# 如何使用FlinkConnectors——HBase?
# 准备环境和依赖
# HBase 安装
如果是苹果系统,可以使用 HomeBrew 命令安装:
brew install hbase
HBase 最终会安装在路径 /usr/local/Cellar/hbase/ 下面,安装版本不同,文件名也不同。
# 配置 HBase
打开 libexec/conf/hbase-env.sh 修改里面的 JAVA_HOME:
# The java implementation to use. Java 1.7+ required.
export JAVA_HOME="/Library/Java/JavaVirtualMachines/jdk1.8.0_152.jdk/Contents/Home"
根据你自己的 JAVA_HOME 来配置这个变量。
打开 libexec/conf/hbase-site.xml 配置 HBase 文件存储目录:
<configuration>
<property>
<name>hbase.rootdir</name>
<!-- 配置HBase存储文件的目录 -->
<value>file:///usr/local/var/hbase</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<!-- 配置HBase存储内建zookeeper文件的目录 -->
<value>/usr/local/var/zookeeper</value>
</property>
<property>
<name>hbase.zookeeper.dns.interface</name>
<value>lo0</value>
</property>
<property>
<name>hbase.regionserver.dns.interface</name>
<value>lo0</value>
</property>
<property>
<name>hbase.master.dns.interface</name>
<value>lo0</value>
</property>
</configuration>
# 运行 HBase
执行启动的命令:
./bin/start-hbase.sh
执行后打印出来的日志如:
