# 如何实时监控Flink和你的Job?
当将 Flink Job Manager、Task Manager 都运行起来了,并且也部署了不少 Flink Job,那么它到底是否还在运行、运行的状态如何、资源 Task Manager 和 Slot 的个数是否足够、Job 内部是否出现异常、计算速度是否跟得上数据生产的速度 等这些问题其实对我们来说是比较关注的,所以就很迫切的需要一个监控系统帮我们把整个 Flink 集群的运行状态给展示出来。通过监控系统我们能够很好的知道 Flink 内部的整个运行状态,然后才能够根据项目生产环境遇到的问题 ‘对症下药’。下面分别来讲下 Job Manager、TaskManager、Flink Job 的监控以及最关心的一些监控指标。
# 监控 Job Manager
我们知道 Job Manager 是 Flink 集群的中控节点,类似于 Apache Storm 的 Nimbus 以及 Apache Spark 的 Driver 的角色。它负责作业的调度、作业 Jar 包的管理、Checkpoint 的协调和发起、与 Task Manager 之间的心跳检查等工作。如果 Job Manager 出现问题的话,就会导致作业 UI 信息查看不了,Task Manager 和所有运行的作业都会受到一定的影响,所以这也是为啥在 7.1 节中强调 Job Manager 的高可用问题。
在 Flink 自带的 UI 上 Job Manager 那个 Tab 展示的其实并没有显示其对应的 Metrics,那么对于 Job Manager 来说常见比较关心的监控指标有哪些呢?
# 基础指标
因为 Flink Job Manager 其实也是一个 Java 的应用程序,那么它自然也会有 Java 应用程序的指标,比如内存、CPU、GC、类加载、线程信息等。
内存:内存又分堆内存和非堆内存,在 Flink 中还有 Direct 内存,每种内存又有初始值、使用值、最大值等指标,因为在 Job Manager 中的工作其实相当于 Task Manager 来说比较少,也不存储事件数据,所以通常 Job Manager 占用的内存不会很多,在 Flink Job Manager 中自带的内存 Metrics 指标有:
jobmanager_Status_JVM_Memory_Direct_Count jobmanager_Status_JVM_Memory_Direct_MemoryUsed jobmanager_Status_JVM_Memory_Direct_TotalCapacity jobmanager_Status_JVM_Memory_Heap_Committed jobmanager_Status_JVM_Memory_Heap_Max jobmanager_Status_JVM_Memory_Heap_Used jobmanager_Status_JVM_Memory_Mapped_Count jobmanager_Status_JVM_Memory_Mapped_MemoryUsed jobmanager_Status_JVM_Memory_Mapped_TotalCapacity jobmanager_Status_JVM_Memory_NonHeap_Committed jobmanager_Status_JVM_Memory_NonHeap_Max jobmanager_Status_JVM_Memory_NonHeap_Used
