# FlinkParallelism和Slot深度理解
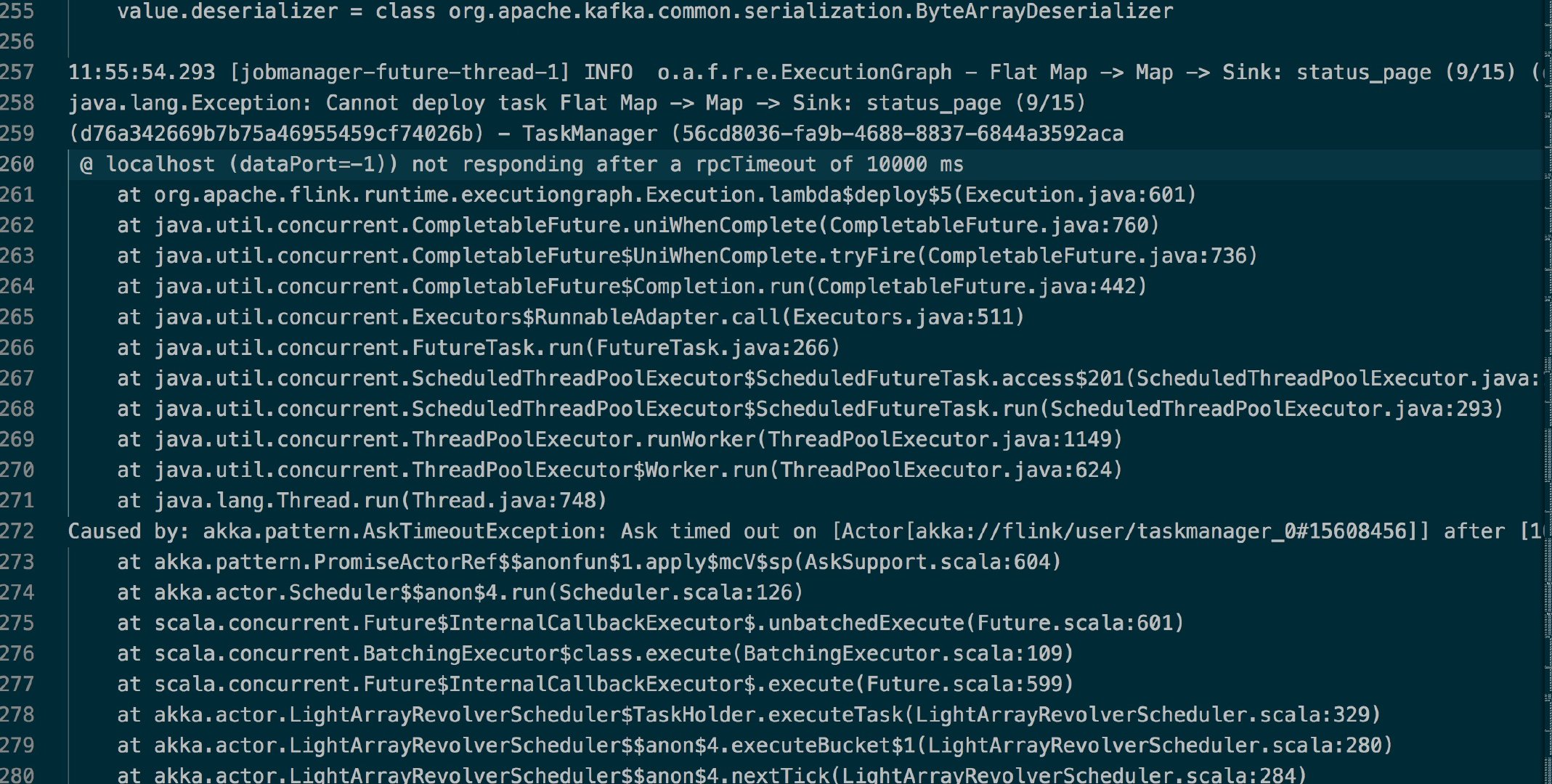
相信使用过 Flink 的你或多或少遇到过下面这个问题(笔者自己的项目曾经也出现过这样的问题),错误信息如下:
Caused by: akka.pattern.AskTimeoutException:
Ask timed out on [Actor[akka://flink/user/taskmanager_0#15608456]] after [10000 ms].
