# Flink配置详解及如何配置高可用?
在讲解 7.2 节中如何部署 Flink 作业之前,希望能够再细讲下 Flink 中的配置,虽然在 2.2 节中简单讲解过。
# Flink 配置详解
# flink-conf.yaml
基础配置
# jobManager 的IP地址
jobmanager.rpc.address: localhost
# JobManager 的端口号
jobmanager.rpc.port: 6123
# JobManager JVM heap 内存大小
jobmanager.heap.size: 1024m
# TaskManager JVM heap 内存大小
taskmanager.heap.size: 1024m
# 每个 TaskManager 提供的任务 slots 数量大小
taskmanager.numberOfTaskSlots: 1
# 程序默认并行计算的个数
parallelism.default: 1
# 文件系统来源
# fs.default-scheme
高可用性配置
# 可以选择 'NONE' 或者 'zookeeper'.
# high-availability: zookeeper
# 文件系统路径,让 Flink 在高可用性设置中持久保存元数据
# high-availability.storageDir: hdfs:///flink/ha/
# zookeeper 集群中仲裁者的机器 ip 和 port 端口号
# high-availability.zookeeper.quorum: localhost:2181
# 默认是 open,如果 zookeeper security 启用了该值会更改成 creator
# high-availability.zookeeper.client.acl: open
容错和检查点配置
# 用于存储和检查点状态
# state.backend: filesystem
# 存储检查点的数据文件和元数据的默认目录
# state.checkpoints.dir: hdfs://namenode-host:port/flink-checkpoints
# savepoints 的默认目标目录(可选)
# state.savepoints.dir: hdfs://namenode-host:port/flink-checkpoints
# 用于启用/禁用增量 checkpoints 的标志
# state.backend.incremental: false
Web 前端配置
# 基于 Web 的运行时监视器侦听的地址.
#jobmanager.web.address: 0.0.0.0
# Web 的运行时监视器端口
rest.port: 8081
# 是否从基于 Web 的 jobmanager 启用作业提交
# jobmanager.web.submit.enable: false
高级配置
# io.tmp.dirs: /tmp
# 是否应在 TaskManager 启动时预先分配 TaskManager 管理的内存
# taskmanager.memory.preallocate: false
# 类加载解析顺序,是先检查用户代码 jar(“child-first”)还是应用程序类路径(“parent-first”)。 默认设置指示首先从用户代码 jar 加载类
# classloader.resolve-order: child-first
# 用于网络缓冲区的 JVM 内存的分数。 这决定了 TaskManager 可以同时拥有多少流数据交换通道以及通道缓冲的程度。 如果作业被拒绝或者您收到系统没有足够缓冲区的警告,请增加此值或下面的最小/最大值。 另请注意,“taskmanager.network.memory.min”和“taskmanager.network.memory.max”可能会覆盖此分数
# taskmanager.network.memory.fraction: 0.1
# taskmanager.network.memory.min: 67108864
# taskmanager.network.memory.max: 1073741824
Flink 集群安全配置
# 指示是否从 Kerberos ticket 缓存中读取
# security.kerberos.login.use-ticket-cache: true
# 包含用户凭据的 Kerberos 密钥表文件的绝对路径
# security.kerberos.login.keytab: /path/to/kerberos/keytab
# 与 keytab 关联的 Kerberos 主体名称
# security.kerberos.login.principal: flink-user
# 以逗号分隔的登录上下文列表,用于提供 Kerberos 凭据(例如,`Client,KafkaClient`使用凭证进行 ZooKeeper 身份验证和 Kafka 身份验证)
# security.kerberos.login.contexts: Client,KafkaClient
ZooKeeper 安全配置
# 覆盖以下配置以提供自定义 ZK 服务名称
# zookeeper.sasl.service-name: zookeeper
# 该配置必须匹配 "security.kerberos.login.contexts" 中的列表(含有一个)
# zookeeper.sasl.login-context-name: Client
HistoryServer
# 你可以通过 bin/historyserver.sh (start|stop) 命令启动和关闭 HistoryServer
# 将已完成的作业上传到的目录
# jobmanager.archive.fs.dir: hdfs:///completed-jobs/
# 基于 Web 的 HistoryServer 的地址
# historyserver.web.address: 0.0.0.0
# 基于 Web 的 HistoryServer 的端口号
# historyserver.web.port: 8082
# 以逗号分隔的目录列表,用于监视已完成的作业
# historyserver.archive.fs.dir: hdfs:///completed-jobs/
# 刷新受监控目录的时间间隔(以毫秒为单位)
# historyserver.archive.fs.refresh-interval: 10000
# masters
以 host:port 构成