CPU:Job Manager 分配的 CPU 使用情况,如果使用类似 K8S 等资源调度系统,则需要对每个容器进行设置资源,比如 CPU 限制不能超过多少,在 Flink Job Manager 中自带的 CPU 指标有:
jobmanager_Status_JVM_CPU_Load jobmanager_Status_JVM_CPU_Time
GC:GC 信息对于 Java 应用来说是避免不了的,每种 GC 都有时间和次数的指标可以供参考,提供的指标有:
jobmanager_Status_JVM_GarbageCollector_PS_MarkSweep_Count jobmanager_Status_JVM_GarbageCollector_PS_MarkSweep_Time jobmanager_Status_JVM_GarbageCollector_PS_Scavenge_Count jobmanager_Status_JVM_GarbageCollector_PS_Scavenge_Time
# Checkpoint 指标
因为 Job Manager 负责了作业的 Checkpoint 的协调和发起功能,所以 Checkpoint 相关的指标就有表示 Checkpoint 执行的时间、Checkpoint 的时间长短、完成的 Checkpoint 的次数、Checkpoint 失败的次数、Checkpoint 正在执行 Checkpoint 的个数等,其对应的指标如下:
jobmanager_job_lastCheckpointAlignmentBuffered
jobmanager_job_lastCheckpointDuration
jobmanager_job_lastCheckpointExternalPath
jobmanager_job_lastCheckpointRestoreTimestamp
jobmanager_job_lastCheckpointSize
jobmanager_job_numberOfCompletedCheckpoints
jobmanager_job_numberOfFailedCheckpoints
jobmanager_job_numberOfInProgressCheckpoints
jobmanager_job_totalNumberOfCheckpoints
# 重要的指标
另外还有比较重要的指标就是 Flink UI 上也提供的,类似于 Slot 总共个数、Slot 可使用的个数、Task Manager 的个数(通过查看该值可以知道是否有 Task Manager 发生异常重启)、正在运行的作业数量、作业运行的时间和完成的时间、作业的重启次数,对应的指标如下:
jobmanager_job_uptime
jobmanager_numRegisteredTaskManagers
jobmanager_numRunningJobs
jobmanager_taskSlotsAvailable
jobmanager_taskSlotsTotal
jobmanager_job_downtime
jobmanager_job_fullRestarts
jobmanager_job_restartingTime
