# 如何使用FlinkConnectors——Redis?
在生产环境中,通常会将一些计算后的数据存储在 Redis 中,以供第三方的应用去 Redis 查找对应的数据,至于 Redis 的特性笔者不会在本节做过多的讲解。
# 安装 Redis
# 下载安装
先在 https://redis.io/download (opens new window) 下载到 Redis。
wget http://download.redis.io/releases/redis-5.0.4.tar.gz
tar xzf redis-5.0.4.tar.gz
cd redis-5.0.4
make
# 通过 HomeBrew 安装
brew install redis
如果需要后台运行 Redis 服务,使用命令:
brew services start redis
要运行命令,可以直接到 /usr/local/bin 目录下,有:
redis-server
redis-cli
两个命令,执行 redis-server 可以打开服务端:
 然后另外开一个终端,运行
然后另外开一个终端,运行 redis-cli 命令可以运行客户端:
# 准备商品数据发送至 Kafka
这里我打算将从 Kafka 读取到所有到商品的信息,然后将商品信息中的 商品ID 和 商品价格 提取出来,然后写入到 Redis 中,供第三方服务根据商品 ID 查询到其对应的商品价格。
首先定义我们的商品类 (其中 id 和 price 字段是我们最后要提取的)为:
ProductEvent.java
/**
* Desc: 商品
* blog:http://www.54tianzhisheng.cn/
* 微信公众号:zhisheng
*/
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class ProductEvent {
/**
* Product Id
*/
private Long id;
/**
* Product 类目 Id
*/
private Long categoryId;
/**
* Product 编码
*/
private String code;
/**
* Product 店铺 Id
*/
private Long shopId;
/**
* Product 店铺 name
*/
private String shopName;
/**
* Product 品牌 Id
*/
private Long brandId;
/**
* Product 品牌 name
*/
private String brandName;
/**
* Product name
*/
private String name;
/**
* Product 图片地址
*/
private String imageUrl;
/**
* Product 状态(1(上架),-1(下架),-2(冻结),-3(删除))
*/
private int status;
/**
* Product 类型
*/
private int type;
/**
* Product 标签
*/
private List<String> tags;
/**
* Product 价格(以分为单位)
*/
private Long price;
}
然后写个工具类不断的模拟商品数据发往 Kafka,工具类 ProductUtil.java :
public class ProductUtil {
public static final String broker_list = "localhost:9092";
public static final String topic = "zhisheng"; //kafka topic 需要和 flink 程序用同一个 topic
public static final Random random = new Random();
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", broker_list);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer producer = new KafkaProducer<String, String>(props);
for (int i = 1; i <= 10000; i++) {
ProductEvent product = ProductEvent.builder().id((long) i) //商品的 id
.name("product" + i) //商品 name
.price(random.nextLong() / 10000000000000L) //商品价格(以分为单位)
.code("code" + i).build(); //商品编码
ProducerRecord record = new ProducerRecord<String, String>(topic, null, null, GsonUtil.toJson(product));
