# FlinkWordCount应用程序
在 2.2 中带大家讲解了下 Flink 的环境安装,这篇文章就开始我们的第一个 Flink 案例实战,也方便大家快速开始自己的第一个 Flink 应用。大数据里学习一门技术一般都是从 WordCount 开始入门的,那么我还是不打破常规了,所以这篇文章我也将带大家通过 WordCount 程序来初步了解 Flink。
# Maven 创建项目
Flink 支持 Maven 直接构建模版项目,你在终端使用该命令:
mvn archetype:generate
-DarchetypeGroupId=org.apache.flink
-DarchetypeArtifactId=flink-quickstart-java
-DarchetypeVersion=1.9.0
在执行的过程中它会提示你输入 groupId、artifactId、和 package 名,你按照要求输入就行,最后就可以成功创建一个项目。
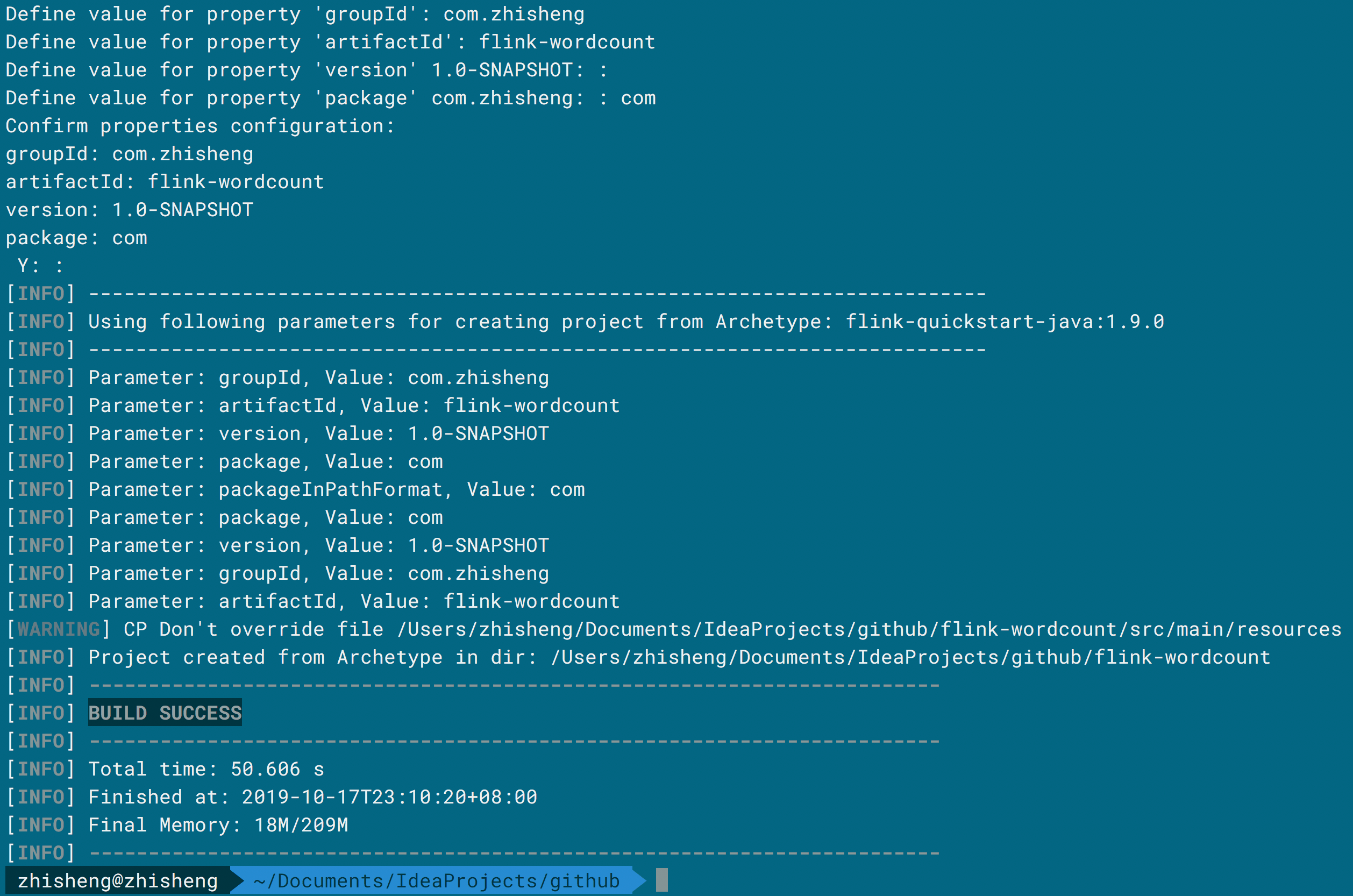 进入到目录你就可以看到已经创建了项目,里面结构如下:
进入到目录你就可以看到已经创建了项目,里面结构如下:
zhisheng@zhisheng ~/IdeaProjects/github/Flink-WordCount tree
.