Sender[null] sent message of type "org.apache.flink.runtime.rpc.messages.LocalRpcInvocation".
 跟着这问题在 Flink 的 Issue
列表里看到了一个类似的问题:https://issues.apache.org/jira/browse/FLINK-9056https://issues.apache.org/jira/browse/FLINK-9056
,看下面的评论意思大概就是 TaskManager 的 Slot 数量不足导致的 Job 提交失败,在 Flink 1.63 中已经修复了,变成抛出异常了。
跟着这问题在 Flink 的 Issue
列表里看到了一个类似的问题:https://issues.apache.org/jira/browse/FLINK-9056https://issues.apache.org/jira/browse/FLINK-9056
,看下面的评论意思大概就是 TaskManager 的 Slot 数量不足导致的 Job 提交失败,在 Flink 1.63 中已经修复了,变成抛出异常了。
 竟然知道了是因为 Slot 不足的原因了,那么我们就要先了解下 Slot 是什么呢?不过再了解 Slot 之前这里先介绍下 parallelism。
竟然知道了是因为 Slot 不足的原因了,那么我们就要先了解下 Slot 是什么呢?不过再了解 Slot 之前这里先介绍下 parallelism。
# 什么是 Parallelism?
 如翻译这样,parallelism 是并行的意思,在 Flink 里面代表每个算子的并行度,适当的提高并行度可以大大提高 Job 的执行效率,比如你的
Job 消费 Kafka 数据过慢,适当调大可能就消费正常了。
如翻译这样,parallelism 是并行的意思,在 Flink 里面代表每个算子的并行度,适当的提高并行度可以大大提高 Job 的执行效率,比如你的
Job 消费 Kafka 数据过慢,适当调大可能就消费正常了。
那么在 Flink 中怎么设置并行度呢?
# 如何设置 Parallelism?
 如上图,在 Flink 配置文件中可以看到默认并行度是 1。
如上图,在 Flink 配置文件中可以看到默认并行度是 1。
cat flink-conf.yaml | grep parallelism
# The parallelism used for programs that did not specify and other parallelism.
parallelism.default: 1
所以如果在你的 Flink Job 里面不设置任何 parallelism 的话,那么它也会有一个默认的 parallelism(默认为 1),那也意味着可以修改这个配置文件的默认并行度来提高 Job 的执行效率。如果是使用命令行启动你的 Flink Job,那么你也可以这样设置并行度(使用 -p n 参数):
./bin/flink run -p 10 /Users/zhisheng/word-count.jar
你也可以通过 env.setParallelism(n) 来设置整个程序的并行度:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(10);
注意:这样设置的并行度是整个程序的并行度,那么后面如果每个算子不单独设置并行度覆盖的话,那么后面每个算子的并行度就都是以这里设置的并行度为准了。如何给每个算子单独设置并行度呢?
data.keyBy(new xxxKey())
.flatMap(new XxxFlatMapFunction()).setParallelism(5)
.map(new XxxMapFunction).setParallelism(5)
.addSink(new XxxSink()).setParallelism(1)
如上就是给每个算子单独设置并行度,这样的话,就算程序设置了 env.setParallelism(10)
也是会被覆盖的。这也说明优先级是:算子设置并行度 > env 设置并行度 > 配置文件默认并行度。
并行度讲到这里应该都懂了,下面就继续讲什么是 Slot?
