# 如何利用AsyncIO读取告警规则?
# 为什么需要 Async I/O?
在大多数情况下,IO 操作都是一个耗时的过程,尤其在流计算中,如果在具体的算子里面还有和第三方外部系统(比如数据库、Redis、HBase 等存储系统)做交互,比如在一个 MapFunction 中每来一条数据就要去查找 MySQL 中某张表的数据,然后跟查询出来的数据做关联(同步交互)。查询请求到数据库,再到数据库响应返回数据的整个流程的时间对于流作业来说是比较长的。那么该 Map 算子处理数据的速度就会降下来,在大数据量的情况下很可能会导致整个流作业出现反压问题(在 9.1 节中讲过),那么整个作业的消费延迟就会增加,影响作业整体吞吐量和实时性,从而导致最终该作业处于不可用的状态。
这种同步的与数据库做交互操作,会因耗时太久导致整个作业延迟,如果换成异步的话,就可以同时处理很多请求并同时可以接收响应,这样的话,等待数据库响应的时间就会与其他发送请求和接收响应的时间重叠,相同的等待时间内会处理多个请求,从而比同步的访问要提高不少流处理的吞吐量。虽然也可以通过增大该算子的并行度去执行查数据库,但是这种解决办法需要消耗更多的资源(并行度增加意味着消费的 slot 个数也会增加),这种方法和使用异步处理的方法对比一下,还是使用异步的查询数据库这种方法值得使用。
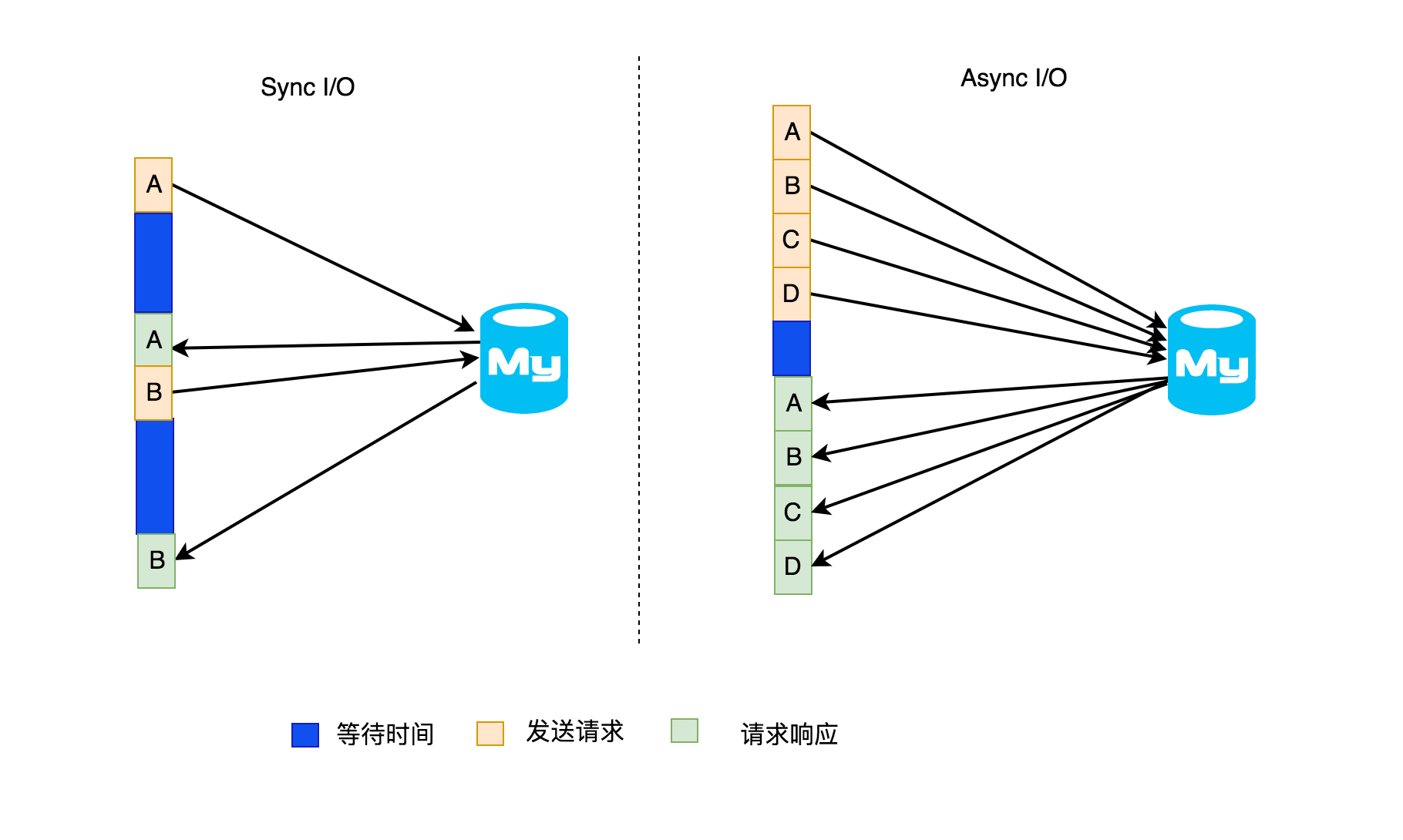 在上图中,左侧表示的是在流处理中同步的数据库请求,右侧是异步的数据库请求。假设左侧是数据流中 A 数据来了发送一个查询数据库的请求看是否之前存在
A,然后等待查询结果返回,只有等 A 整个查询请求响应后才会继续开始 B 数据的查询请求,依此继续;而右侧是连续的去数据库查询是否存在
A、B、C、D,后面哪个请求先响应就先处理哪个,不需要和左侧的一样要等待上一个请求全部完成才可以开始下一个请求,所以异步的话吞吐量自然就高起来了。但是得注意的是:使用异步这种方法前提是要数据库客户端支持异步的请求,否则可能需要借助线程池来实现异步请求,但是现在主流的数据库通常都支持异步的操作,所以不用太担心。
在上图中,左侧表示的是在流处理中同步的数据库请求,右侧是异步的数据库请求。假设左侧是数据流中 A 数据来了发送一个查询数据库的请求看是否之前存在
A,然后等待查询结果返回,只有等 A 整个查询请求响应后才会继续开始 B 数据的查询请求,依此继续;而右侧是连续的去数据库查询是否存在
A、B、C、D,后面哪个请求先响应就先处理哪个,不需要和左侧的一样要等待上一个请求全部完成才可以开始下一个请求,所以异步的话吞吐量自然就高起来了。但是得注意的是:使用异步这种方法前提是要数据库客户端支持异步的请求,否则可能需要借助线程池来实现异步请求,但是现在主流的数据库通常都支持异步的操作,所以不用太担心。
# Async I/O API
Flink 的 Async I/O API 允许用户在数据流处理中使用异步请求,并且还支持超时处理、处理顺序、事件时间、容错。在 Flink 中,如果要使用 Async I/O API,是非常简单的,需要通过下面三个步骤来执行对数据库的异步操作。
- 继承 RichAsyncFunction 抽象类或者实现用来分发请求的 AsyncFunction 接口
- 返回异步请求的结果的 Future
- 在 DataStream 上使用异步操作
官网也给出案例如下:
class AsyncDatabaseRequest extends RichAsyncFunction<String, Tuple2<String, String>> {
//数据库的客户端,它可以发出带有 callback 的并发请求
private transient DatabaseClient client;
@Override
public void open(Configuration parameters) throws Exception {
client = new DatabaseClient(host, post, credentials);
}
@Override
public void close() throws Exception {
client.close();
}
@Override