# 监控 Task Manager
Task Manager 在 Flink 集群中也是一个个的进程实例,它的数量代表着能够运行作业个数的能力,所有的 Flink 作业最终其实是会在 Task Manager 上运行的,Task Manager 管理着运行在它上面的所有作业的 Task 的整个生命周期,包括了 Task 的启动销毁、内存管理、磁盘 IO、网络传输管理等。
因为所有的 Task 都是运行运行在 Task Manager 上的,有的 Task 可能会做比较复杂的操作或者会存储很多数据在内存中,那么就会消耗很大的资源,所以通常来说 Task Manager 要比 Job Manager 消耗的资源要多,但是这个资源具体多少其实也不好预估,所以可能会出现由于分配资源的不合理,导致 TaskManager 出现 OOM 等问题。一旦 TaskManager 因为各种问题导致崩溃重启的话,运行在它上面的 Task 也都会失败,Job Manager 与它的通信也会丢失。因为作业出现 failover,所以在重启这段时间它是不会去消费数据的,所以必然就会出现数据消费延迟的问题。对于这种情况那么必然就很需要 TaskManager 的监控信息,这样才能够对整个集群的 TaskManager 做一个提前预警。
那么在 Flink 中自带的 Task Manager Metrics 有哪些呢?主要也是 CPU、类加载、GC、内存、网络等。其实这些信息在 Flink UI 上也是有,不知道读者有没有细心观察过。
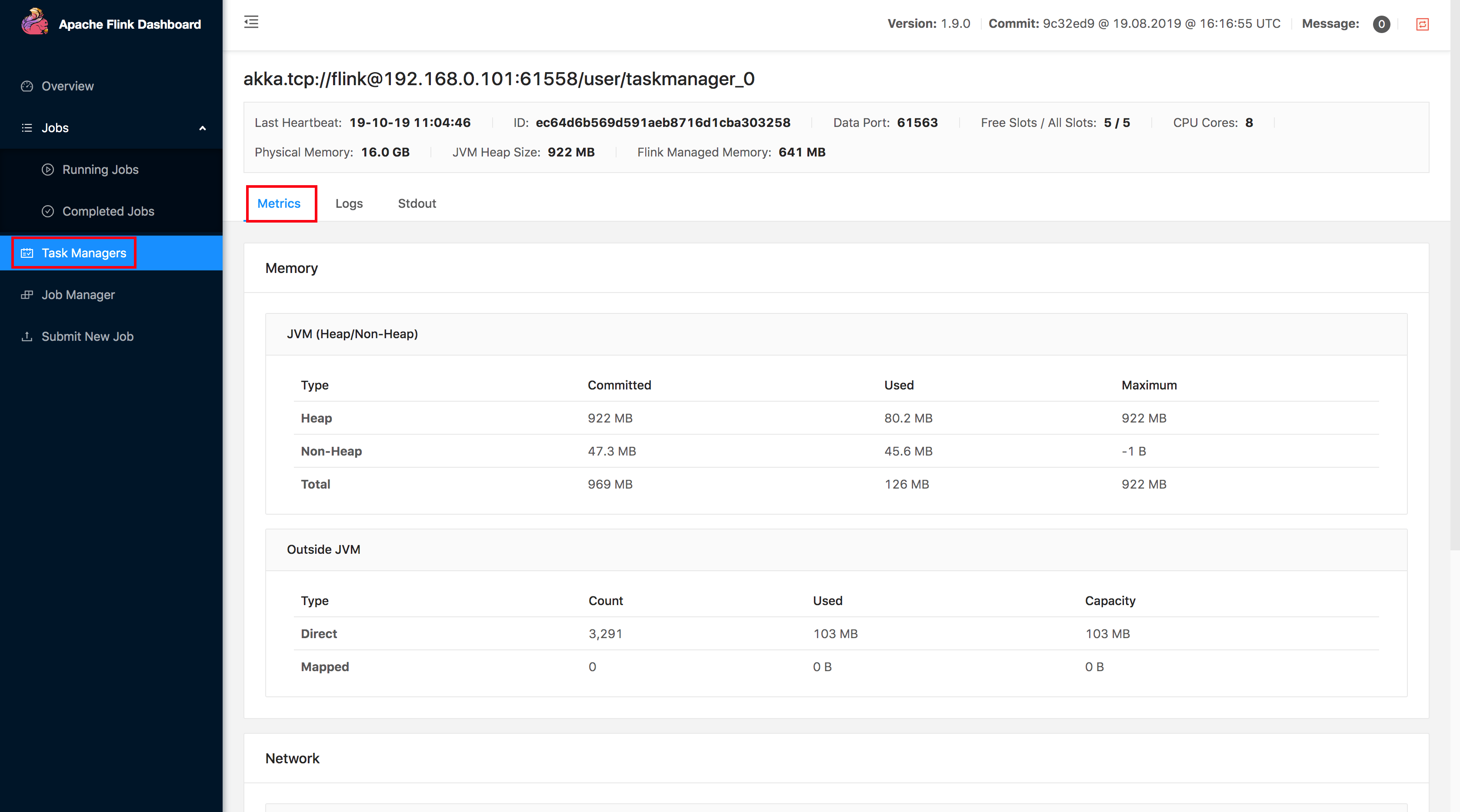 在这个 Task Manager 的 Metrics 监控页面通常比较关心的指标有内存相关的,还有就是 GC 的指标,通常一个 Task Manager
出现 OOM 之前会不断的进行 GC,在这个 Metrics 页面它展示了年轻代和老年代的 GC 信息(时间和次数),大家可以细心观察下是否 Task
Manager OOM 前老年代和新生代的 GC 次数比较、时间比较长。
在这个 Task Manager 的 Metrics 监控页面通常比较关心的指标有内存相关的,还有就是 GC 的指标,通常一个 Task Manager
出现 OOM 之前会不断的进行 GC,在这个 Metrics 页面它展示了年轻代和老年代的 GC 信息(时间和次数),大家可以细心观察下是否 Task
Manager OOM 前老年代和新生代的 GC 次数比较、时间比较长。
 在 Flink Reporter 中提供的 Task Manager Metrics 指标如下:
在 Flink Reporter 中提供的 Task Manager Metrics 指标如下:
taskmanager_Status_JVM_CPU_Load
taskmanager_Status_JVM_CPU_Time
taskmanager_Status_JVM_ClassLoader_ClassesLoaded
taskmanager_Status_JVM_ClassLoader_ClassesUnloaded
taskmanager_Status_JVM_GarbageCollector_G1_Old_Generation_Count
taskmanager_Status_JVM_GarbageCollector_G1_Old_Generation_Time