├── pom.xml
└── src
└── main
├── java
│ └── com
│ └── zhisheng
│ ├── BatchJob.java
│ └── StreamingJob.java
└── resources
└── log4j.properties
6 directories, 4 files
该项目中包含了两个类 BatchJob 和 StreamingJob,另外还有一个 log4j.properties 配置文件,然后你就可以将该项目导入到 IDEA 了。
你可以在该目录下执行 mvn clean package 就可以编译该项目,编译成功后在 target 目录下会生成一个 Job 的 Jar
包,但是这个 Job 还不能执行,因为 StreamingJob 这个类中的 main 方法里面只是简单的创建了
StreamExecutionEnvironment 环境,然后就执行 execute 方法,这在 Flink 中是不算一个可执行的 Job
的,因此如果你提交到 Flink UI 上也是会报错的。
上传 Jar:
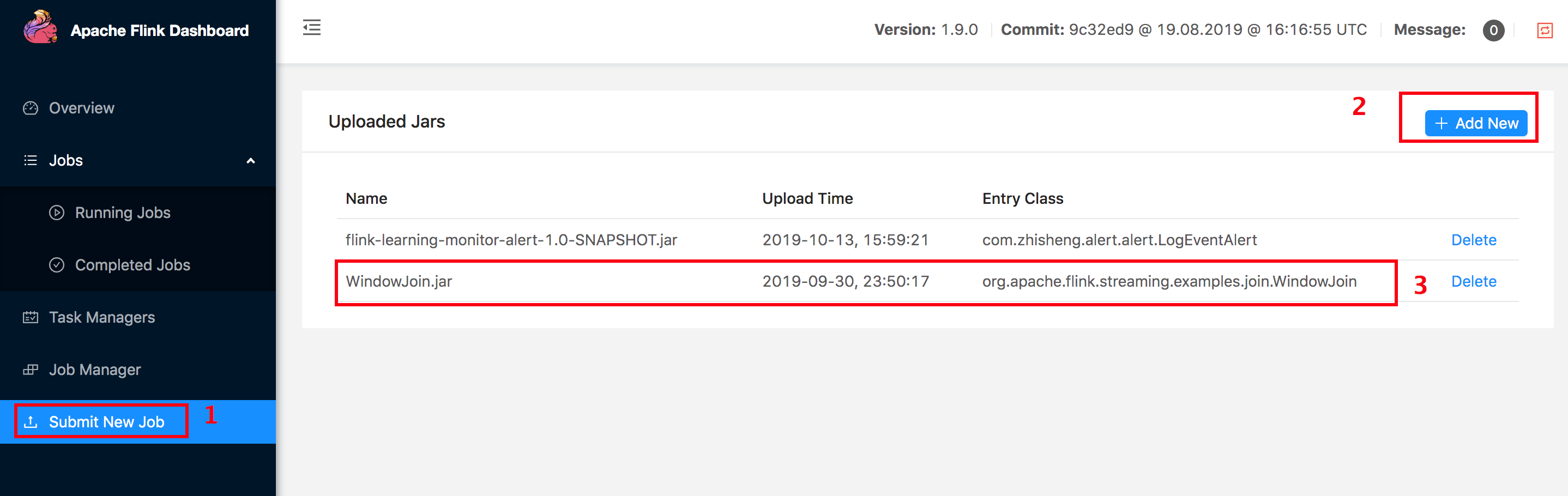 运行报错:
运行报错:
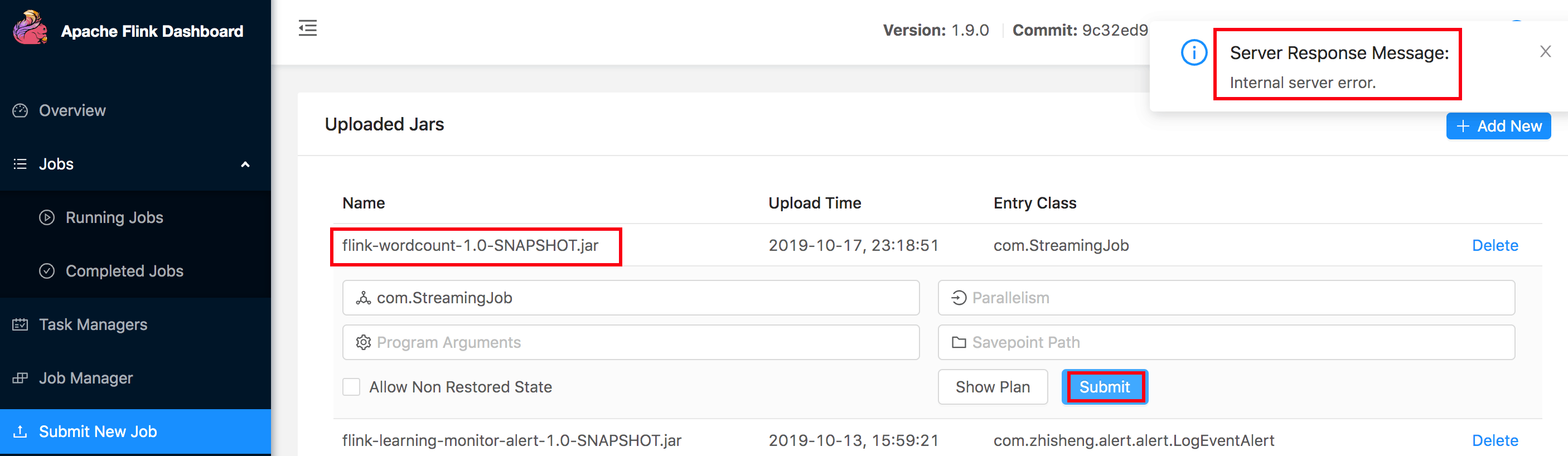
Server Response Message:
Internal server error.