producer.send(record);
System.out.println("发送数据: " + GsonUtil.toJson(product));
}
producer.flush();
}
}
# Flink 消费 Kafka 中商品数据
我们需要在 Flink 中消费 Kafka 数据,然后将商品中的两个数据(商品 id 和 price)取出来。先来看下这段 Flink Job 代码:
public class Main {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
ParameterTool parameterTool = ExecutionEnvUtil.PARAMETER_TOOL;
Properties props = KafkaConfigUtil.buildKafkaProps(parameterTool);
SingleOutputStreamOperator<Tuple2<String, String>> product = env.addSource(new FlinkKafkaConsumer011<>(
parameterTool.get(METRICS_TOPIC), //这个 kafka topic 需要和上面的工具类的 topic 一致
new SimpleStringSchema(),
props))
.map(string -> GsonUtil.fromJson(string, ProductEvent.class)) //反序列化 JSON
.flatMap(new FlatMapFunction<ProductEvent, Tuple2<String, String>>() {
@Override
public void flatMap(ProductEvent value, Collector<Tuple2<String, String>> out) throws Exception {
//收集商品 id 和 price 两个属性
out.collect(new Tuple2<>(value.getId().toString(), value.getPrice().toString()));
}
});
product.print();
env.execute("flink redis connector");
}
}
然后 IDEA 中启动运行 Job,再运行上面的 ProductUtil 发送 Kafka 数据的工具类,注意:也得提前启动 Kafka。
上图左半部分是工具类发送数据到 Kafka 打印的日志,右半部分是 Job 执行的结果,可以看到它已经将商品的 id 和 price 数据获取到了。
那么接下来我们需要的就是将这种 Tuple2<Long, Long> 格式的 KV 数据写入到 Redis 中去。要将数据写入到 Redis
的话是需要先添加依赖的。
# Redis Connector 简介
Redis Connector 提供用于向 Redis 发送数据的接口的类。接收器可以使用三种不同的方法与不同类型的 Redis 环境进行通信:
- 单 Redis 服务器
- Redis 集群
- Redis Sentinel
# 添加依赖
需要添加 Flink Redis Sink 的 Connector,这个 Redis Connector 官方只有老的版本,后面也一直没有更新,所以可以看到网上有些文章都是添加老的版本的依赖:
包括该部分的文档都是很早之前的啦,可以查看 <https://ci.apache.org/projects/flink/flink-docs- release-1.1/apis/streaming/connectors/redis.html>。
另外在 https://bahir.apache.org/docs/flink/current/flink-streaming-redis/ (opens new window) 也看到一个 Flink Redis Connector 的依赖:
两个依赖功能都是一样的,我们还是就用官方的那个 Maven 依赖来进行演示。
# Flink 写入数据到 Redis
像写入到 Redis,那么肯定要配置 Redis 服务的地址(不管是单机的还是集群)。
单机的 Redis 你可以这样配置:
FlinkJedisPoolConfig conf = new FlinkJedisPoolConfig.Builder().setHost("127.0.0.1").build();
这个 FlinkJedisPoolConfig 源码中有四个属性:
private final String host; //hostname or IP
private final int port; //端口,默认 6379
private final int database; //database index