starting master, logging to /usr/local/var/log/hbase/hbase-zhisheng-master-zhisheng.out
# 验证是否安装成功
使用 jps 命令:
zhisheng@zhisheng /usr/local/Cellar/hbase/1.2.9/libexec jps
91302 HMaster
62535 RemoteMavenServer
1100
91471 Jps
出现 HMaster 说明安装运行成功。
# 启动 HBase Shell
执行下面命令:
./bin/hbase shell

# 停止 HBase
执行下面的命令:
./bin/stop-hbase.sh

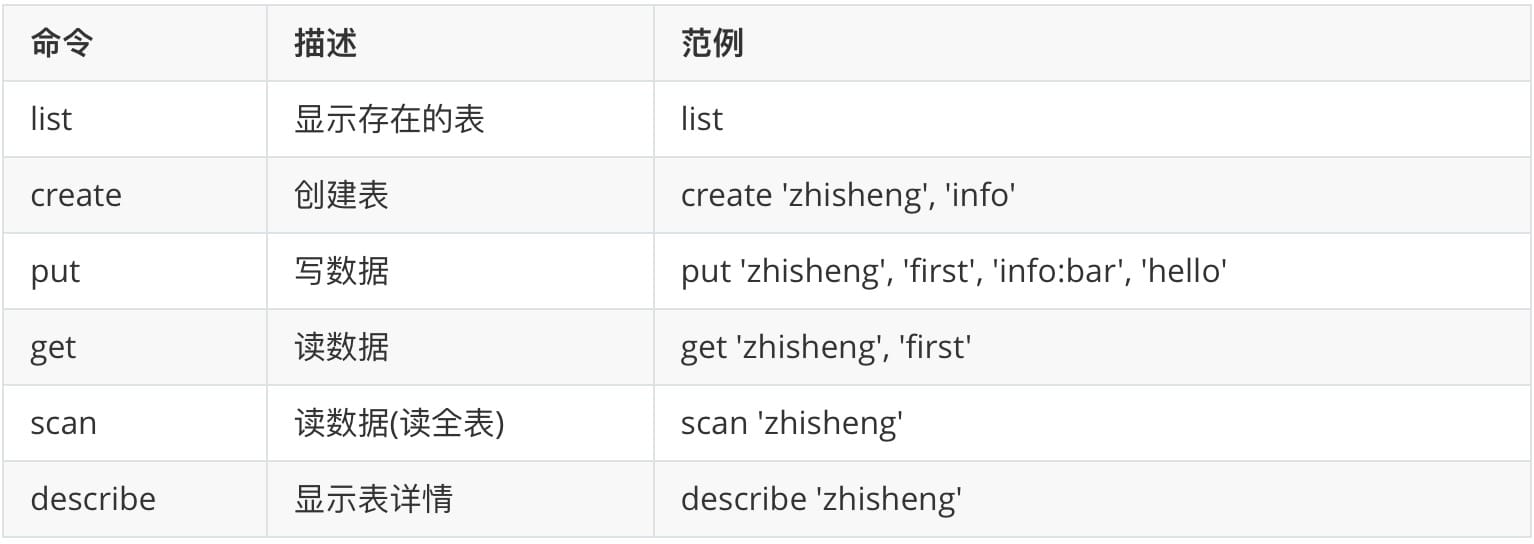
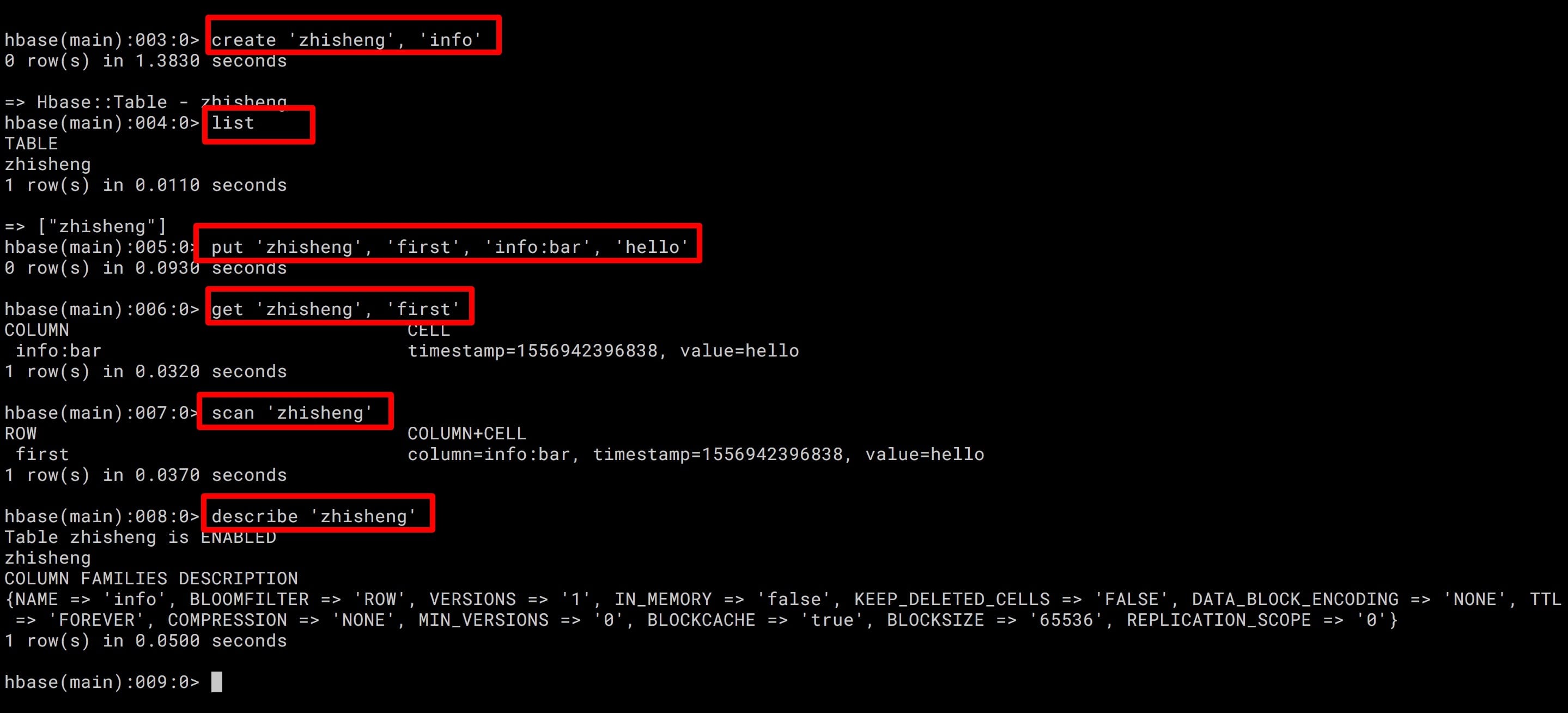
# HBase 常用命令
HBase 中常用的命令有:list(列出已存在的表)、create(创建表)、put(写数据)、get(读数据)、scan(读数据,读全表)、describe(显示表详情)
# 添加依赖
在 pom.xml 中添加 HBase 相关的依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-hbase_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.4</version>
</dependency>
Flink HBase Connector 中,HBase 不仅可以作为数据源,也还可以写入数据到 HBase 中去,我们先来看看如何从 HBase 中读取数据。
# Flink 使用 TableInputFormat 读取 HBase 批量数据
# 准备数据
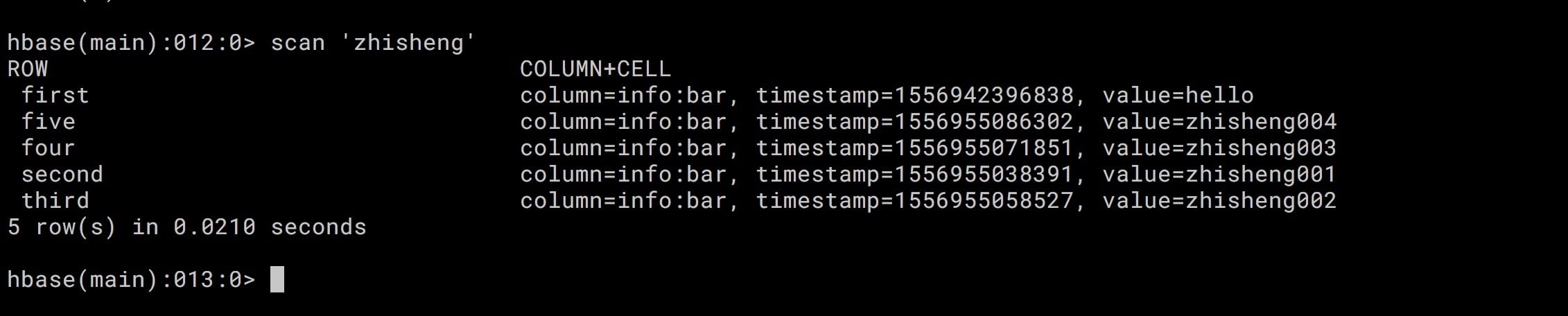
先往 HBase 中插入五条数据如下:
put 'zhisheng', 'first', 'info:bar', 'hello'
put 'zhisheng', 'second', 'info:bar', 'zhisheng001'
put 'zhisheng', 'third', 'info:bar', 'zhisheng002'