# 什么是 Slot?
其实 Slot 的概念在 1.2 节中已经提及到,这里再细讲一点。
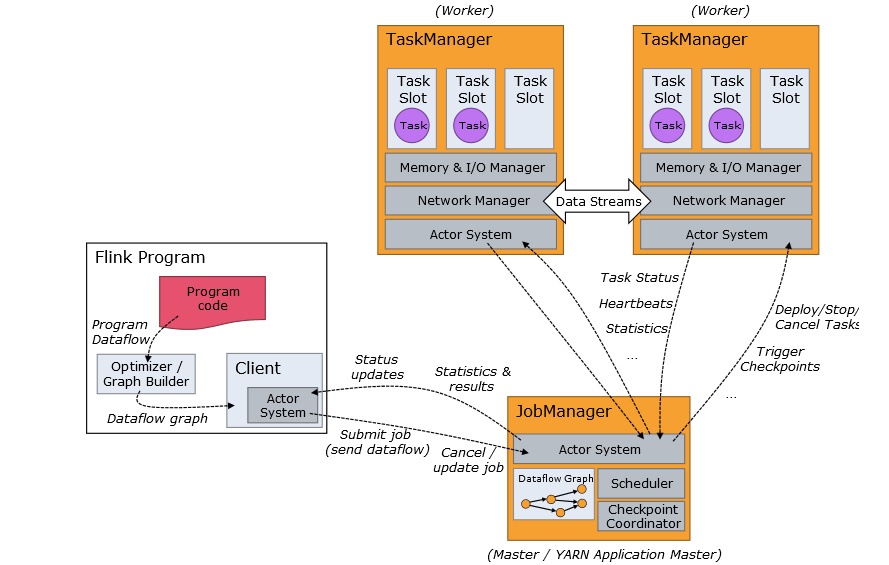 图中 TaskManager 是从 JobManager 处接收需要部署的 Task,任务能配置的最大并行度由 TaskManager 上可用的 Slot
决定。每个任务代表分配给任务槽的一组资源,Slot 在 Flink 里面可以认为是资源组,Flink 将每个任务分成子任务并且将这些子任务分配到 Slot
中,这样就可以并行的执行程序。
图中 TaskManager 是从 JobManager 处接收需要部署的 Task,任务能配置的最大并行度由 TaskManager 上可用的 Slot
决定。每个任务代表分配给任务槽的一组资源,Slot 在 Flink 里面可以认为是资源组,Flink 将每个任务分成子任务并且将这些子任务分配到 Slot
中,这样就可以并行的执行程序。
例如,如果 TaskManager 有四个 Slot,那么它将为每个 Slot 分配 25% 的内存。 可以在一个 Slot 中运行一个或多个线程。 同一 Slot 中的线程共享相同的 JVM。 同一 JVM 中的任务共享 TCP 连接和心跳消息。TaskManager 的一个 Slot 代表一个可用线程,该线程具有固定的内存,注意 Slot 只对内存隔离,没有对 CPU 隔离。