public void asyncInvoke(String key, final ResultFuture<Tuple2<String, String>> resultFuture) throws Exception{
//发出异步请求,接收 future 的结果
final Future<String> result = client.query(key);
//设置客户端请求完成后执行的 callback,callback 只是将结果转发给 ResultFuture
CompletableFuture.supplyAsync(new Supplier<String>() {
@Override
public String get() {
try {
return result.get();
} catch (InterruptedException | ExecutionException e) {
return null;
}
}
}).thenAccept( (String dbResult) -> {
resultFuture.complete(Collections.singleton(new Tuple2<>(key, dbResult)));
});
}
}
//原始数据
DataStream<String> stream = ...;
//应用异步 I/O 转换
DataStream<Tuple2<String, String>> resultStream =
AsyncDataStream.unorderedWait(stream, new AsyncDatabaseRequest(), 1000, TimeUnit.MILLISECONDS, 100);
注意:ResultFuture 在第一次调用 resultFuture.complete 时就已经完成了,后面所有 resultFuture.complete 的调用都会被忽略。
下面两个参数控制了异步操作:
- Timeout:timeout 定义了异步操作过了多长时间后会被丢弃,这个参数是防止了死的或者失败的请求
- Capacity:这个参数定义可以同时处理多少个异步请求。虽然异步请求会带来更好的吞吐量,但是该操作仍然可能成为流作业的性能瓶颈。限制并发请求的数量可确保操作不会不断累积处理请求,一旦超过 Capacity 值,它将触发反压。
# 超时处理
当异步 I/O 请求超时时,默认情况下会引发超时异常并重新启动作业。如果要自定义超时处理策略,可以重写 AsyncFunction 接口的 timeout 方法。
# 结果顺序
通过 AsyncFunction 完成的
AsyncFunction 发出的并发请求通常以某种未定义的顺序完成,具体取决于首先完成的请求。为了控制发出结果记录的顺序,Flink 提出了两种模式:
无序:异步请求完成后立即发出结果记录,在异步 I/O 操作后,流中记录的顺序与以前不同,当时间策略使用的是处理时间时,这种情况下的延迟和开销都会很小,使用 AsyncDataStream.unorderedWait(...) 开启此模式。
有序:在这种情况下,会保证流数据的顺序,结果记录发出去的顺序与触发异步请求的顺序相同,为此,如果有记录的结果先返回,也会在队列中缓存着,直到其前面的结果记录都发出(或者超时)了。这样的话就会导致部分数据会有一定的延迟和等待开销,因为和无序的情况下对比,这些结果会在状态中保持更长的时间,使用 AsyncDataStream.orderedWait(...) 开启此模式。
# 事件时间
当作业设置时间属性为事件时间时,异步 I/O 操作将正确处理 Watermark,有两种方式:
无序:因为 Watermark 的大小不会超过事件的时间,所以 Watermark 就相当于会建立一个顺序的边界。事件只在 Watermark 的时间范围内无序发出,在某个 Watermark 之后的事件仅会在 Watermark 发出之后才被发出,反过来就是只有在水印之前的所有事件都发出后才会发出 Watermark。
有序:保存事件的 Watermark 顺序,就像保存事件之间的顺序一样,与处理时间的性能开销差不多。
# 容错性保证
异步 I/O 操作提供了 Exactly once 容错性保证,它将异步请求的记录存储在 Checkpoint 中,出现故障后能恢复到之前状态,重新触发异步 I/O 请求。