我们查看 Flink Job Manager 的日志可以看到:
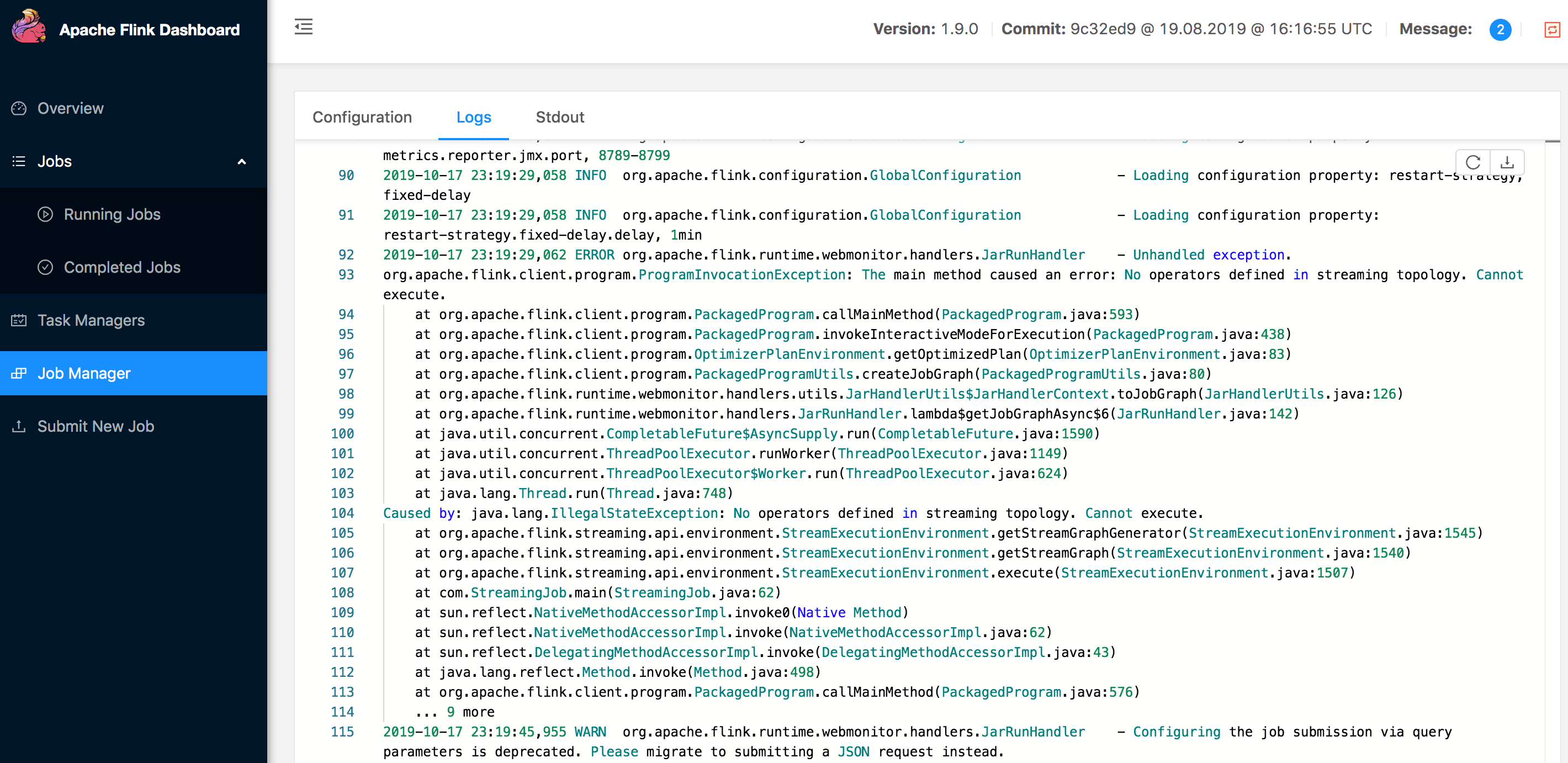
2019-04-26 17:27:33,706 ERROR org.apache.flink.runtime.webmonitor.handlers.JarRunHandler - Unhandled exception.
org.apache.flink.client.program.ProgramInvocationException: The main method caused an error: No operators defined in streaming topology. Cannot execute.