taskmanager_Status_JVM_GarbageCollector_G1_Young_Generation_Count
taskmanager_Status_JVM_GarbageCollector_G1_Young_Generation_Time
taskmanager_Status_JVM_Memory_Direct_Count
taskmanager_Status_JVM_Memory_Direct_MemoryUsed
taskmanager_Status_JVM_Memory_Direct_TotalCapacity
taskmanager_Status_JVM_Memory_Heap_Committed
taskmanager_Status_JVM_Memory_Heap_Max
taskmanager_Status_JVM_Memory_Heap_Used
taskmanager_Status_JVM_Memory_Mapped_Count
taskmanager_Status_JVM_Memory_Mapped_MemoryUsed
taskmanager_Status_JVM_Memory_Mapped_TotalCapacity
taskmanager_Status_JVM_Memory_NonHeap_Committed
taskmanager_Status_JVM_Memory_NonHeap_Max
taskmanager_Status_JVM_Memory_NonHeap_Used
taskmanager_Status_JVM_Threads_Count
taskmanager_Status_Network_AvailableMemorySegments
taskmanager_Status_Network_TotalMemorySegments
taskmanager_Status_Shuffle_Netty_AvailableMemorySegments
taskmanager_Status_Shuffle_Netty_TotalMemorySegments
# 监控 Flink Job
对于运行的作业来说,其实我们会更关心其运行状态,如果没有其对应的一些监控信息,那么对于我们来说这个 Job 就是一个黑盒,完全不知道是否在运行,Job 运行状态是什么、Task 运行状态是什么、是否在消费数据、消费数据是咋样(细分到每个 Task)、消费速度能否跟上生产数据的速度、处理数据的过程中是否有遇到什么错误日志、处理数据是否有出现反压问题等等。
上面列举的这些问题通常来说是比较关心的,那么在 Flink UI 上也是有提供的查看对应的信息的,点开对应的作业就可以查看到作业的执行图,每个 Task 的信息都是会展示出来的,包含了状态、Bytes Received(接收到记录的容量大小)、Records Received(接收到记录的条数)、Bytes Sent(发出去的记录的容量大小)、Records Sent(发出去记录的条数)、异常信息、timeline(作业运行状态的时间线)、Checkpoint 信息。
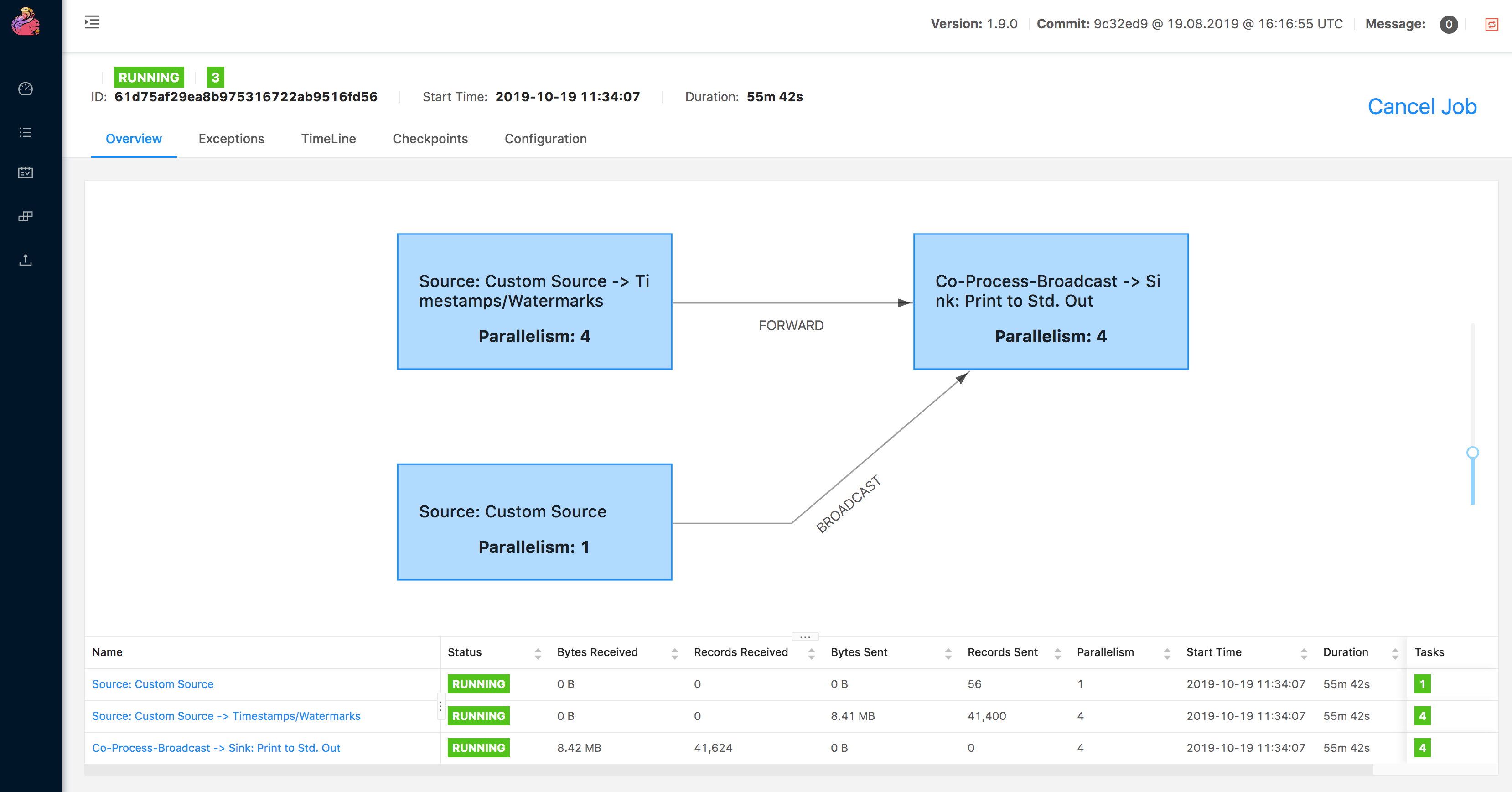 这些指标也可以通过 Flink 的 Reporter 进行上报存储到第三方的时序数据库,然后通过类似 Grafana
展示出来。通过这些信息大概就可以清楚的知道一个 Job 的整个运行状态,然后根据这些运行状态去分析作业是否有问题。