# 实践技巧
如果要使用 Executor(或 Scala 中的 ExecutionContext)进行 callback 的 Future 实现,建议直接使用 DirectExecutor,因为 callback 所要做的工作很少,通常是只将结果传递给 ResultFuture,然后将其添加到输出缓冲区中,接着复杂的逻辑(事件的发送和 Checkpoint 交互)将在专用的线程池中完成,而 DirectExecutor 可以避免额外的线程到线程的切换开销。
可以通过 org.apache.flink.runtime.concurrent.Executors.directExecutor() 或者
com.google.common.util.concurrent.MoreExecutors.directExecutor() 获取到
DirectExecutor 对象。
# 注意点
AsyncFunction 它不是以多线程的方式调用的,它仅仅存在一个实例。
# 利用 Async I/O 读取告警规则需求分析
上面已经介绍了异步 I/O 设计的初衷,以及 Flink 中如何使用异步 I/O 及内部的原理,接下来就使用异步 I/O 来处理一个需求。假设监控数据有很多,但是需要告警的指标相对于底层采集的指标来说不会太多,所以有这么个需求就是根据采集上来的监控数据去数据库中判断该数据是否属于需要告警的指标,如果该数据属于要告警的指标,则再根据监控数据去读取这条规则,然后与规则中的阈值进行判断,看这条监控数据是否异常。虽然这个可能会有很多解决方法,但是这里主要讲解下如何使用异步 I/O 实现该需求。
# 监控数据样例
采集上来的监控数据的类型是 MetricEvent,假设采集上来的数据如下:
{
"name": "load",
"timestamp": 1571214922826,
"fields": {
"load5": 42,
"load1": 77,
"load15": 23
},
"tags": {
"cluster_name": "zhisheng",
"host_ip": "127.0.0.1"
}
}
上面表示的是某个集群某台机器在某个时间点的负载情况,load1 表示 1 分钟内的平均负载,load5 表示 5 分钟内的平均负载,load15 表示 15 分钟内的平均负载。当 Flink 中处理到这么一条数据后,需要去找数据库中的告警规则是否有配置 load 的监控告警指标,并且读取到其配置的阈值。假设这里告警只关心 load5,告警规则中只配置 load5 的阈值为 20,当获取到阈值为 20 时,将 20 与监控数据的 42 对比后,发现此时这台机器的负载已经超过配置的阈值了,那么就该判定这条数据为一条异常数据,接着该触发告警了。
# 告警规则表设计
因为上面分析的内容毕竟简单,所以告警规则的表这里设计的话也是从简为好,生产环境中会有更多其他的字段来表示其他要处理的内容,在这里笔者不做过多的讲解。建表语句如下:
CREATE TABLE `alert_rule` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(10) COLLATE utf8_bin DEFAULT NULL,
`measurement` varchar(30) COLLATE utf8_bin DEFAULT NULL,
`thresholds` varchar(10) COLLATE utf8_bin DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
这里插入一条数据如下:
INSERT INTO alert_rule (id, name, measurement, thresholds,) VALUES(1, 'load', 'load5', '20');
插入的这条规则表示:机器 5 分钟的平均负载超过 20 则告警。
# 告警规则实体类
告警规则对应的实体类如下:
@Data
@AllArgsConstructor
@NoArgsConstructor
@Builder
public class AlertRule {
private Integer id;
private String name;