localhost:8081
# slaves
里面是每个 worker 节点的 IP/Hostname,每一个 worker 结点之后都会运行一个 TaskManager,一个一行。
localhost
# Log 配置
在 Flink 的日志配置文件(logback.xml 或 log4j.properties)中有配置日志存储的地方,logback.xml
配置日志存储的路径是:
log4j.properties 和 log4j-cli.properties 的配置日志存储的路径是:
log4j.appender.file.file=${log.file}
从上面两个配置可以看到日志的路径都是由 log.file 变量控制的,如果系统变量没有配置的话,则会使用 bin/flink 脚本里配置的值。
log=$FLINK_LOG_DIR/flink-$FLINK_IDENT_STRING-client-$HOSTNAME.log
log_setting=(-Dlog.file="$log" -Dlog4j.configuration=file:"$FLINK_CONF_DIR"/log4j-cli.properties -Dlogback.configurationFile=file:"$FLINK_CONF_DIR"/logback.xml)
从上面可以看到 log 里配置的 FLINK LOG DIR 变量是在 bin 目录下的 config.sh 里初始化的。
DEFAULT_FLINK_LOG_DIR=$FLINK_HOME_DIR_MANGLED/log
KEY_ENV_LOG_DIR="env.log.dir"
if [ -z "${FLINK_LOG_DIR}" ]; then
FLINK_LOG_DIR=$(readFromConfig ${KEY_ENV_LOG_DIR} "${DEFAULT_FLINK_LOG_DIR}" "${YAML_CONF}")
fi
从上面可以知道日志默认就是在 Flink 的 log 目录下,你可以通过在 flink-conf.yaml 配置文件中配置 env.log.dir
参数来更改保存日志的目录。另外通过源码可以发现,如果找不到 log.file 环境变量,则会去找 web.log.path 的配置,但是该配置在
Standalone 下是不起作用的,日志依旧是会在 log 目录,在 YARN 下是会起作用的。
public static LogFileLocation find(Configuration config) {
final String logEnv = "log.file";
String logFilePath = System.getProperty(logEnv);
if (logFilePath == null) {
LOG.warn("Log file environment variable '{}' is not set.", logEnv);
logFilePath = config.getString(WebOptions.LOG_PATH); //该值为 web.log.path
}
// not configured, cannot serve log files
if (logFilePath == null || logFilePath.length() < 4) {
LOG.warn("JobManager log files are unavailable in the web dashboard. " +
"Log file location not found in environment variable '{}' or configuration key '{}'.",
logEnv, WebOptions.LOG_PATH);
return new LogFileLocation(null, null);
}
String outFilePath = logFilePath.substring(0, logFilePath.length() - 3).concat("out");
LOG.info("Determined location of main cluster component log file: {}", logFilePath);
LOG.info("Determined location of main cluster component stdout file: {}", outFilePath);
return new LogFileLocation(resolveFileLocation(logFilePath), resolveFileLocation(outFilePath));
}
/**
* The log file location (may be in /log for standalone but under log directory when using YARN).
*/
public static final ConfigOption<String> LOG_PATH =
key("web.log.path")
.noDefaultValue()
.withDeprecatedKeys("jobmanager.web.log.path")
.withDescription("Path to the log file (may be in /log for standalone but under log directory when using YARN).");
另外可能会在本地 IDE 中运行作业出不来日志的情况,这时请检查是否有添加日志的依赖。
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.25</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.25</version>