默认情况下,Flink 允许子任务共享 Slot,即使它们是不同 Task 的 subtask,只要它们来自相同的 Job,这种共享模式可以大大的提高资源利用率。拿下面的图片来讲解会更好些。
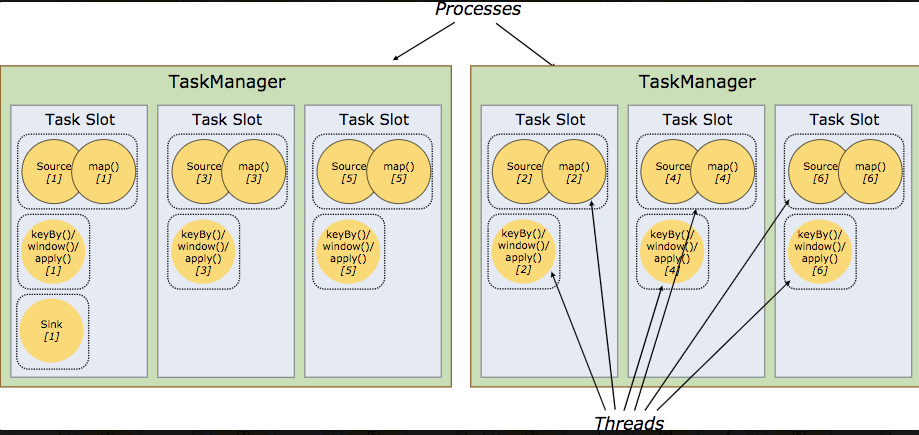 上面图片中有两个 TaskManager,每个 TaskManager 有三个 Slot,这样我们的算子最大并行度那么就可以达到 6 个,在同一个 Slot
里面可以执行 1 至多个子任务。那么再看上面的图片,source/map/keyby/window/apply 算子最大可以设置 6 个并行度,sink
只设置了 1 个并行度。
上面图片中有两个 TaskManager,每个 TaskManager 有三个 Slot,这样我们的算子最大并行度那么就可以达到 6 个,在同一个 Slot
里面可以执行 1 至多个子任务。那么再看上面的图片,source/map/keyby/window/apply 算子最大可以设置 6 个并行度,sink
只设置了 1 个并行度。
每个 Flink TaskManager 在集群中提供 Slot,Slot 的数量通常与每个 TaskManager 的可用 CPU 内核数成比例(一般情况下 Slot 个数是每个 TaskManager 的 CPU 核数)。Flink 配置文件中设置的一个 TaskManager 默认的 Slot 是 1。
