}
return currentTimestamp;
}
@Nullable
@Override
public Watermark getCurrentWatermark() {
long maxTimeLag = 5000;
return new Watermark(currentTimestamp == Long.MIN_VALUE ? Long.MIN_VALUE : currentTimestamp - maxTimeLag);
}
}
上面的是我根据 Word 数据自定义的水印周期性生成器,在这个类中,有两个方法 extractTimestamp() 和getCurrentWatermark()。extractTimestamp() 方法是从数据本身中提取 EventTime,该方法会返回当前时间戳与事件时间进行比较,如果事件的时间戳比 currentTimestamp 大的话,那么就将当前事件的时间戳赋值给
currentTimestamp。getCurrentWatermark() 方法是获取当前的水位线,这里有个 maxTimeLag参数代表数据能够延迟的时间,上面代码中定义的 long maxTimeLag = 5000; 表示最大允许数据延迟时间为 5s,超过 5s的话如果还来了之前早的数据,那么 Flink 就会丢弃了,因为 Flink的窗口中的数据是要触发的,不可能一直在等着这些迟到的数据(由于网络的问题数据可能一直没发上来)而不让窗口触发结束进行计算操作。
通过定义这个时间,可以避免部分数据因为网络或者其他的问题导致不能够及时上传从而不把这些事件数据作为计算的,那么如果在这延迟之后还有更早的数据到来的话,那么Flink 就会丢弃了,所以合理的设置这个允许延迟的时间也是一门细活,得观察生产环境数据的采集到消息队列再到 Flink整个流程是否会出现延迟,统计平均延迟大概会在什么范围内波动。这也就是说明了一个事实那就是 Flink中设计这个水印的根本目的是来解决部分数据乱序或者数据延迟的问题,而不能真正做到彻底解决这个问题,不过这一特性在相比于其他的流处理框架已经算是非常给力了。
AssignerWithPeriodicWatermarks 这个接口有四个实现类,分别如下图:
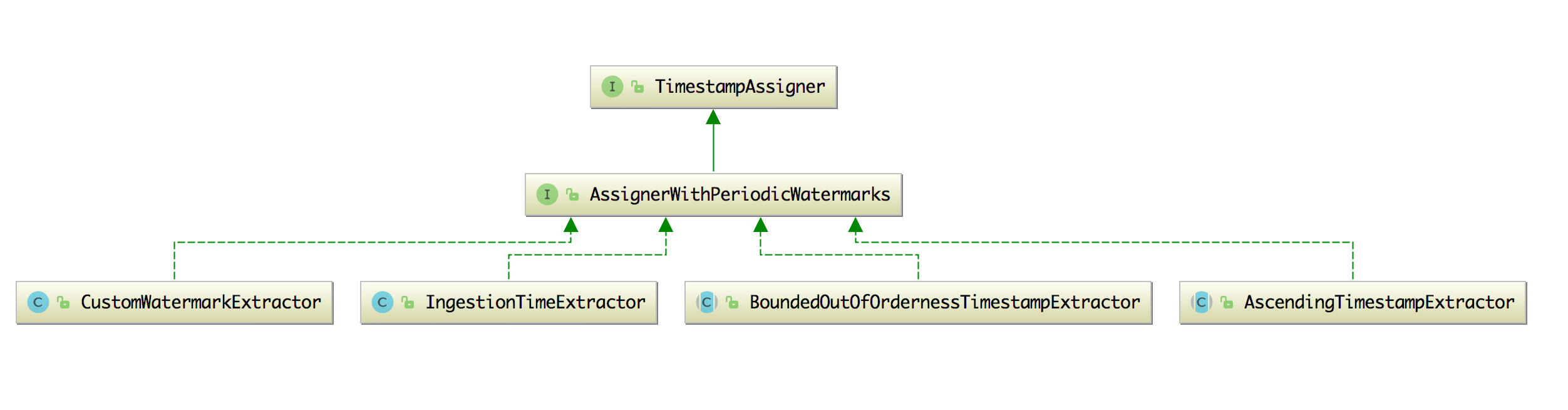
- BoundedOutOfOrdernessTimestampExtractor:该类用来发出滞后于数据时间的水印,它的目的其实就是和我们上面定义的那个类作用是类似的,你可以传入一个时间代表着可以允许数据延迟到来的时间是多长。该类内部实现如下:
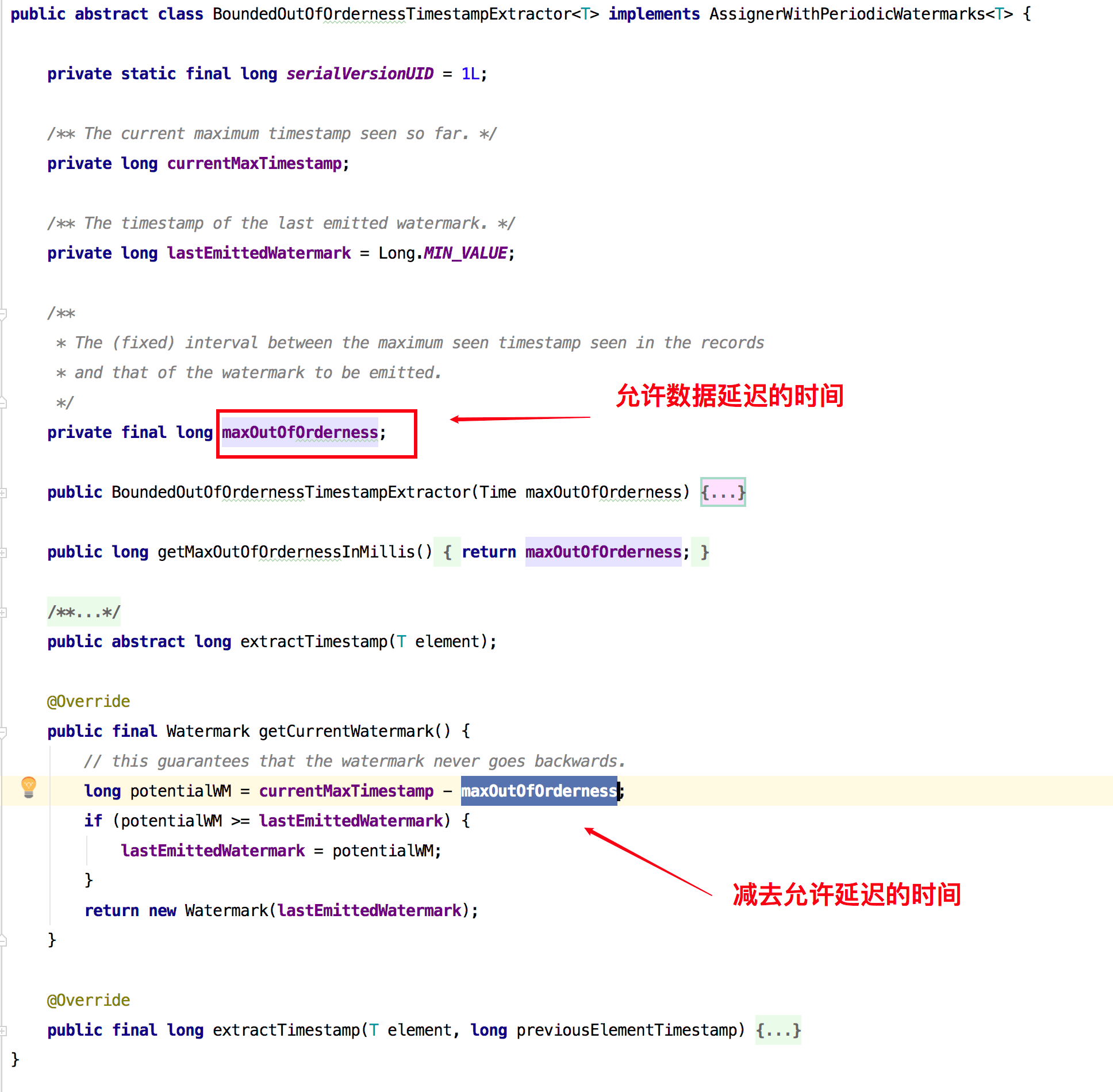
你可以像下面一样使用该类来分配时间和生成水印:
//Time.seconds(10) 代表允许延迟的时间大小
dataStream.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<Event>(Time.seconds(10)) {
//重写 BoundedOutOfOrdernessTimestampExtractor 中的 extractTimestamp()抽象方法
@Override
public long extractTimestamp(Event event) {
return event.getTimestamp();
}
})