这些指标也可以通过 Flink 的 Reporter 进行上报存储到第三方的时序数据库,然后通过类似 Grafana
展示出来。通过这些信息大概就可以清楚的知道一个 Job 的整个运行状态,然后根据这些运行状态去分析作业是否有问题。
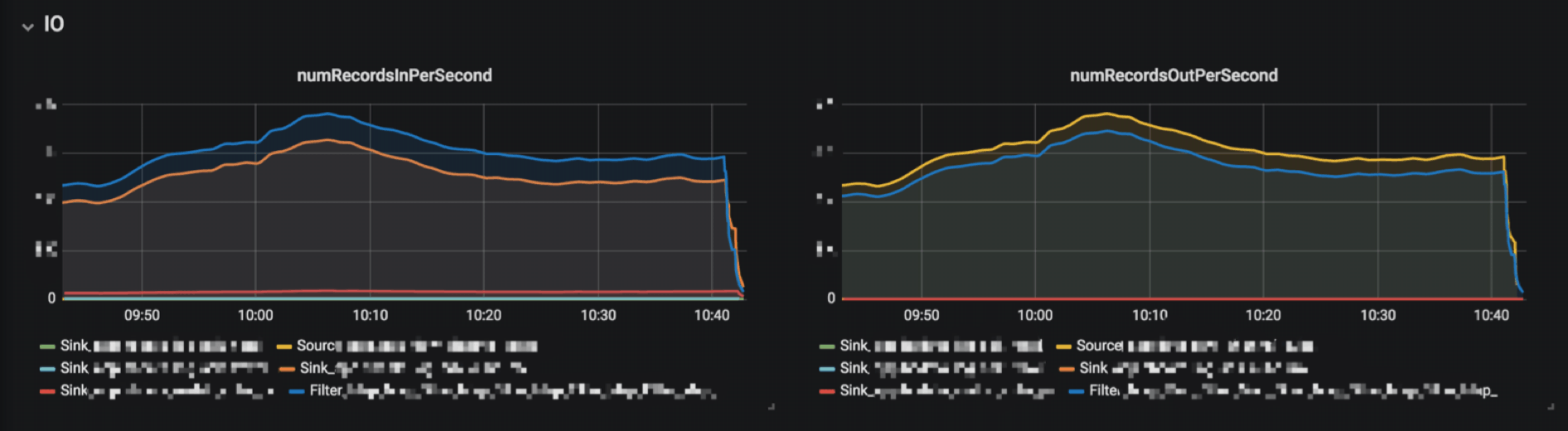 在流作业中最关键的指标无非是作业的实时性,那么延迟就是衡量作业的是否实时的一个基本参数,但是对于现有的这些信息其实还不知道作业的消费是否有延迟,通常来说可以结合
Kafka 的监控去查看对应消费的 Topic 的 Group 的 Lag 信息,如果 Lag
很大就表明有数据堆积了,另外还有一个办法就是需要自己在作业中自定义 Metrics 做埋点,将算子在处理数据的系统时间与数据自身的 Event Time
做一个差值,求得值就可以知道算子消费的数据是什么时候的了。比如在 1571457964000(2019-10-19 12:06:04)Map
算子消费的数据的事件时间是 1571457604000(2019-10-19 12:00:04),相差了 6 分钟,那么就表明消费延迟了 6 分钟,然后通过
Metrics Reporter 将埋点的 Metrics 信息上传,这样最终就可以获取到作业在每个算子处的消费延迟的时间。
在流作业中最关键的指标无非是作业的实时性,那么延迟就是衡量作业的是否实时的一个基本参数,但是对于现有的这些信息其实还不知道作业的消费是否有延迟,通常来说可以结合
Kafka 的监控去查看对应消费的 Topic 的 Group 的 Lag 信息,如果 Lag
很大就表明有数据堆积了,另外还有一个办法就是需要自己在作业中自定义 Metrics 做埋点,将算子在处理数据的系统时间与数据自身的 Event Time
做一个差值,求得值就可以知道算子消费的数据是什么时候的了。比如在 1571457964000(2019-10-19 12:06:04)Map
算子消费的数据的事件时间是 1571457604000(2019-10-19 12:00:04),相差了 6 分钟,那么就表明消费延迟了 6 分钟,然后通过
Metrics Reporter 将埋点的 Metrics 信息上传,这样最终就可以获取到作业在每个算子处的消费延迟的时间。
上面的是针对于作业延迟的判断方法,另外像类似于作业反压的情况,在 Flink 的 UI 也会有展示,具体怎么去分析和处理这种问题在 9.1 节中有详细讲解。
根据这些监控信息不仅可以做到提前预警,做好资源的扩容(比如增加容器的数量/内存/CPU/并行度/Slot 个数),也还可以找出作业配置的资源是否有浪费。通常来说一个作业的上线可能是会经过资源的预估,然后才会去申请这个作业要配置多少资源,比如算子要使用多少并行度,最后上线后可以通过完整的运行监控信息查看该作业配置的并行度是否有过多或者配置的内存比较大。比如出现下面这些情况的时候可能就是资源出现浪费了:
- 作业消费从未发生过延迟,即使在数据流量高峰的时候,也未发生过消费延迟
- 作业运行所在的 Task Manager 堆内存使用率异常的低
- 作业运行所在的 Task Manager 的 GC 时间和次数非常规律,没有出现异常的现象
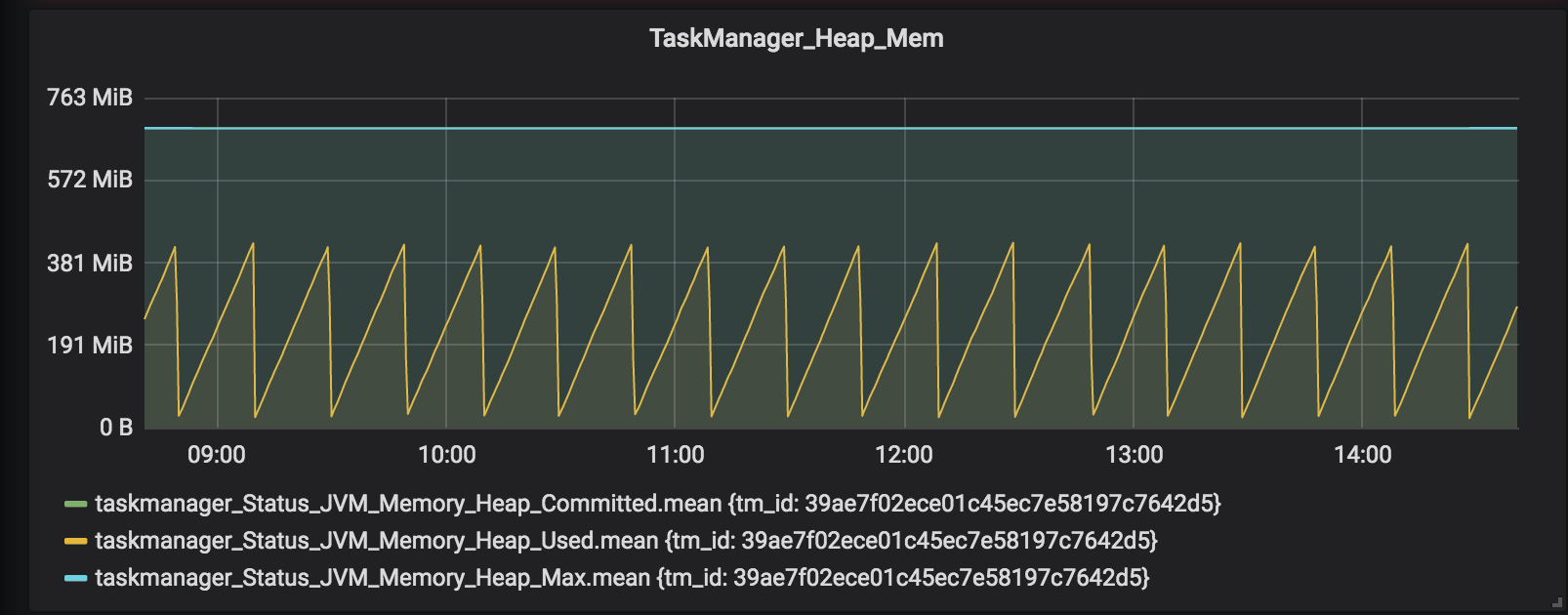 在 Flink Metrics Reporter 上传的指标中大概有下面这些:
在 Flink Metrics Reporter 上传的指标中大概有下面这些:
taskmanager_job_task_Shuffle_Netty_Input_Buffers_outPoolUsage
taskmanager_job_task_Shuffle_Netty_Input_Buffers_outputQueueLength
taskmanager_job_task_Shuffle_Netty_Output_Buffers_inPoolUsage
taskmanager_job_task_Shuffle_Netty_Output_Buffers_inputExclusiveBuffersUsage
taskmanager_job_task_Shuffle_Netty_Output_Buffers_inputFloatingBuffersUsage
taskmanager_job_task_Shuffle_Netty_Output_Buffers_inputQueueLength
taskmanager_job_task_Shuffle_Netty_Output_numBuffersInLocal
taskmanager_job_task_Shuffle_Netty_Output_numBuffersInLocalPerSecond
taskmanager_job_task_Shuffle_Netty_Output_numBuffersInRemote
taskmanager_job_task_Shuffle_Netty_Output_numBuffersInRemotePerSecond
taskmanager_job_task_Shuffle_Netty_Output_numBytesInLocal
taskmanager_job_task_Shuffle_Netty_Output_numBytesInLocalPerSecond
taskmanager_job_task_Shuffle_Netty_Output_numBytesInRemote
taskmanager_job_task_Shuffle_Netty_Output_numBytesInRemotePerSecond
taskmanager_job_task_buffers_inPoolUsage
taskmanager_job_task_buffers_inputExclusiveBuffersUsage
taskmanager_job_task_buffers_inputFloatingBuffersUsage
taskmanager_job_task_buffers_inputQueueLength
taskmanager_job_task_buffers_outPoolUsage
taskmanager_job_task_buffers_outputQueueLength
taskmanager_job_task_checkpointAlignmentTime
taskmanager_job_task_currentInputWatermark
taskmanager_job_task_numBuffersInLocal
taskmanager_job_task_numBuffersInLocalPerSecond
taskmanager_job_task_numBuffersInRemote