因为 execute 方法之前我们是需要补充我们 Job 的一些算子操作的,所以报错还是很正常的,本文下面将会提供完整代码。
# IDEA 创建项目
一般我们项目可能是由多个 Job 组成,并且代码也都是在同一个工程下面进行管理,上面那种适合单个 Job 执行,但如果多人合作的时候还是得在同一个工程下面进行项目的创建,每个 Flink Job 一个 module,下面我们将来讲解下如何利用 IDEA 创建 Flink 项目。
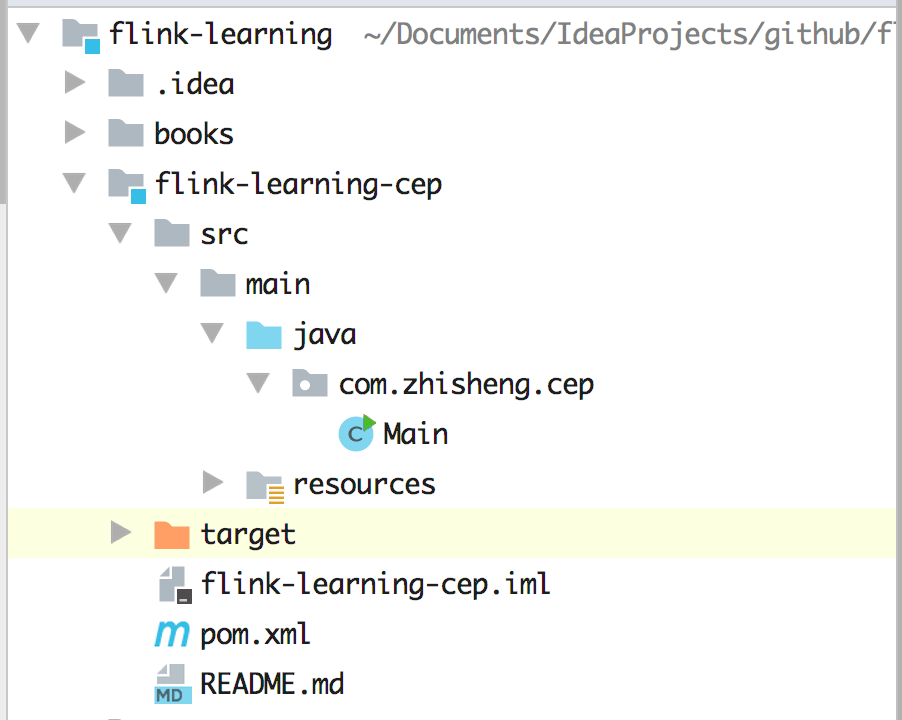
我们利用 IDEA 创建 Maven 项目,工程如下图这样,项目下面分很多模块,每个模块负责不同的业务
 接下来我们需要在父工程的 pom.xml 中加入如下属性(含编码、Flink 版本、JDK 版本、Scala 版本、Maven 编译版本):
接下来我们需要在父工程的 pom.xml 中加入如下属性(含编码、Flink 版本、JDK 版本、Scala 版本、Maven 编译版本):
```properties
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<!--Flink 版本-->
<flink.version>1.9.0</flink.version>
<!--JDK 版本-->
<java.version>1.8</java.version>
<!--Scala 2.11 版本-->
<scala.binary.version>2.11</scala.binary.version>
<maven.compiler.source>${java.version}</maven.compiler.source>
<maven.compiler.target>${java.version}</maven.compiler.target>
</properties>
```
然后加入依赖:
```xml
<dependencies>
<!-- Apache Flink dependencies -->
<!-- These dependencies are provided, because they should not be packaged into the JAR file. -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<!-- Add logging framework, to produce console output when running in the IDE. -->
<!-- These dependencies are excluded from the application JAR by default. -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.7</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
<scope>runtime</scope>
</dependency>
</dependencies>
```
上面依赖中 flink-java 和 flink-streaming-java 是我们 Flink 必备的核心依赖,为什么设置 scope 为 provided 呢(默认是 compile)?
是因为 Flink 其实在自己的安装目录中 lib 文件夹里的 lib/flink-dist_2.11-1.9.0.jar 已经包含了这些必备的 Jar
了,所以我们在给自己的 Flink Job 添加依赖的时候最后打成的 Jar 包可不希望又将这些重复的依赖打进去。有两个好处:
- 减小了我们打的 Flink Job Jar 包容量大小