put 'zhisheng', 'four', 'info:bar', 'zhisheng003'
put 'zhisheng', 'five', 'info:bar', 'zhisheng004'
scan 整个 zhisheng 表的话,有五条数据:
# Flink Job 代码
/**
* Desc: 读取 HBase 数据
*/
public class HBaseReadMain {
//表名
public static final String HBASE_TABLE_NAME = "zhisheng";
// 列族
static final byte[] INFO = "info".getBytes(ConfigConstants.DEFAULT_CHARSET);
//列名
static final byte[] BAR = "bar".getBytes(ConfigConstants.DEFAULT_CHARSET);
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.createInput(new TableInputFormat<Tuple2<String, String>>() {
private Tuple2<String, String> reuse = new Tuple2<String, String>();
@Override
protected Scan getScanner() {
Scan scan = new Scan();
scan.addColumn(INFO, BAR);
return scan;
}
@Override
protected String getTableName() {
return HBASE_TABLE_NAME;
}
@Override
protected Tuple2<String, String> mapResultToTuple(Result result) {
String key = Bytes.toString(result.getRow());
String val = Bytes.toString(result.getValue(INFO, BAR));
reuse.setField(key, 0);
reuse.setField(val, 1);
return reuse;
}
}).filter(new FilterFunction<Tuple2<String, String>>() {
@Override
public boolean filter(Tuple2<String, String> value) throws Exception {
return value.f1.startsWith("zhisheng");
}
}).print();
}
}
上面代码中将 HBase 中的读取全部读取出来后然后过滤以 zhisheng 开头的 value 数据。读取结果:
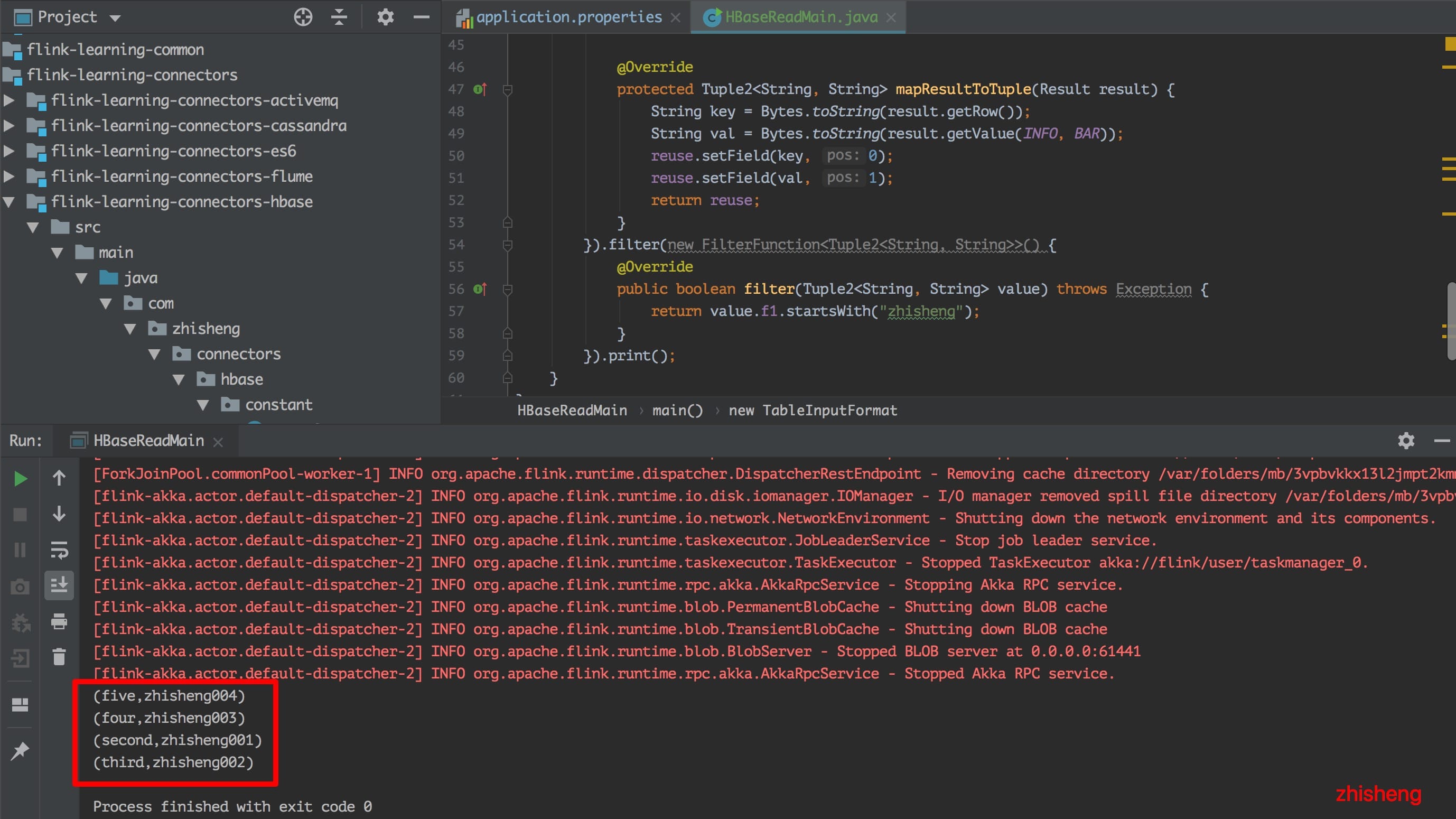 可以看到输出的结果中已经将以
可以看到输出的结果中已经将以 zhisheng 开头的四条数据都打印出来了。
# Flink 使用 TableOutputFormat 向 HBase 写入数据
# 添加依赖
在 pom.xml 中添加依赖:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-hadoop-compatibility_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
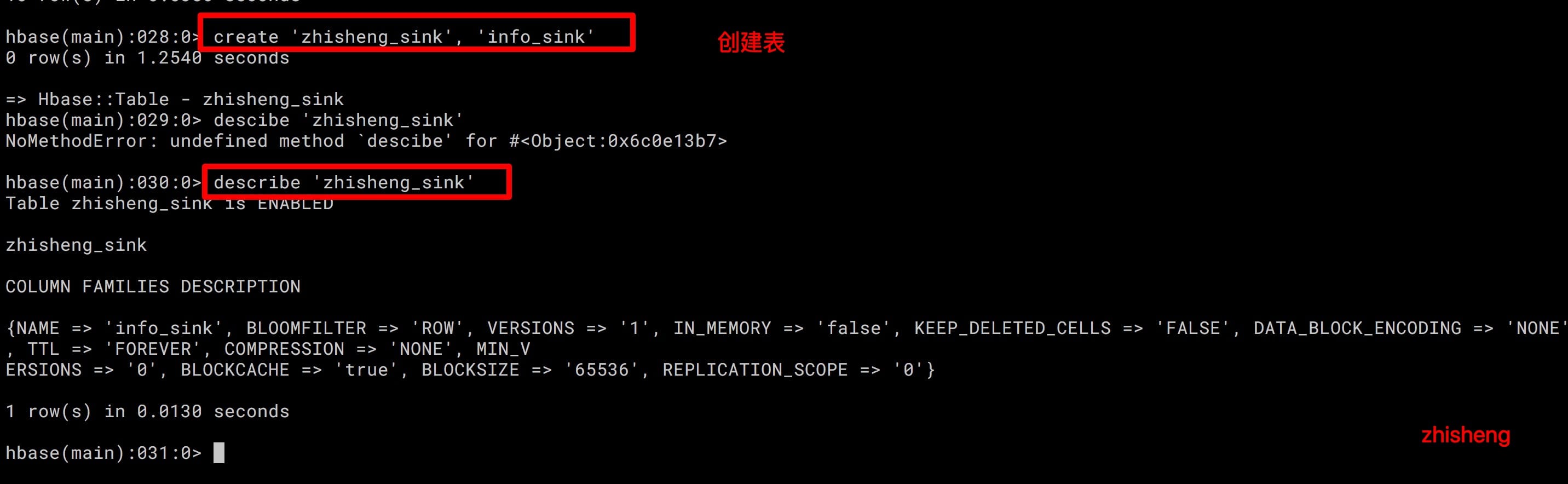
要在 HBase 中提交创建 zhisheng_sink 表,并且 Column 为 info_sink
(如果先运行程序的话是会报错说该表不存在的):
create 'zhisheng_sink', 'info_sink'
# Flink Job 代码
接着写 Flink Job 的代码,这里我们将 WordCount 的结果 KV 数据写入到 HBase 中去,代码如下:
/**
* Desc: 写入数据到 HBase
*/
public class HBaseWriteMain {
//表名
public static final String HBASE_TABLE_NAME = "zhisheng_sink";
// 列族
static final byte[] INFO = "info_sink".getBytes(ConfigConstants.DEFAULT_CHARSET);