taskmanager_job_task_numBuffersInRemotePerSecond
taskmanager_job_task_numBuffersOut
taskmanager_job_task_numBuffersOutPerSecond
taskmanager_job_task_numBytesIn
taskmanager_job_task_numBytesInLocal
taskmanager_job_task_numBytesInLocalPerSecond
taskmanager_job_task_numBytesInPerSecond
taskmanager_job_task_numBytesInRemote
taskmanager_job_task_numBytesInRemotePerSecond
taskmanager_job_task_numBytesOut
taskmanager_job_task_numBytesOutPerSecond
taskmanager_job_task_numRecordsIn
taskmanager_job_task_numRecordsInPerSecond
taskmanager_job_task_numRecordsOut
taskmanager_job_task_numRecordsOutPerSecond
taskmanager_job_task_operator_currentInputWatermark
taskmanager_job_task_operator_currentOutputWatermark
taskmanager_job_task_operator_numLateRecordsDropped
taskmanager_job_task_operator_numRecordsIn
taskmanager_job_task_operator_numRecordsInPerSecond
taskmanager_job_task_operator_numRecordsOut
taskmanager_job_task_operator_numRecordsOutPerSecond
# 最关心的监控指标有哪些
上面已经提及到 Flink 的 Job Manager、Task Manager 和运行的 Flink Job 的监控以及常用的监控信息,这些指标有的是可以直接在 Flink 的 UI 上观察到的,另外 Flink 提供了 Metrics Reporter 进行上报存储到监控系统中去,然后通过可视化的图表进行展示,在 8.2 节中将教大家如何构建一个完整的监控系统。那么有了这么多监控指标,其实哪些是比较重要的呢,比如说这些指标出现异常的时候可以发出告警及时进行通知,这样可以做到预警作用,另外还可以根据这些信息进行作业资源的评估。下面列举一些笔者觉得比较重要的指标:
# Job Manager
在 Job Manager 中有着该集群中所有的 Task Manager 的个数、Slot 的总个数、Slot 的可用个数、运行的时间、作业的 Checkpoint 情况,笔者觉得这几个指标可以重点关注。
- TaskManager 个数:如果出现 TaskManager 突然减少,可能是因为有 TaskManager 挂掉重启,一旦该 TaskManager 之前运行了很多作业,那么重启带来的影响必然是巨大的。