- 不会因为打入不同版本的 Flink 核心依赖而导致类加载冲突等问题
但是问题又来了,我们需要在 IDEA 中调试运行我们的 Job,如果将 scope 设置为 provided 的话,是会报错的:
Error: A JNI error has occurred, please check your installation and try again
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/flink/api/common/ExecutionConfig$GlobalJobParameters
at java.lang.Class.getDeclaredMethods0(Native Method)
at java.lang.Class.privateGetDeclaredMethods(Class.java:2701)
at java.lang.Class.privateGetMethodRecursive(Class.java:3048)
at java.lang.Class.getMethod0(Class.java:3018)
at java.lang.Class.getMethod(Class.java:1784)
at sun.launcher.LauncherHelper.validateMainClass(LauncherHelper.java:544)
at sun.launcher.LauncherHelper.checkAndLoadMain(LauncherHelper.java:526)
Caused by: java.lang.ClassNotFoundException: org.apache.flink.api.common.ExecutionConfig$GlobalJobParameters
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:338)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 7 more
默认 scope 为 compile 的话,本地调试的话就不会出错了。
另外测试到底能够减小多少 Jar 包的大小呢?我这里先写了个 Job 测试。
当 scope 为 compile 时,编译后的 target 目录:
zhisheng@zhisheng ~/Flink-WordCount/target master ●✚ ll
total 94384
-rw-r--r-- 1 zhisheng staff 45M 4 26 21:23 Flink-WordCount-1.0-SNAPSHOT.jar
drwxr-xr-x 4 zhisheng staff 128B 4 26 21:23 classes
drwxr-xr-x 3 zhisheng staff 96B 4 26 21:23 generated-sources
drwxr-xr-x 3 zhisheng staff 96B 4 26 21:23 maven-archiver
drwxr-xr-x 3 zhisheng staff 96B 4 26 21:23 maven-status
-rw-r--r-- 1 zhisheng staff 7.2K 4 26 21:23 original-Flink-WordCount-1.0-SNAPSHOT.jar
当 scope 为 provided 时,编译后的 target 目录:
zhisheng@zhisheng ~/Flink-WordCount/target master ●✚ ll
total 32