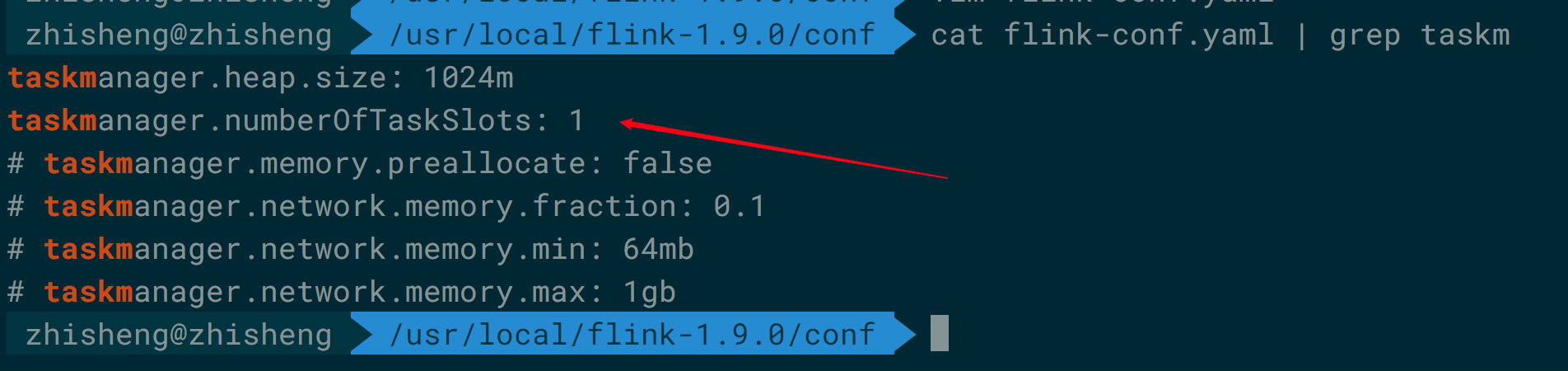
taskmanager.numberOfTaskSlots: 1 该参数可以根据实际情况做一定的修改。
# Slot 和 Parallelism 的关系
下面用几张图片来更加深刻的理解下 Slot 和 Parallelism,并清楚它们之间的关系。
1、Slot 是指 TaskManager 最大能并发执行的能力
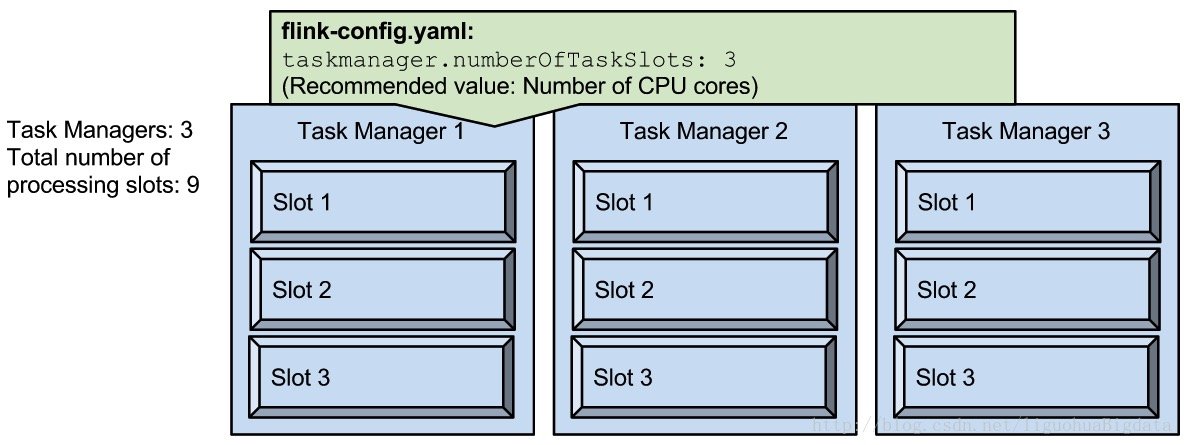 如上图,如果设置的单个 TaskManager 的 Slot 个数为 3,启动 3 个 TaskManager 后,那么就一共有 9 个 Slot。
如上图,如果设置的单个 TaskManager 的 Slot 个数为 3,启动 3 个 TaskManager 后,那么就一共有 9 个 Slot。
2、parallelism 是指 TaskManager 实际使用的并发能力
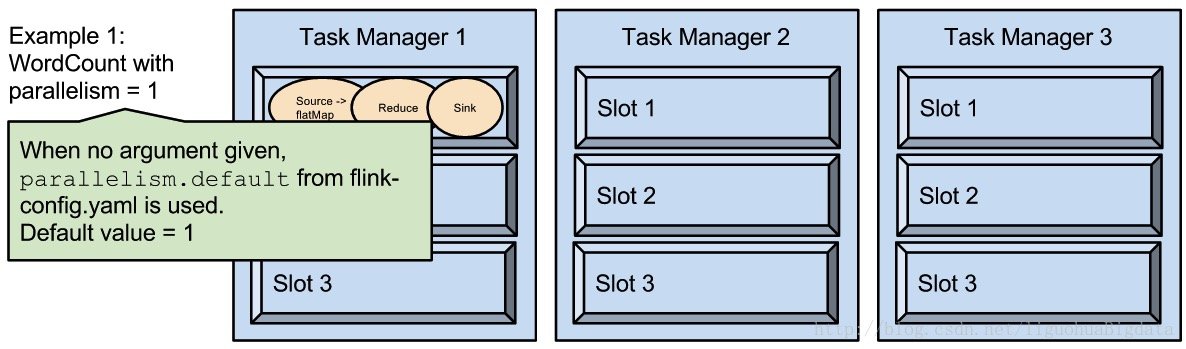 运行程序默认的并行度为 1,9 个 Slot 只用了 1 个,有 8 个处于空闲,设置合适的并行度才能提高 Job 计算效率。
运行程序默认的并行度为 1,9 个 Slot 只用了 1 个,有 8 个处于空闲,设置合适的并行度才能提高 Job 计算效率。
3、parallelism 是可配置、可指定的