CustomWatermarkExtractor:这是一个自定义的周期性生成水印的类,在这个类里面的数据是 KafkaEvent。
AscendingTimestampExtractor:时间戳分配器和水印生成器,用于时间戳单调递增的数据流,如果数据流的时间戳不是单调递增,那么会有专门的处理方法,代码如下:
public final long extractTimestamp(T element, long elementPrevTimestamp) { final long newTimestamp = extractAscendingTimestamp(element); if (newTimestamp >= this.currentTimestamp) { this.currentTimestamp = new Timestamp; return newTimestamp; } else { violationHandler.handleViolation(newTimestamp, this.currentTimestamp); return newTimestamp; } }IngestionTimeExtractor:依赖于机器系统时间,它在 extractTimestamp 和 getCurrentWatermark 方法中是根据
System.currentTimeMillis()来获取时间的,而不是根据事件的时间,如果这个时间分配器是在数据源进 Flink 后分配的,那么这个时间就和 Ingestion Time 一致了,所以命名也取的就是叫 IngestionTimeExtractor。
注意 :
1、使用这种方式周期性生成水印的话,你可以通过 env.getConfig().setAutoWatermarkInterval(...);来设置生成水印的间隔(每隔 n 毫秒)。
2、通常建议在数据源(source)之后就进行生成水印,或者做些简单操作比如 filter/map/flatMap之后再生成水印,越早生成水印的效果会更好,也可以直接在数据源头就做生成水印。比如你可以在 source 源头类中的 run() 方法里面这样定义
@Override
public void run(SourceContext<MyType> ctx) throws Exception {
while (/* condition */) {
MyType next = getNext();
ctx.collectWithTimestamp(next, next.getEventTimestamp());
if (next.hasWatermarkTime()) {
ctx.emitWatermark(new Watermark(next.getWatermarkTime()));
}
}
}
# 每个 Kafka 分区的时间戳
当以 Kafka 来作为数据源的时候,通常每个 Kafka 分区的数据时间戳是递增的(事件是有序的),但是当你作业设置多个并行度的时候,Flink 去消费Kafka 数据流是并行的,那么并行的去消费 Kafka 分区的数据就会导致打乱原每个分区的数据时间戳的顺序。在这种情况下,你可以使用 Flink 中的Kafka-partition-aware 特性来生成水印,使用该特性后,水印会在 Kafka 消费端生成,然后每个 Kafka分区和每个分区上的水印最后的合并方式和水印在数据流 shuffle 过程中的合并方式一致。