private final String password; //password
另外你还可以通过 FlinkJedisPoolConfig 设置其他的的几个属性(因为 FlinkJedisPoolConfig 继承自 FlinkJedisConfigBase,这几个属性在 FlinkJedisConfigBase 抽象类的):
protected final int maxTotal; //池可分配的对象最大数量,默认是 8
protected final int maxIdle; //池中空闲的对象最大数量,默认是 8
protected final int minIdle; //池中空闲的对象最小数量,默认是 0
protected final int connectionTimeout; //socket 或者连接超时时间,默认是 2000ms
Redis 集群 你可以这样配置:
FlinkJedisClusterConfig config = new FlinkJedisClusterConfig.Builder()
.setNodes(new HashSet
Redis Sentinels 你可以这样配置:
FlinkJedisSentinelConfig sentinelConfig = new FlinkJedisSentinelConfig.Builder()
.setMasterName("master")
.setSentinels(new HashSet<>(Arrays.asList("sentinel1", "sentinel2")))
.setPassword("")
.setDatabase(1).build();
另外就是 Redis Sink 了,Redis Sink 核心类是 RedisMapper,它是一个接口,里面有三个方法,使用时我们需要重写这三个方法:
public interface RedisMapper
上面 RedisCommandDescription 中有两个属性 RedisCommand、key。RedisCommand 可以设置 Redis 的数据结果类型,下面是 Redis 数据结构的类型对应着的 Redis Command 的类型:
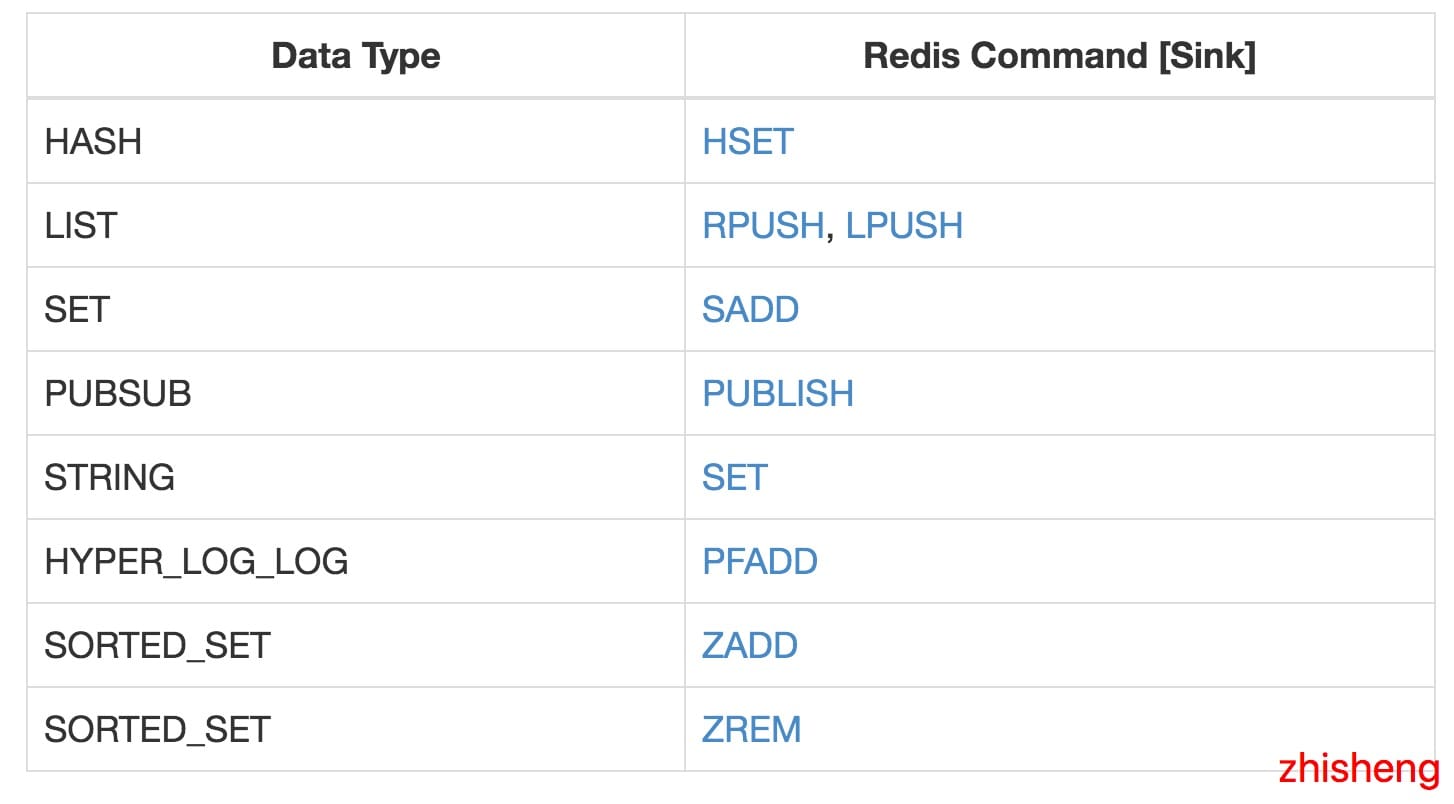 其对应的源码如下:
其对应的源码如下:
public enum RedisCommand {
LPUSH(RedisDataType.LIST),
RPUSH(RedisDataType.LIST),
SADD(RedisDataType.SET),
SET(RedisDataType.STRING),
PFADD(RedisDataType.HYPER_LOG_LOG),
PUBLISH(RedisDataType.PUBSUB),
ZADD(RedisDataType.SORTED_SET),
HSET(RedisDataType.HASH);
private RedisDataType redisDataType;
private RedisCommand(RedisDataType redisDataType) {
this.redisDataType = redisDataType;
}
public RedisDataType getRedisDataType() {
return this.redisDataType;
}
}
我们实现这个 RedisMapper 接口如下:
public static class RedisSinkMapper implements RedisMapper<Tuple2<String, String>> {
@Override
public RedisCommandDescription getCommandDescription() {
//指定 RedisCommand 的类型是 HSET,对应 Redis 中的数据结构是 HASH,另外设置 key = zhisheng
return new RedisCommandDescription(RedisCommand.HSET, "zhisheng");
}
@Override
public String getKeyFromData(Tuple2<String, String> data) {
return data.f0;
}
@Override
public String getValueFromData(Tuple2<String, String> data) {
return data.f1;
}
}
然后在 Flink Job 中加入下面这行,将数据通过 RedisSinkMapper 写入到 Redis 中去:
product.addSink(new RedisSink<Tuple2<String, String>>(conf, new RedisSinkMapper()));
# 验证写入结果
运行 Job 的话,就是把数据已经插入进 Redis 了,那么如何验证我们的结果是否正确呢?