private String measurement;
private String thresholds;
}
# 如何使用 Async I/O 读取告警规则数据
先读取到监控数据,然后通过 AsyncDataStream.unorderedWait 处理监控数据,设置超时时间是 10 秒,容量为 100。
AsyncDataStream.unorderedWait(machineData, new AlertRuleAsyncIOFunction(), 10000, TimeUnit.MICROSECONDS, 100)
异步查询告警规则的代码如下:
public class AlertRuleAsyncIOFunction extends RichAsyncFunction<MetricEvent, MetricEvent> {
PreparedStatement ps;
private Connection connection;
@Override
public void open(Configuration parameters) throws Exception {
connection = getConnection();
String sql = "select * from alert_rule where name = ?;";
if (connection != null) {
ps = this.connection.prepareStatement(sql);
}
}
@Override
public void timeout(MetricEvent metricEvent, ResultFuture<MetricEvent> resultFuture) throws Exception {
log.info("=================timeout======{} ", metricEvent);
}
@Override
public void asyncInvoke(MetricEvent metricEvent, ResultFuture<MetricEvent> resultFuture) throws Exception {
ps.setString(1, metricEvent.getName());
ResultSet resultSet = ps.executeQuery();
Map<String, Object> fields = metricEvent.getFields();
if (resultSet.next()) {
String thresholds = resultSet.getString("thresholds");
String measurement = resultSet.getString("measurement");
if (fields.get(measurement) != null && (double) fields.get(measurement) > Double.valueOf(thresholds)) {
resultFuture.complete(Collections.singletonList(metricEvent));
}
}
}
private static Connection getConnection() {
//获取数据库连接
}
}
在 asyncInvoke 方法中异步的处理数据,注意最后需要通过 ResultFuture.complete 将结果设置到 ResultFuture,如果异常则通过 ResultFuture.completeExceptionally(Throwable) 来传递到 ResultFuture
# 小结与反思
本节一开始介绍了 Async I/O 产生的背景,然后介绍了内部的 API 使用及原理,接着通过一个需求来教大家如何使用 Async I/O。
本节涉及代码地址:https://github.com/zhisheng17/flink-learning/blob/master/flink- learning-monitor/flink-learning-monitor- alert/src/main/java/com/zhisheng/alert/alert/AsyncIOAlert.java