-rw-r--r-- 1 zhisheng staff 7.5K 4 26 21:27 Flink-WordCount-1.0-SNAPSHOT.jar
drwxr-xr-x 4 zhisheng staff 128B 4 26 21:27 classes
drwxr-xr-x 3 zhisheng staff 96B 4 26 21:27 generated-sources
drwxr-xr-x 3 zhisheng staff 96B 4 26 21:27 maven-archiver
drwxr-xr-x 3 zhisheng staff 96B 4 26 21:27 maven-status
-rw-r--r-- 1 zhisheng staff 7.2K 4 26 21:27 original-Flink-WordCount-1.0-SNAPSHOT.jar
可以发现:当 scope 为 provided 时 Jar 包才 7.5k,而为 compile 时 Jar 包就 45M 了,你要想想这才只是一个简单的 WordCount 程序呢,差别就这么大。当我们把 Flink Job 打成一个 fat Jar 时,上传到 UI 的时间就能够很明显的对比出来(Jar 包越小上传的时间越短),所以把 scope 设置为 provided 还是很有必要的。
有人就会想了,那这不是和上面有冲突了吗?假如我既想打出来的 Jar 包要小,又想能够在本地 IDEA 中进行运行和调试 Job ?这里我提供一种方法:在父工程中的 pom.xml 引入如下 profiles。
<profiles>
<profile>
<id>add-dependencies-for-IDEA</id>
<activation>
<property>
<name>idea.version</name>
</property>
</activation>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>compile</scope>
</dependency>
</dependencies>
</profile>
</profiles>
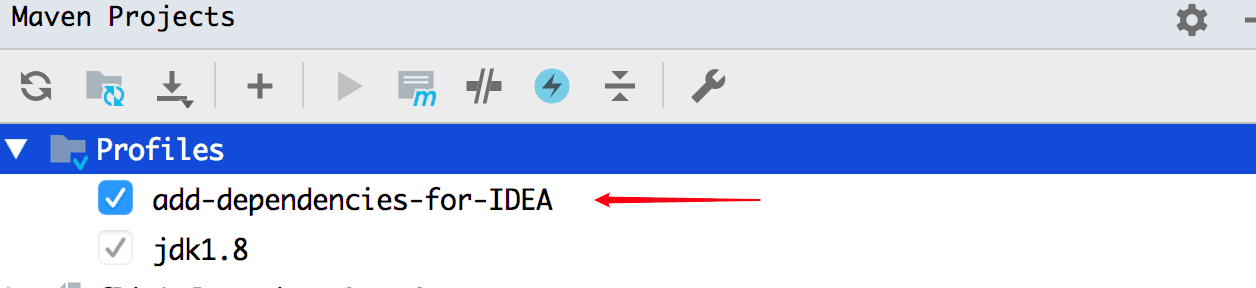
当你在 IDEA 中运行 Job 的时候,它会给你引入 flink-java、flink-streaming-java,且 scope 设置为 compile,但是你是打成 Jar 包的时候它又不起作用。如果你加了这个 profile 还是报错的话,那么可能是 IDEA 中没有识别到,你可以在 IDEA 的中查看下面两个配置确定一下(配置其中一个即可以起作用)。
1、查看 Maven 中的该 profile 是否已经默认勾选上了,如果没有勾选上,则手动勾选一下才会起作用
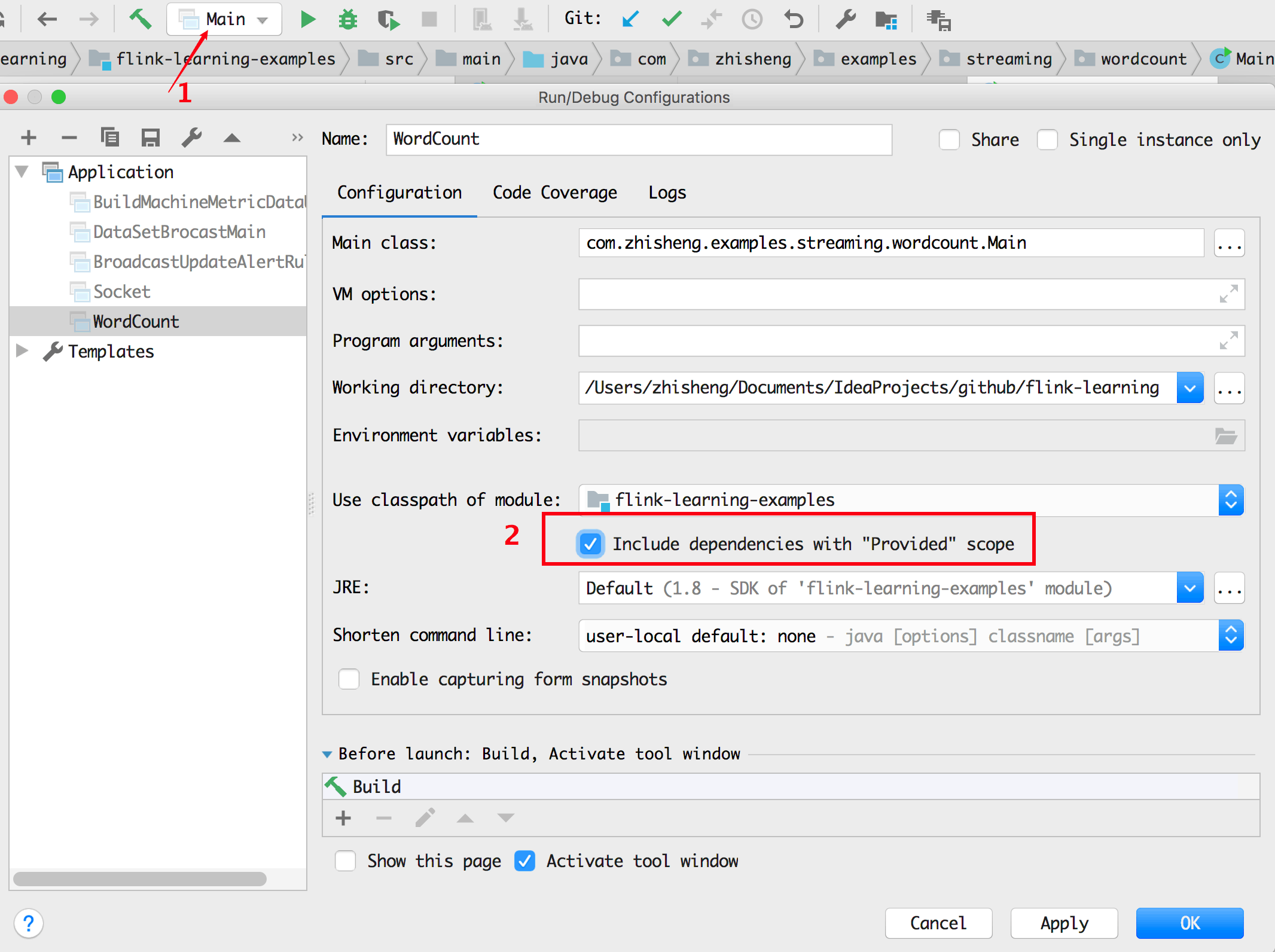
 2、Include dependencies with "Provided" scope 是否勾选,如果未勾选,则手动勾选后才起作用
2、Include dependencies with "Provided" scope 是否勾选,如果未勾选,则手动勾选后才起作用
# 流计算 WordCount 应用程序代码
回到正题,利用 IDEA 创建好 WordCount 应用后,我们开始编写代码。
Main 类 :
public class Main {
public static void main(String[] args) throws Exception {
//创建流运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.getConfig().setGlobalJobParameters(ParameterTool.fromArgs(args));