//列名
static final byte[] BAR = "bar_sink".getBytes(ConfigConstants.DEFAULT_CHARSET);
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
Job job = Job.getInstance();
job.getConfiguration().set(TableOutputFormat.OUTPUT_TABLE, HBASE_TABLE_NAME);
env.fromElements(WORDS)
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] splits = value.toLowerCase().split("\\W+");
for (String split : splits) {
if (split.length() > 0) {
out.collect(new Tuple2<>(split, 1));
}
}
}
})
.groupBy(0)
.sum(1)
.map(new RichMapFunction<Tuple2<String, Integer>, Tuple2<Text, Mutation>>() {
private transient Tuple2<Text, Mutation> reuse;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
reuse = new Tuple2<Text, Mutation>();
}
@Override
public Tuple2<Text, Mutation> map(Tuple2<String, Integer> value) throws Exception {
reuse.f0 = new Text(value.f0);
Put put = new Put(value.f0.getBytes(ConfigConstants.DEFAULT_CHARSET));
put.addColumn(INFO, BAR, Bytes.toBytes(value.f1.toString()));
reuse.f1 = put;
return reuse;
}
}).output(new HadoopOutputFormat<Text, Mutation>(new TableOutputFormat<Text>(), job));
env.execute("Flink Connector HBase sink Example");
}
private static final String[] WORDS = new String[]{
"To be, or not to be,--that is the question:--",
"The fair is be in that orisons"
};
}
运行该 Job 的话,然后再用 HBase shell 命令去验证数据是否插入成功了:
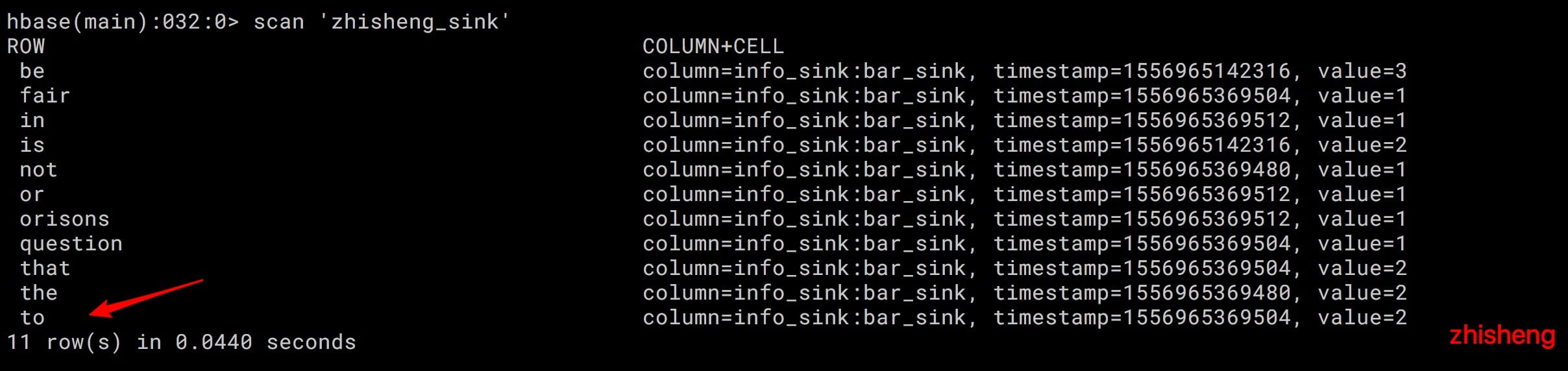 可以看见数据已经成功写入了 11 条,然后我们验证一下数据的条数是不是一样的呢?我们在上面的代码中将 map 和 output 算子给注释掉,然后用上
print 打印出来的话,结果如下:
可以看见数据已经成功写入了 11 条,然后我们验证一下数据的条数是不是一样的呢?我们在上面的代码中将 map 和 output 算子给注释掉,然后用上
print 打印出来的话,结果如下:
(be,3)
(is,2)
(in,1)
(or,1)
(orisons,1)
(not,1)
(the,2)
(fair,1)
(question,1)
(that,2)
(to,2)
统计的结果刚好也是 11 条数据,说明我们的写入过程中没有丢失数据。但是运行 Job 的话你会看到日志中报了一条这样的错误:
java.lang.IllegalArgumentException: Can not create a Path from a null string
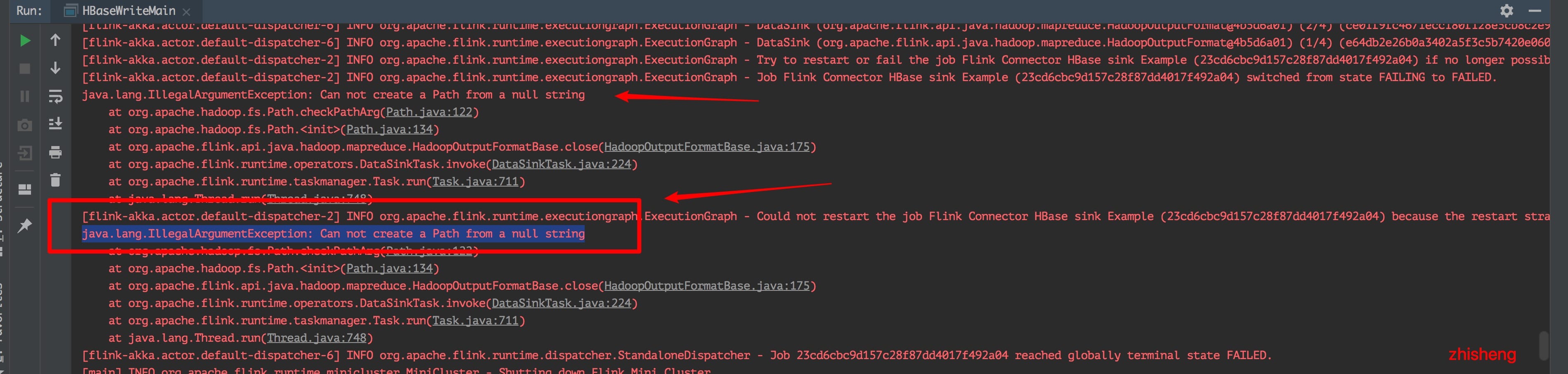 这个问题是因为:
这个问题是因为:
Path partitionsPath = new Path(conf.get("mapred.output.dir"), "partitions_" + UUID.randomUUID());
当配置项 mapred.output.dir 不存在时,conf.get() 将返回 null,从而导致上述异常。那么该如何解决这个问题呢?