- Slot 个数:取决于 TaskManager 的个数,决定了能运行作业的最大并行度,如果资源不够,及时扩容。
- 作业运行时间:根据作业的运行时间来判断作业是否存活,中途是否掉线过。
- Checkpoint 情况:Checkpoint 是 Job Manager 发起的,并且关乎到作业的状态是否可以完整的保存。
# TaskManager
因为所有的作业最终都是运行在 TaskManager 上,所以 TaskManager 的监控指标也是异常的监控,并且作业的复杂度也会影响 TaskManager 的资源使用情况,所以 TaskManager 的基础监控指标比如内存、GC 如果出现异常或者超出设置的阈值则需要立马进行告警通知,防止后面导致大批量的作业出现故障重启。
- 内存使用率:部分作业的算子会将所有的 State 数据存储在内存中,这样就会导致 TaskManager 的内存使用率会上升,还有就是可以根据该指标看作业的利用率,从而最后来重新划分资源的配置。
- GC 情况:分时间和次数,一旦 TaskManager 的内存率很高的时候,必定伴随着频繁的 GC,如果在 GC 的时候没有得到及时的预警,那么将面临 OOM 风险。
# Flink Job
作业的稳定性和及时性其实就是大家最关心的,常见的指标有:作业的状态、Task 的状态、作业算子的消费速度、作业出现的异常日志。
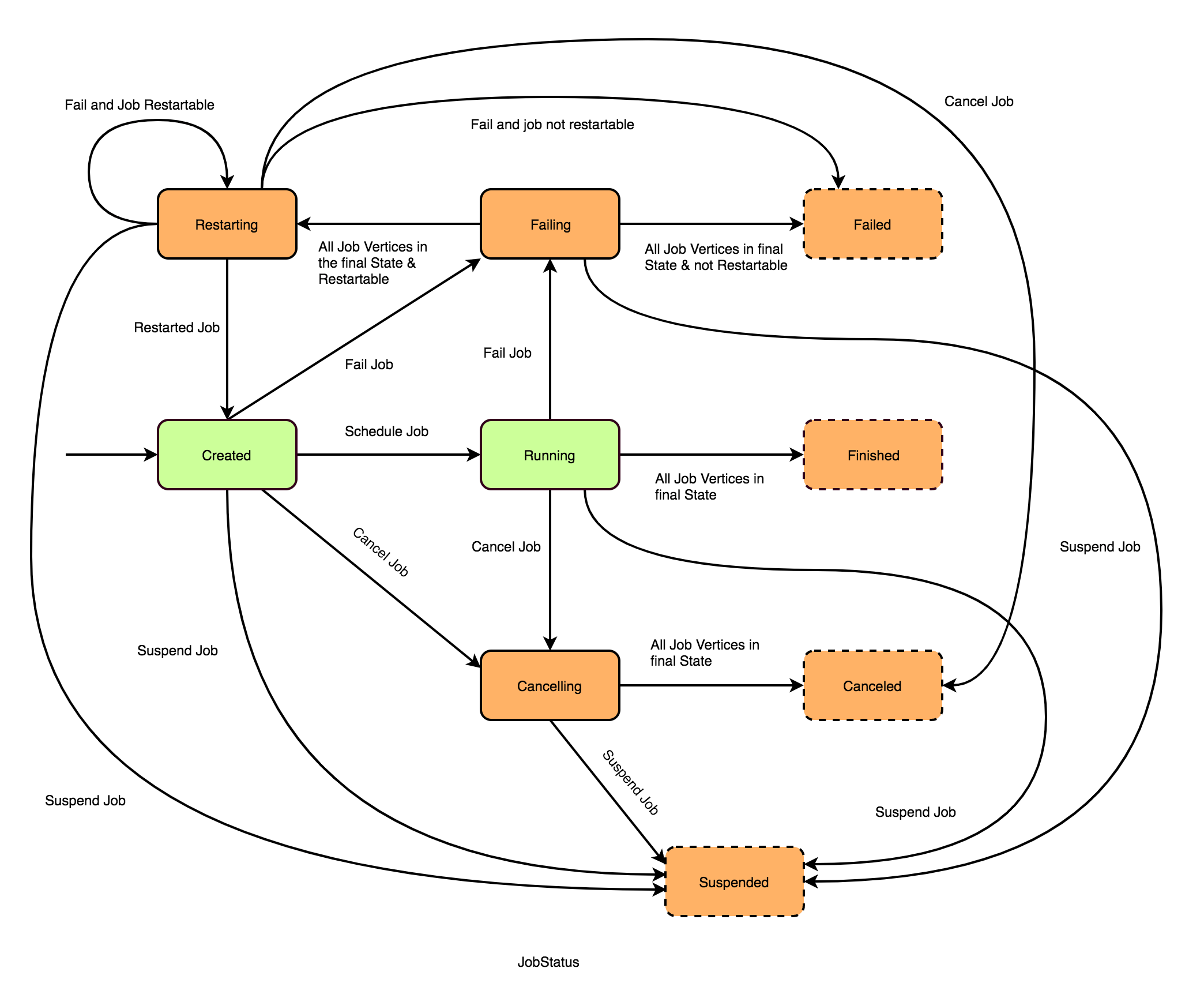
- 作业的状态:在 UI 上是可以看到作业的状态信息,常见的状态变更信息如下图。
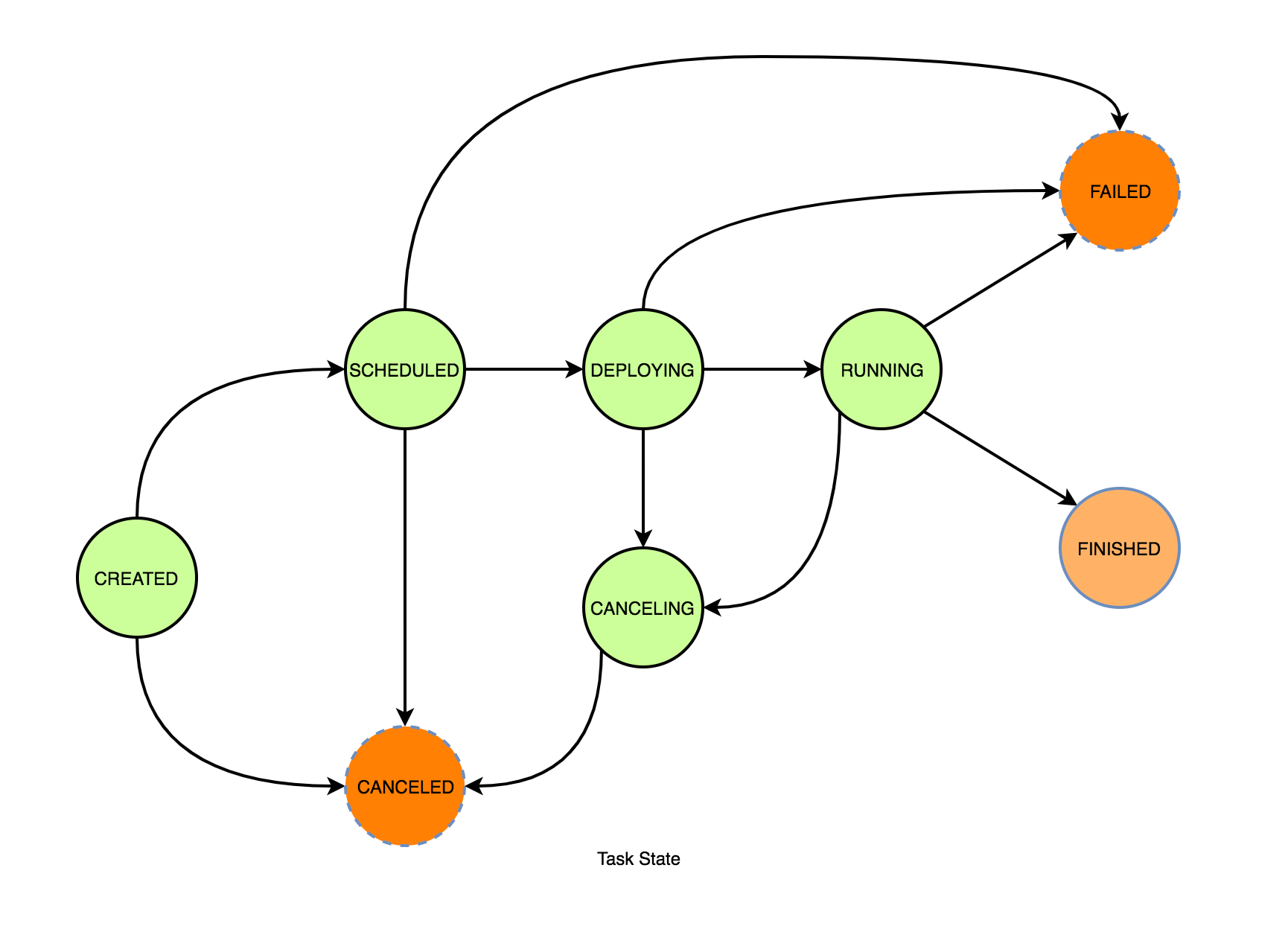
- Task 的状态:其实导致作业的状态发生变化的原因通常是由于 Task 的运行状态出现导致,所以也需要对 Task 的运行状态进行监控,Task 的运行状态如下图。
作业异常日志:导致 Task 出现状态异常的根因通常是作业中的代码出现各种各样的异常日志,最后可能还会导致作业无限重启,所以作业的异常日志也是需要及时关注。
作业重启次数:当 Task 状态和作业的状态发生变化的时候,如果作业中配置了重启策略或者开启了 Checkpoint 则会进行作业重启的,重启作业的带来的影响也会很多,并且会伴随着一些不确定的因素,最终导致作业一直重启,这样既不能解决问题,还一直在占用着资源的消耗。
算子的消费速度:代表了作业的消费能力,还可以知道作业是否发生延迟,可以包含算子接收的数据量和发出去数据量,从而可以知道在算子处是否有发生数据的丢失。
# 小结与反思
本节讲了 Flink 中常见的监控对象,比如 Job Manager、Task Manager 和 Flink Job,对于这几个分别介绍了其内部大概有的监控指标,以及在真实生产环境关心的指标,你是否还有其他的监控指标需要补充呢?
本节涉及的监控指标对应的含义可以参考官网链接:https://ci.apache.org/projects/flink/flink-docs- stable/monitoring/metrics.html#system-metrics
本节涉及的监控指标列表地址:https://github.com/zhisheng17/flink-learning/blob/master/flink- learning-monitor/flink monitor measurements.md