</dependency>
# 如何配置 JobManager 高可用?
JobManager 协调每个 Flink 作业的部署,它负责调度和资源管理。默认情况下,每个 Flink 集群只有一个 JobManager 实例,这样就可能会产生单点故障,如果 JobManager 崩溃,则无法提交新作业且运行中的作业也会失败。如果保证 JobManager 的高可用,则可以避免这个问题。下面分别下如何搭建 Standalone 集群和 YARN 集群高可用的 JobManager。
# 搭建 Standalone 集群高可用 JobManager
Standalone 集群的 JobManager 高可用性的概念是:任何时候只有一个主 JobManager 和多个备 JobManager,以便在主节点失败时有新的 JobManager 接管集群。这样就保证了没有单点故障,一旦备 JobManager 接管集群,作业就可以依旧正常运行。主备 JobManager 实例之间没有明确的区别,每个 JobManager 都可以充当主备节点。例如,请考虑以下三个 JobManager 实例的设置。
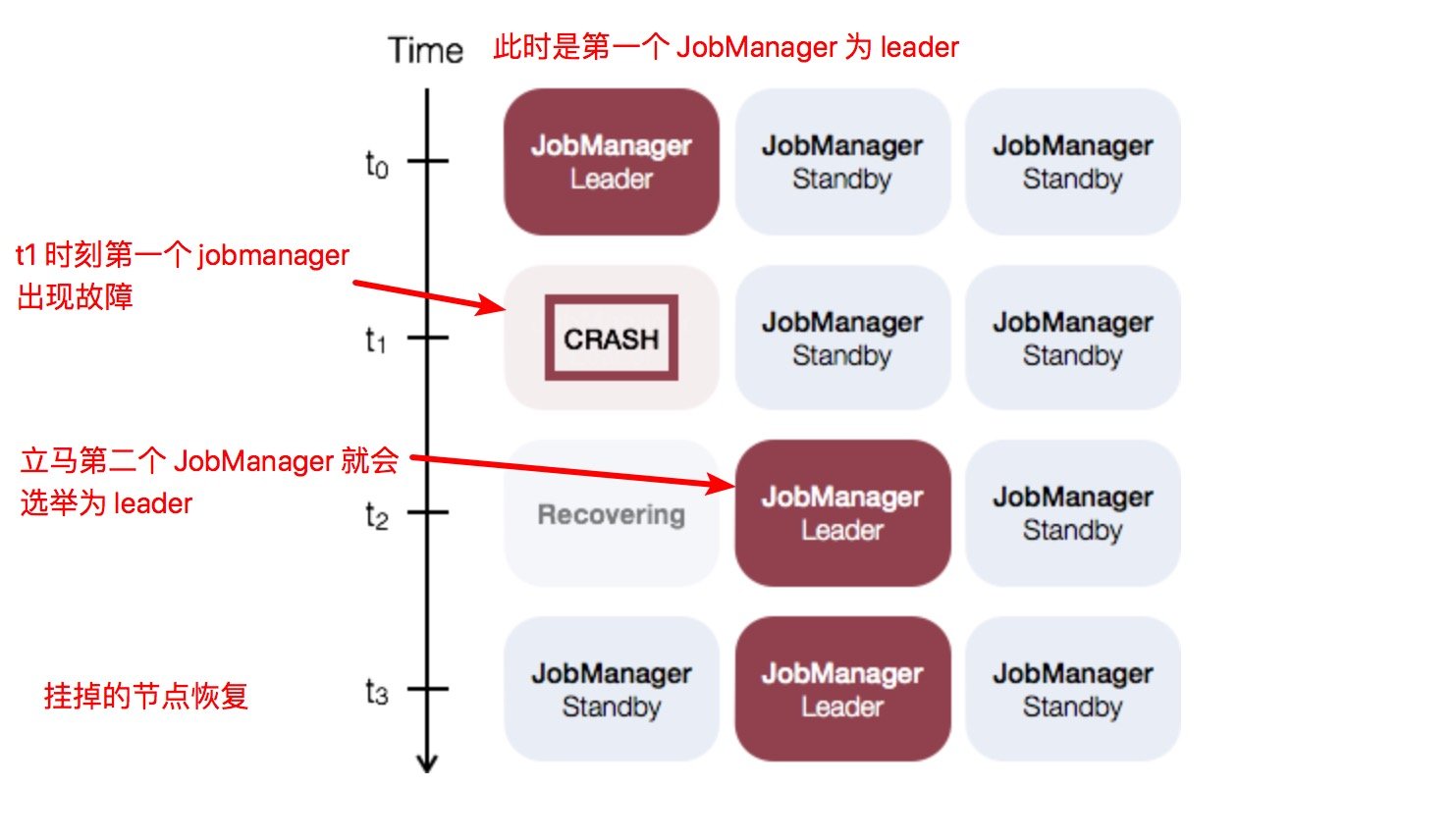 如何配置
如何配置
要启用 JobManager 高可用性功能,首先必须在配置文件 flink-conf.yaml 中将高可用性模式设置为 ZooKeeper,配置
ZooKeeper quorum,将所有 JobManager 主机及其 Web UI 端口写入配置文件。每个 ip:port 都是一个 ZooKeeper
服务器的 ip 及其端口,Flink 可以通过指定的地址和端口访问 ZooKeeper。另外就是高可用存储目录,JobManager 元数据保存在
high-availability.storageDir 指定的文件系统中,在 ZooKeeper 中仅保存了指向此状态的指针, 推荐这个目录是
HDFS、S3、Ceph、NFS 等,该文件系统中保存了 JobManager 恢复状态需要的所有元数据。
high-availability: zookeeper
high-availability.zookeeper.quorum: ip1:2181 [,...],ip2:2181
high-availability.storageDir: hdfs:///flink/ha/
Flink 利用 ZooKeeper 在所有正在运行的 JobManager 实例之间进行分布式协调。ZooKeeper 是独立于 Flink 的服务,通过 leader 选举和轻量级一致性状态存储提供高可靠的分布式协调服务。Flink 包含用于 Bootstrap ZooKeeper 安装的脚本。 它在我们的 Flink 安装路径下面 /conf/zoo.cfg 。
tickTime=2000
initLimit=10
syncLimit=5
# dataDir=/tmp/zookeeper
clientPort=2181
# ZooKeeper quorum peers
# 下面这个配置 ZK 地址
server.1=localhost:2888:3888
# server.2=host:peer-port:leader-port
要启动 HA 集群,请配置 masters 文件,该文件包含启动 JobManager 的所有主机以及 Web 用户界面绑定的端口,一行写一个。
localhost:8081
xxx.xxx.xxx.xxx:8081
默认情况下,JobManager 选一个随机端口作为进程通信端口,可以通过 high-availability.jobmanager.port
更改此设置。此配置接受单个端口(例如
50010),范围(50000-50025)或两者的组合(50010,50011,50020-50025,50050-50075)。
启动
配置好了之后的示例如下,假设是配置两个 JobManager 的 Standalone 的集群,在 flink-conf.yaml 中配置高可用模式和 Zookeeper 如下:
high-availability: zookeeper
high-availability.zookeeper.quorum: localhost:2181
high-availability.storageDir: hdfs:///flink/recovery
masters 中配置如下:
localhost:8081
localhost:8082