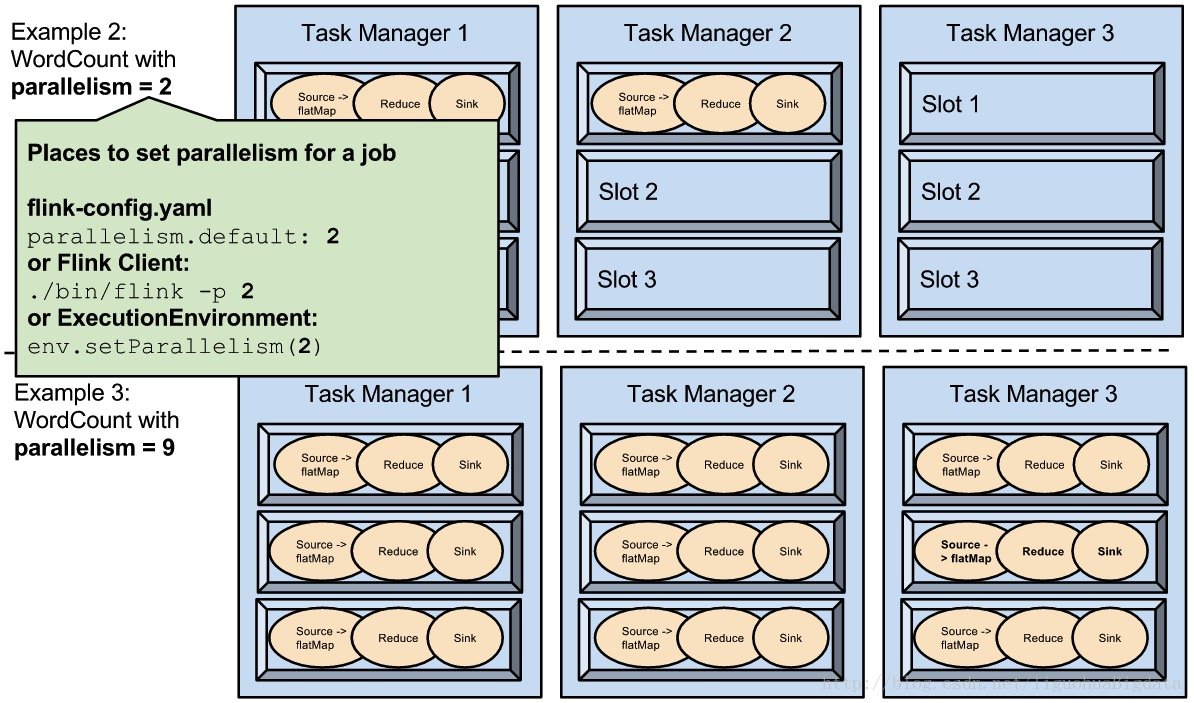 上图中 example2 每个算子设置的并行度是 2, example3 每个算子设置的并行度是 9。
上图中 example2 每个算子设置的并行度是 2, example3 每个算子设置的并行度是 9。
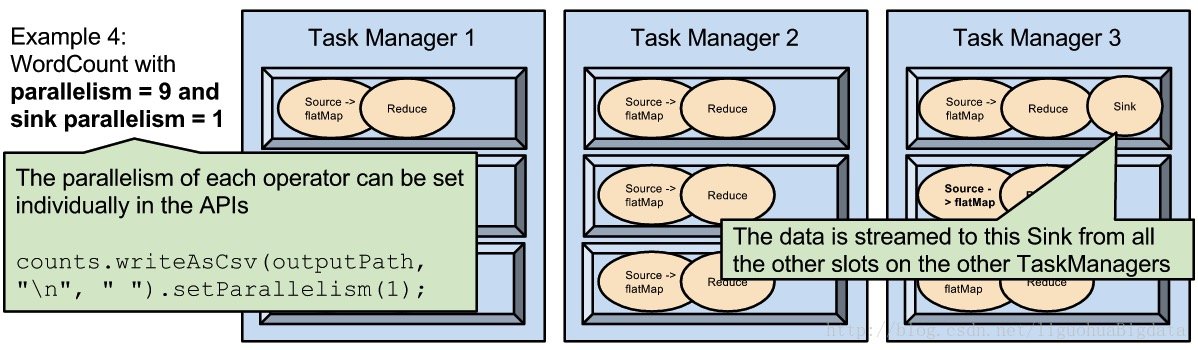 example4 除了 sink 是设置的并行度为 1,其他算子设置的并行度都是 9。
example4 除了 sink 是设置的并行度为 1,其他算子设置的并行度都是 9。
# 可能会遇到 Slot 和 Parallelism 的问题
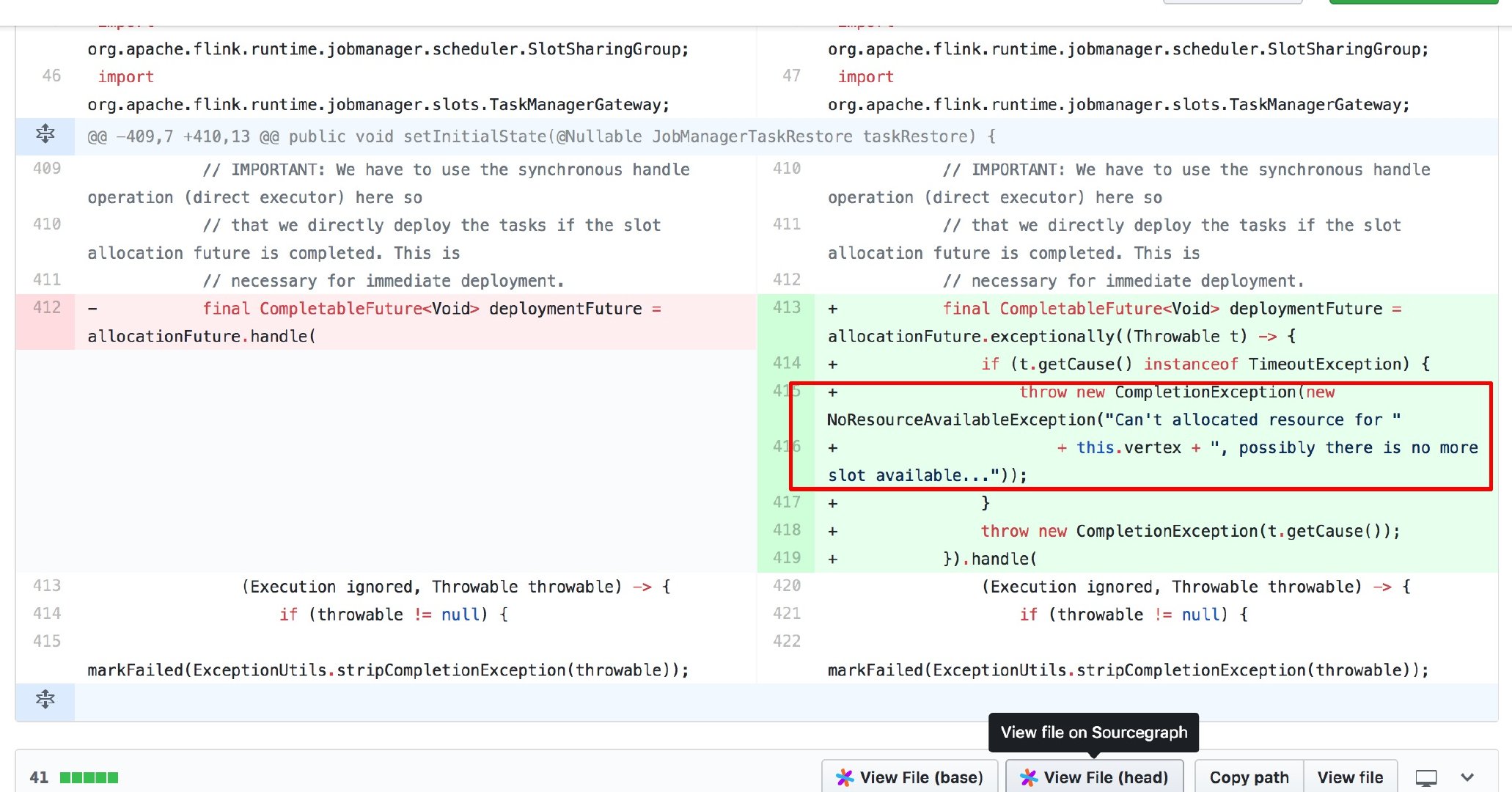
好了,既然 Slot 和 Parallelism 大家都了解了,现在再来看前面提到的问题(Slot 资源不够),这时问题的答案就已经很明显了,就是程序设置的并行度超过了 TaskManager 可用的 Slot 数量,所以程序一直在等待资源调度并超过了一定的时间(该时间可配置),所以才会抛出该异常错误。
还原代码查找根因,当时笔者的程序设置的并行度是 30(设置 30 是因为 Kafka 分区数有 30 个,想着一个并行度去消费一个分区的数据),没曾想到 Flink 的 Slot 不够,后面了解到该情况后就降低并行度到 10,这样就意味着一个并行度要去消费 3 个 Kafka 分区的数据,调整并行度后速度还是跟的上并且再也没有抛出该异常了。