需要在代码中或配置文件中添加配置项 mapred.output.dir。
比如在代码里加上这行代码:
job.getConfiguration().set("mapred.output.dir", "/tmp");
再次运行这个 Job 你就不会发现报错了。
# Flink 使用 HBaseOutputFormat 向 HBase 实时写入数据
从上面两个程序中你可以发现两个都是批程序(从 HBase 读取批量的数据、写入批量的数据进 HBase),下面跟着笔者来演示一个流程序。
# 读取数据
本来是打算演示从 Kafka 读取 String 类型的数据,但是为了好演示,我这里直接在代码里面造一些数据:
DataStream<String> dataStream = env.addSource(new SourceFunction<String>() {
private static final long serialVersionUID = 1L;
private volatile boolean isRunning = true;
@Override
public void run(SourceContext<String> out) throws Exception {
while (isRunning) {
out.collect(String.valueOf(Math.floor(Math.random() * 100)));
}
}
@Override
public void cancel() {
isRunning = false;
}
});
如果是读取 Kafka 数据请对应替换成:
env.addSource(new FlinkKafkaConsumer011<>(
parameterTool.get(METRICS_TOPIC), //这个 kafka topic 需要和上面的工具类的 topic 一致
new SimpleStringSchema(),
props));
# 写入数据
获取到数据后需要将数据写入到 HBase,这里使用的实现 HBaseOutputFormat 接口,然后重写里面的 configure、open、writeRecord、close 方法,代码如下:
private static class HBaseOutputFormat implements OutputFormat<String> {
private org.apache.hadoop.conf.Configuration configuration;
private Connection connection = null;
private String taskNumber = null;
private Table table = null;
private int rowNumber = 0;
@Override
public void configure(Configuration parameters) {
//设置配置信息
configuration = HBaseConfiguration.create();
configuration.set(HBASE_ZOOKEEPER_QUORUM, ExecutionEnvUtil.PARAMETER_TOOL.get(HBASE_ZOOKEEPER_QUORUM));
configuration.set(HBASE_ZOOKEEPER_PROPERTY_CLIENTPORT, ExecutionEnvUtil.PARAMETER_TOOL.get(HBASE_ZOOKEEPER_PROPERTY_CLIENTPORT));
configuration.set(HBASE_RPC_TIMEOUT, ExecutionEnvUtil.PARAMETER_TOOL.get(HBASE_RPC_TIMEOUT));
configuration.set(HBASE_CLIENT_OPERATION_TIMEOUT, ExecutionEnvUtil.PARAMETER_TOOL.get(HBASE_CLIENT_OPERATION_TIMEOUT));
configuration.set(HBASE_CLIENT_SCANNER_TIMEOUT_PERIOD, ExecutionEnvUtil.PARAMETER_TOOL.get(HBASE_CLIENT_SCANNER_TIMEOUT_PERIOD));
}
@Override
public void open(int taskNumber, int numTasks) throws IOException {