env.fromElements(WORDS)
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] splits = value.toLowerCase().split("\\W+");
for (String split : splits) {
if (split.length() > 0) {
out.collect(new Tuple2<>(split, 1));
}
}
}
})
.keyBy(0)
.reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {
return new Tuple2<>(value1.f0, value1.f1 + value1.f1);
}
})
.print();
//Streaming 程序必须加这个才能启动程序,否则不会有结果
env.execute("zhisheng —— word count streaming demo");
}
private static final String[] WORDS = new String[]{
"To be, or not to be,--that is the question:--",
"Whether 'tis nobler in the mind to suffer"
};
}
pom.xml 文件中引入 build 插件并且要替换成你自己项目里面的 mainClass:
<build>
<plugins>
<!-- Java Compiler -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
</configuration>
</plugin>
<!-- 使用 maven-shade 插件创建一个包含所有必要的依赖项的 fat Jar -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.0.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>org.apache.flink:force-shading</exclude>
<exclude>com.google.code.findbugs:jsr305</exclude>
<exclude>org.slf4j:*</exclude>
<exclude>log4j:*</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<!--注意:这里一定要换成你自己的 Job main 方法的启动类-->
<mainClass>com.zhisheng.wordcount.Main</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
注意:上面这个 build 插件要记得加,否则打出来的 jar 包是不完整的,提交运行会报 ClassNotFoundException,该问题是初学者很容易遇到的问题,很多人咨询过笔者这个问题。
# WordCount 应用程序运行
# 本地 IDE 运行
编译好 WordCount 程序后,我们在 IDEA 中右键 run main 方法就可以把 Job 运行起来,结果如下图:
 图中的就是将每个 word 和对应的个数一行一行打印出来,在本地 IDEA 中运行没有问题,我们接下来使用命令
图中的就是将每个 word 和对应的个数一行一行打印出来,在本地 IDEA 中运行没有问题,我们接下来使用命令 mvn clean package