在 zoo.cfg 中配置 Zookeeper 服务如下:
server.0=localhost:2888:3888
启动 ZooKeeper 集群:
$ bin/start-zookeeper-quorum.sh
Starting zookeeper daemon on host localhost.
启动一个 Flink HA 集群:
$ bin/start-cluster.sh
Starting HA cluster with 2 masters and 1 peers in ZooKeeper quorum.
Starting jobmanager daemon on host localhost.
Starting jobmanager daemon on host localhost.
Starting taskmanager daemon on host localhost.
停止 ZooKeeper 和集群:
$ bin/stop-cluster.sh
Stopping taskmanager daemon (pid: 7647) on localhost.
Stopping jobmanager daemon (pid: 7495) on host localhost.
Stopping jobmanager daemon (pid: 7349) on host localhost.
$ bin/stop-zookeeper-quorum.sh
Stopping zookeeper daemon (pid: 7101) on host localhost.
# 搭建 YARN 集群高可用 JobManager
当在 YARN 上配置高可用的 JobManager 时,它只会运行一个 JobManager 实例,不会运行多个,该 JobManager 实例失败时,YARN 会将其重新启动。Yarn 的具体行为取决于使用的 YARN 版本。
如何配置
在 YARN 配置文件 yarn-site.xml 中,需要配置 application master 的最大重试次数:
当前 YARN 版本的默认值为 2(表示允许单个 JobManager 失败两次)。除了上面可以配置最大重试次数外,还可以在 flink-conf.yaml 配置如下:
yarn.application-attempts: 10
这意味着在如果程序启动失败,YARN 会再重试 9 次(9 次重试 + 1 次启动),如果启动 10 次作业还失败,YARN 才会将该任务的状态置为失败。如果因为节点硬件故障或重启,NodeManager 重新同步等操作,需要 YARN 继续尝试启动应用。这些重启尝试不计入 yarn.application-attempts 个数中。
容器关闭行为
- YARN 2.3.0 < 版本 < 2.4.0. 如果 application master 进程失败,则所有的 container 都会重启。
- YARN 2.4.0 < 版本 < 2.6.0. TaskManager container 在 application master 故障期间,会继续工作。这具有以下优点:作业恢复时间更快,且缩短所有 TaskManager 启动时申请资源的时间。
- YARN 2.6.0 <= version: 将尝试失败有效性间隔设置为 Flink 的 Akka 超时值。尝试失败有效性间隔表示只有在系统在一个间隔期间看到最大应用程序尝试次数后才会终止应用程序,这避免了持久的工作会耗尽它的应用程序尝试。
启动
配置好了的示例如下,首先在 flink-conf.yaml 配置 HA 模式和 Zookeeper 集群:
high-availability: zookeeper
high-availability.zookeeper.quorum: localhost:2181
yarn.application-attempts: 10
在 zoo.cfg 配置 ZooKeeper 服务:
server.0=localhost:2888:3888
启动 Zookeeper 集群:
$ bin/start-zookeeper-quorum.sh
Starting zookeeper daemon on host localhost.
启动 HA 集群:
$ bin/yarn-session.sh -n 2
# 小结与反思
本节一开始对 Flink 的所有配置文件做了一个详细的介绍,分析了每种配置的作用和使用场景,然后介绍了 Flink 中的日志配置,最后讲解了下 JobManager 的高可用配置。