1、我们去终端 Cli 执行命令查看这个 zhisheng 的 key,然后查找某个商品 id (1 ~ 10000) 对应的商品价格,超过这个 id 则为 nil。
2、另外一种验证的方式就是通过 Java 代码来操作 Redis 查询数据了。
我们先引入 Redis 的依赖:
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
连接 Redis 查询数据:
public class RedisTest {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1");
System.out.println("Server is running: " + jedis.ping());
System.out.println("result:" + jedis.hgetAll("zhisheng"));
}
}
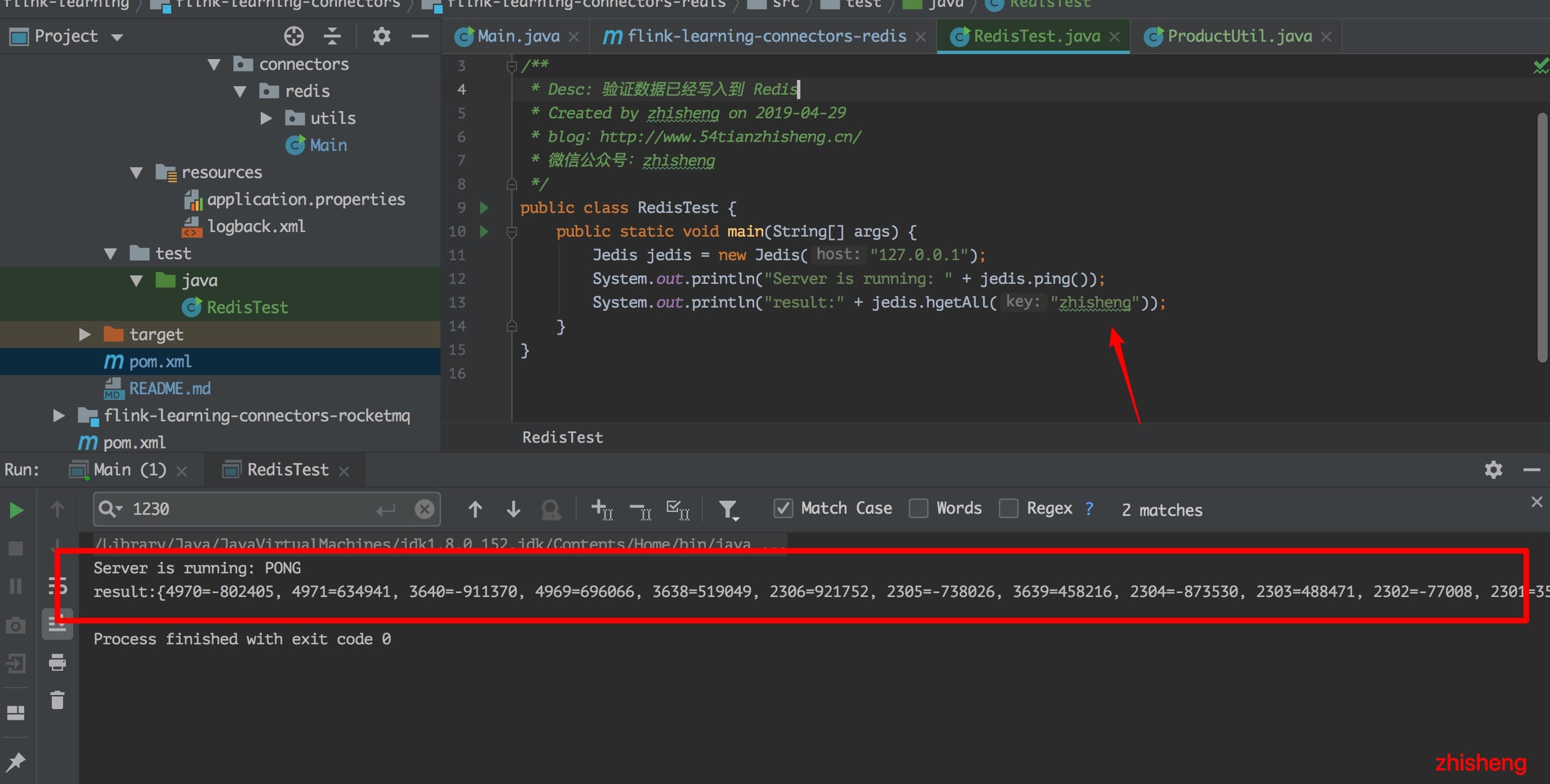 这一行把所有的数据都打印出来了,所以我们的数据确实成功地插入到 Redis 中去了。
这一行把所有的数据都打印出来了,所以我们的数据确实成功地插入到 Redis 中去了。
# 小结与反思
本文先讲解了 Redis 的安装,然后讲了 Flink 如何消费 Kafka 的数据并将数据写入到 Redis 中去。在实战的过程中还分析了 Flink Redis Connector 中的原理,只要我们懂得了这些原理,后面再去做这块的需求就难不倒大家了。
本节涉及的代码地址在:<https://github.com/zhisheng17/flink-learning/tree/master/flink- learning-connectors/flink-learning-connectors-redis>