如果事件时间戳严格按照每个 Kafka 分区升序,则可以使用前面提到的 AscendingTimestampExtractor水印生成器来为每个分区生成水印。下面代码教大家如何使用 per-Kafka-partition 来生成水印。
FlinkKafkaConsumer011<Event> kafkaSource = new FlinkKafkaConsumer011<>("zhisheng", schema, props);
kafkaSource.assignTimestampsAndWatermarks(new AscendingTimestampExtractor<Event>() {
@Override
public long extractAscendingTimestamp(Event event) {
return event.eventTimestamp();
}
});
DataStream<Event> stream = env.addSource(kafkaSource);
下图表示水印在 Kafka 分区后如何通过流数据流传播:
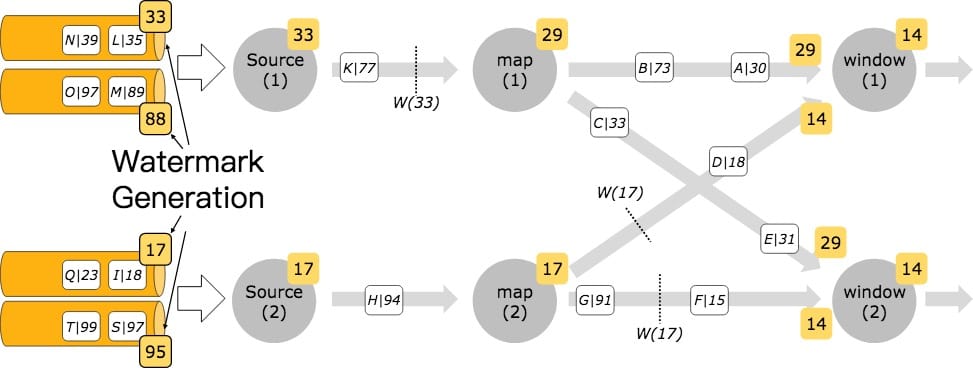
# Watermark 与 Window 结合来处理延迟数据
其实在上文中已经提到的一点是在设置 Periodic Watermark时,是允许提供一个参数,表示数据最大的延迟时间。其实这个值要结合自己的业务以及数据的情况来设置,如果该值设置的太小会导致数据因为网络或者其他的原因从而导致乱序或者延迟的数据太多,那么最后窗口触发的时候,可能窗口里面的数据量很少,那么这样计算的结果很可能误差会很大,对于有的场景(要求正确性比较高)是不太符合需求的。但是如果该值设置的太大,那么就会导致很多窗口一直在等待延迟的数据,从而一直不触发,这样首先就会导致数据的实时性降低,另外将这么多窗口的数据存在内存中,也会增加作业的内存消耗,从而可能会导致作业发生OOM 的问题。
综上建议:
- 合理设置允许数据最大延迟时间
- 不太依赖事件时间的场景就不要设置时间策略为 EventTime
# 延迟数据该如何处理(三种方法)
# 丢弃(默认)
在 Flink 中,对这么延迟数据的默认处理方式是丢弃。
# allowedLateness 再次指定允许数据延迟的时间
allowedLateness 表示允许数据延迟的时间,这个方法是在 WindowedStream中的,用来设置允许窗口数据延迟的时间,超过这个时间的元素就会被丢弃,这个的默认值是 0,该设置仅针对于以事件时间开的窗口,它的源码如下:
public WindowedStream<T, K, W> allowedLateness(Time lateness) {
final long millis = lateness.toMilliseconds();
checkArgument(millis >= 0, "The allowed lateness cannot be negative.");
this.allowedLateness = millis;
return this;
}
之前有多个小伙伴问过我 Watermark 中允许的数据延迟和这个数据延迟的区别是啥?我的回复是该允许延迟的时间是在 Watermark允许延迟的基础上增加的时间。那么具体该如何使用 allowedLateness 呢。