打包成一个 Jar (flink-learning-examples-1.0-SNAPSHOT.jar) 然后将其上传到 Flink UI
上运行一下看下效果。
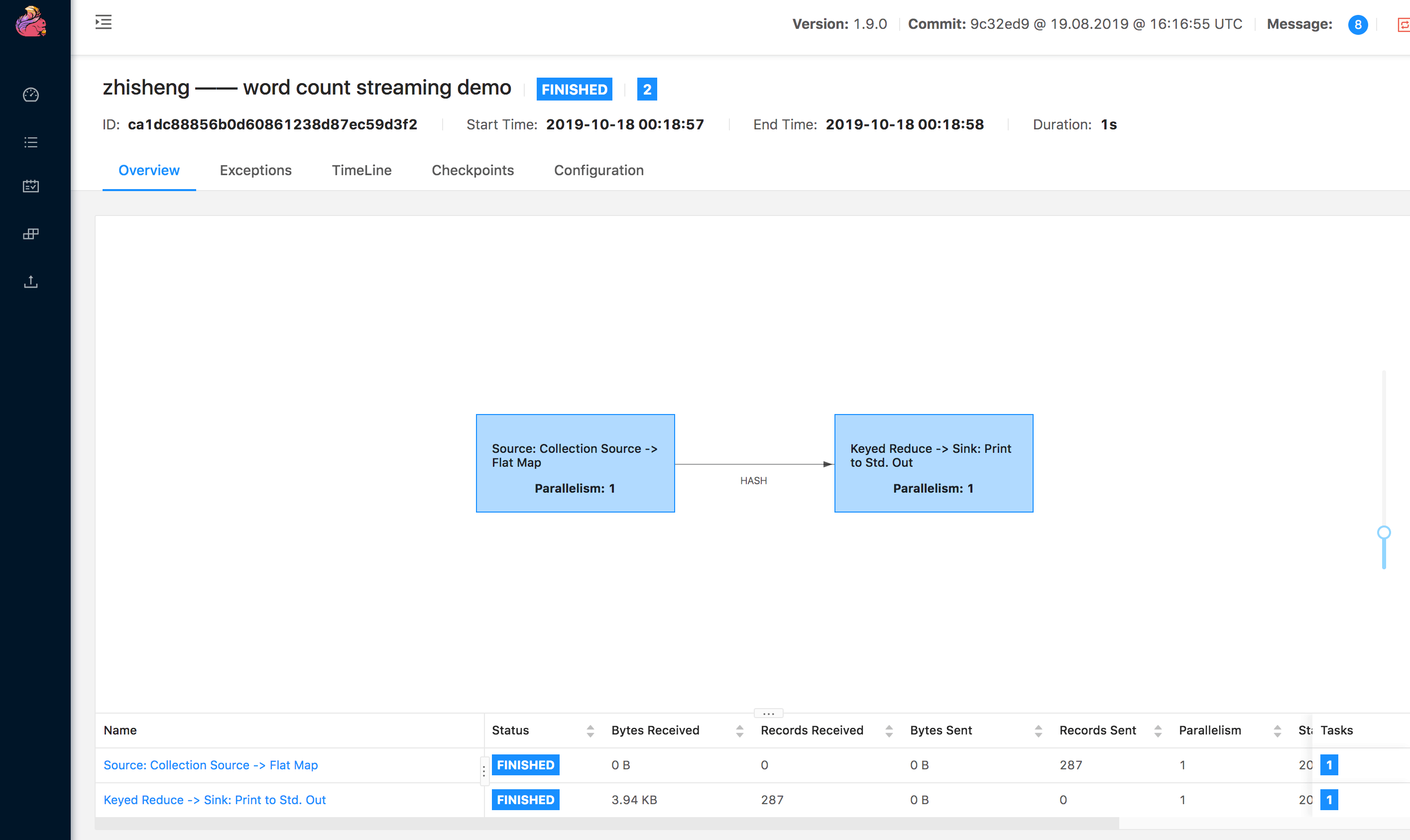
# UI 运行 Job
在 http://localhost:8081/#/submit 页面上传 flink-learning-
examples-1.0-SNAPSHOT.jar 后,然后点击 Submit 后就可以运行了。
运行 Job 的 UI 如下:
 Job 的结果在 Task Manager 的 Stdout 中:
Job 的结果在 Task Manager 的 Stdout 中:
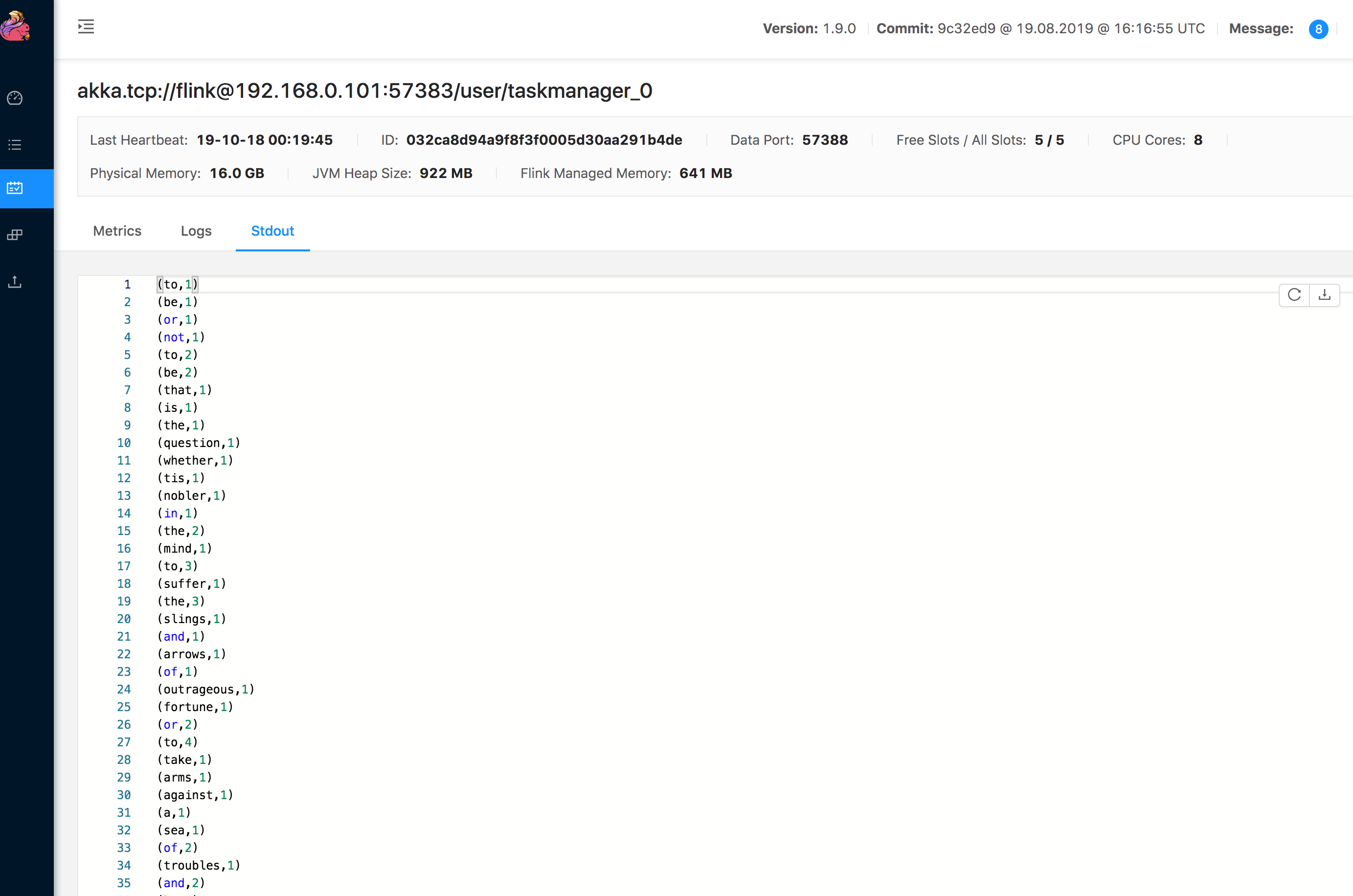
# WordCount 应用程序代码分析
我们已经将 WordCount 程序代码写好了并且也在 IDEA 中和 Flink UI 上运行了 Job,并且程序运行的结果都是正常的。
那么我们来分析一下这个 WordCount 程序代码:
1、创建好 StreamExecutionEnvironment(流程序的运行环境)
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
2、给流程序的运行环境设置全局的配置(从参数 args 获取)
env.getConfig().setGlobalJobParameters(ParameterTool.fromArgs(args));
3、构建数据源,WORDS 是个字符串数组
env.fromElements(WORDS)
4、将字符串进行分隔然后收集,组装后的数据格式是 (word、1),1 代表 word 出现的次数为 1
flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] splits = value.toLowerCase().split("\\W+");
for (String split : splits) {
if (split.length() > 0) {
out.collect(new Tuple2<>(split, 1));
}
}
}
})
5、根据 word 关键字进行分组(0 代表对第一个字段分组,也就是对 word 进行分组)
keyBy(0)
6、对单个 word 进行计数操作
reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {
return new Tuple2<>(value1.f0, value1.f1 + value2.f1);
}
})
7、打印所有的数据流,格式是 (word,count),count 代表 word 出现的次数
print()
8、开始执行 Job
env.execute("zhisheng —— word count streaming demo");
# 小结与反思
本节给大家介绍了 Maven 创建 Flink Job、IDEA 中创建 Flink 项目(详细描述了里面要注意的事情)、编写 WordCount 程序、IDEA 运行程序、在 Flink UI 运行程序、对 WordCount 程序每个步骤进行分析。
通过本小节,你接触了第一个 Flink 应用程序,也开启了 Flink 实战之旅。你有自己运行本节的代码去测试吗?动手测试的过程中有遇到什么问题吗?
本节涉及的代码地址:https://github.com/zhisheng17/flink-learning/tree/master/flink- learning-examples/src/main/java/com/zhisheng/examples/streaming/wordcount