connection = ConnectionFactory.createConnection(configuration);
TableName tableName = TableName.valueOf(ExecutionEnvUtil.PARAMETER_TOOL.get(HBASE_TABLE_NAME));
Admin admin = connection.getAdmin();
if (!admin.tableExists(tableName)) { //检查是否有该表,如果没有,创建
log.info("==============不存在表 = {}", tableName);
admin.createTable(new HTableDescriptor(TableName.valueOf(ExecutionEnvUtil.PARAMETER_TOOL.get(HBASE_TABLE_NAME)))
.addFamily(new HColumnDescriptor(ExecutionEnvUtil.PARAMETER_TOOL.get(HBASE_COLUMN_NAME))));
}
table = connection.getTable(tableName);
this.taskNumber = String.valueOf(taskNumber);
}
@Override
public void writeRecord(String record) throws IOException {
Put put = new Put(Bytes.toBytes(taskNumber + rowNumber));
put.addColumn(Bytes.toBytes(ExecutionEnvUtil.PARAMETER_TOOL.get(HBASE_COLUMN_NAME)), Bytes.toBytes("zhisheng"),
Bytes.toBytes(String.valueOf(rowNumber)));
rowNumber++;
table.put(put);
}
@Override
public void close() throws IOException {
table.close();
connection.close();
}
}
# 配置文件
配置文件中的一些配置如下:
kafka.brokers=localhost:9092
kafka.group.id=zhisheng
kafka.zookeeper.connect=localhost:2181
metrics.topic=zhisheng
stream.parallelism=4
stream.sink.parallelism=4
stream.default.parallelism=4
stream.checkpoint.interval=1000
stream.checkpoint.enable=false
# HBase
hbase.zookeeper.quorum=localhost:2181
hbase.client.retries.number=1
hbase.master.info.port=-1
hbase.zookeeper.property.clientPort=2081
hbase.rpc.timeout=30000
hbase.client.operation.timeout=30000
hbase.client.scanner.timeout.period=30000
# HBase table name
hbase.table.name=zhisheng_stream
hbase.column.name=info_stream
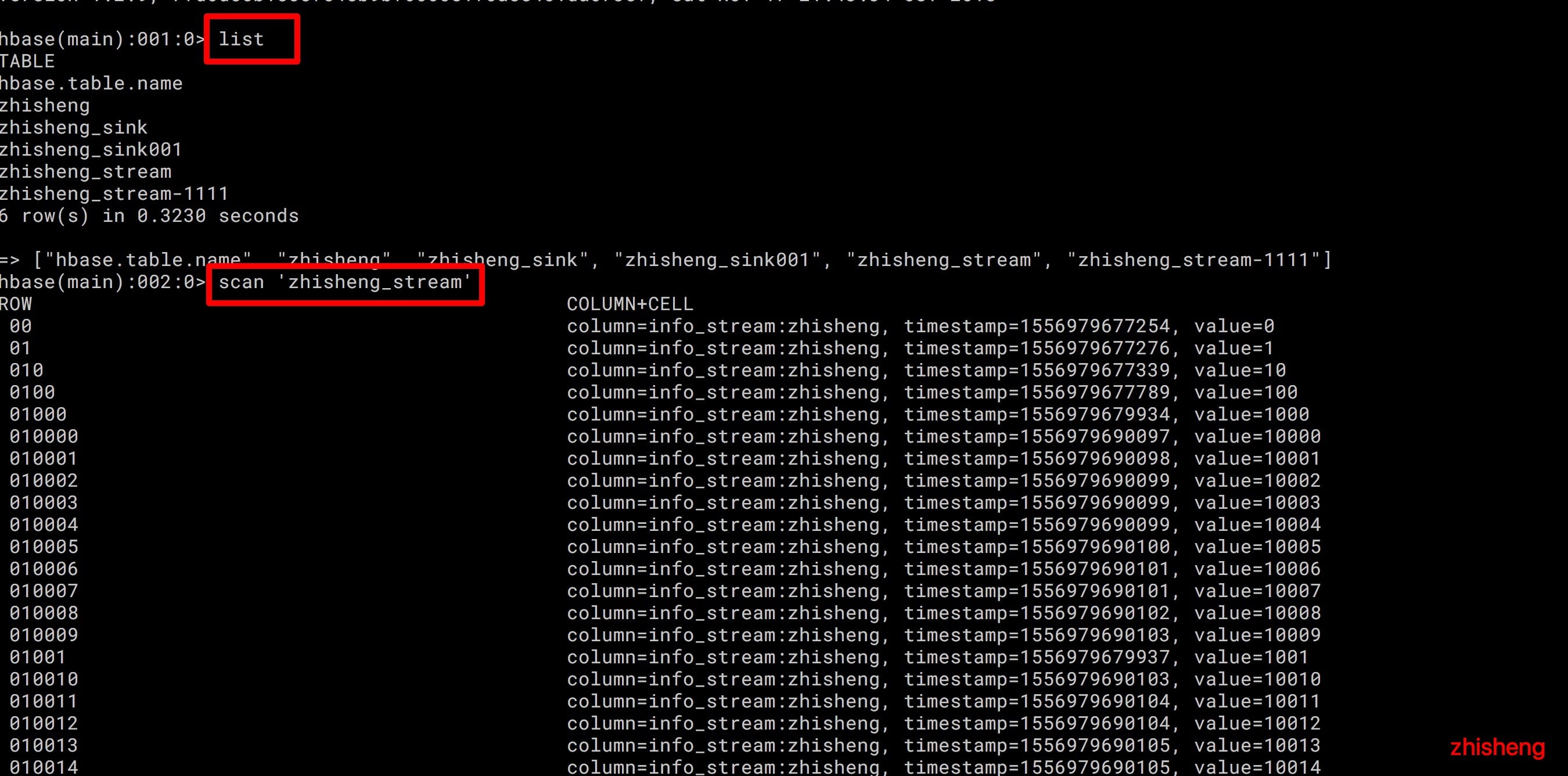
# 项目运行及验证
运行项目后然后你再去用 HBase shell 命令查看你会发现该 zhisheng_stream 表之前没有建立,现在建立了,再通过 scan
命令查看的话,你会发现数据一直在更新,不断增加数据条数。
# 小结与反思
本节开始讲解了 HBase 相关的环境安装和基础命令,接着讲解了如何去读取 HBase 数据和写入数据到 HBase。
本节涉及的完整代码地址在:<https://github.com/zhisheng17/flink-learning/tree/master/flink- learning-connectors/flink-learning-connectors-hbase>