dataStream.assignTimestampsAndWatermarks(new TestWatermarkAssigner())
.keyBy(new TestKeySelector())
.timeWindow(Time.milliseconds(1), Time.milliseconds(1))
.allowedLateness(Time.milliseconds(2)) //表示允许再次延迟 2 毫秒
.apply(new WindowFunction<Integer, String, Integer, TimeWindow>() {
//计算逻辑
});
# sideOutputLateData 收集迟到的数据
sideOutputLateData 这个方法同样是 WindowedStream 中的方法,该方法会将延迟的数据发送到给定 OutputTag 的side output 中去,然后你可以通过 SingleOutputStreamOperator.getSideOutput(OutputTag)来获取这些延迟的数据。具体的操作方法如下:
//定义 OutputTag
OutputTag<Integer> lateDataTag = new OutputTag<Integer>("late"){};
SingleOutputStreamOperator<String> windowOperator = dataStream
.assignTimestampsAndWatermarks(new TestWatermarkAssigner())
.keyBy(new TestKeySelector())
.timeWindow(Time.milliseconds(1), Time.milliseconds(1))
.allowedLateness(Time.milliseconds(2))
.sideOutputLateData(lateDataTag) //指定 OutputTag
.apply(new WindowFunction<Integer, String, Integer, TimeWindow>() {
//计算逻辑
});
windowOperator.addSink(resultSink);
//通过指定的 OutputTag 从 Side Output 中获取到延迟的数据之后,你可以通过 addSink() 方法存储下来,这样可以方便你后面去排查哪些数据是延迟的。
windowOperator.getSideOutput(lateDataTag)
.addSink(lateResultSink);
# 小结与反思
本节讲了 Watermark 的概念,并讲解了 Flink 中自带的 Watermark,然后还教大家如何设置 Watermark 以及如何自定义Watermark,最后通过结合 Window 与 Watermark 去处理延迟数据,还讲解了三种常见的处理延迟数据的方法。
关于 Watermark 你有遇到什么问题吗?对于延迟数据你通常是怎么处理的?
本节相关的代码地址:[Watermark](https://github.com/zhisheng17/flink- learning/tree/master/flink-learning- examples/src/main/java/com/zhisheng/examples/streaming/watermark)