注意如果调小并行度后消费速度过慢,那可以再试试调大些试试,如果还是这样,那么只能增加 TaskManager 的个数从而间接性的增加 Slot 个数来解决该问题了。
该问题对于刚接触 Flink 的来说是比较容易遇见的,如果你对 Slot 和 Parallelism 不了解的话,那么就会感觉很苦恼,相信你看完这篇文章后就能够豁然开朗了。另外可能还会有各种各样的并行度设置的问题,比如:
- 程序某个算子执行了比较复杂的操作,延迟很久,导致该算子处理数据特别慢,那么可以考虑给该算子处增加并行度
- Flink Source 处的并行度超过 Kafka 分区数,因为 Flink 的一个并行度可以处理一至多个分区的数据,如果并行度多于 Kafka 的分区数,那么就会造成有的并行度空闲,浪费资源,建议最多 Flink Source 端的并行度不要超过 Kafka 分区数
总之,要做到既让 Job 能够及时消费数据,又能够节省资源,需要理解并合理设置并行度和 Slot。
# 小结与反思
本节通过一个生产错误案例来分析作业的并行度资源设置的问题,教大家如何设置并行度,接着讲解了 Slot 的概念和与并行度之间的关系,最后讲了下可能会遇到的问题。
关于并行度的设置你还有什么疑问吗?Slot 的配置技巧你是否掌握了呢?是否遇到过并行度设置的问题?